Regressione logistica Intuizione ed Implementazione
Regressione logistica
La matematica dietro l’algoritmo di regressione logistica e l’implementazione da zero utilizzando Numpy.
Introduzione
La regressione logistica è un algoritmo fondamentale di classificazione binaria che può apprendere un confine decisionale tra due diversi insiemi di attributi dei dati. In questo articolo, comprendiamo l’aspetto teorico dietro il modello di classificazione e lo implementiamo utilizzando Python.
Intuizione
Dataset
La regressione logistica è un algoritmo di apprendimento supervisionato, quindi abbiamo attributi di caratteristiche dei dati e le loro etichette corrispondenti. Le caratteristiche sono variabili indipendenti, indicate con X, e sono rappresentate in un array unidimensionale. Le etichette di classe, indicate con y, sono 0 o 1. Pertanto, la regressione logistica è un algoritmo di classificazione binaria.
Se i dati hanno d-caratteristiche:
- Ricercatori dell’UC Santa Cruz e Samsung presentano ESC un agente di navigazione degli oggetti senza training che utilizza il senso comune nelle LLM come ChatGPT per le decisioni di navigazione.
- Tutorial sull’IA Come lanciare l’app di chat IA su Streamlit utilizzando Open AI e GitHub
- Incontra CLAMP un nuovo strumento AI per la previsione dell’attività molecolare che può adattarsi a nuovi esperimenti durante il tempo di inferenza
Funzione di costo
Similmente alla regressione lineare, abbiamo pesi associati alle caratteristiche degli attributi e un valore di bias.
Il nostro obiettivo è trovare i valori ottimali per i pesi e il bias, per adattare meglio i nostri dati.
Abbiamo un valore di peso associato a ciascuna caratteristica dell’attributo e un singolo valore di bias.
Iniziamo casualmente questi valori e li ottimizziamo utilizzando la discesa del gradiente. Durante l’addestramento, facciamo il prodotto scalare tra i pesi e le caratteristiche e aggiungiamo il termine di bias.
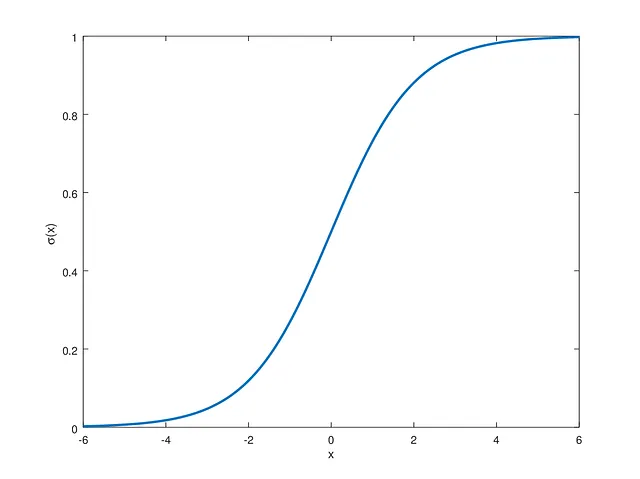
Ma poiché le nostre etichette target sono 0 e 1, utilizziamo una funzione sigmoide non lineare, rappresentata da g, che spinge i nostri valori nell’intervallo richiesto.
La funzione sigmoide tracciata è la seguente:
La regressione logistica mira a imparare pesi e bias in modo che i valori passati alla funzione sigmoide siano positivi per le etichette positive e negativi per le etichette negative.
Per prevedere valori nella regressione logistica, passiamo le nostre previsioni alla funzione sigmoide. Quindi, la funzione di previsione è:
Ora che abbiamo previsioni dal nostro modello, possiamo confrontarle con le etichette target originali. L’errore tra le previsioni viene calcolato utilizzando la Binary Cross Entropy Loss. La funzione di perdita è la seguente:
dove y è l’etichetta target originale e p è il valore previsto compreso tra [0,1]. La funzione di perdita mira a spingere i valori previsti verso le etichette target effettive. Se l’etichetta è 0 e il modello prevede 0, la perdita è 0. Allo stesso modo, se sia le etichette previste che quelle target sono 1, la perdita è 0. In caso contrario, il modello cerca di convergere verso questi valori.
Discesa del gradiente
Utilizziamo la funzione di costo e otteniamo la derivata rispetto ai pesi e al bias. Utilizzando la regola della catena e la derivazione matematica, le derivate sono le seguenti:
Otteniamo un valore scalare che possiamo utilizzare per aggiornare i pesi e i bias.
Questo aggiorna i valori rispetto al gradiente della perdita, quindi dopo diverse iterazioni, convergiamo gradualmente verso i valori ottimali dei pesi e dei bias.
Durante l’inferenza, possiamo quindi utilizzare i valori dei pesi e dei bias per ottenere le previsioni.
Implementazione
Utilizziamo le formule matematiche sopra menzionate per codificare il modello di regressione logistica e valuteremo le sue prestazioni su alcuni dataset di riferimento.
Innanzitutto, inizializziamo la classe e i parametri.
class LogisticRegression(): def __init__( self, learning_rate:float=0.001, n_iters:int=10000 ) -> None: self.n_iters = n_iters self.lr = learning_rate self.weights = None self.bias = NoneServono i valori dei pesi e dei bias che verranno ottimizzati, quindi li inizializziamo qui come attributi dell’oggetto. Tuttavia, non possiamo impostare la dimensione qui poiché dipende dai dati passati durante l’addestramento. Pertanto, li impostiamo per il momento a None. Il tasso di apprendimento e il numero di iterazioni sono iperparametri che possono essere regolati per le prestazioni.
Addestramento
def fit( self, X : np.ndarray, y : np.ndarray ): n_samples, n_features = X.shape # Inizializziamo Pesi e Bias con Valori Casuali # La dimensione della matrice dei pesi è basata sul numero di caratteristiche dei dati # Il bias è un valore scalare self.weights = np.random.rand(n_features) self.bias = 0 for iteration in range(self.n_iters): # Otteniamo le previsioni dal Modello linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) loss = predictions - y # Gradiente Discendente basato sulla Perdita dw = (1 / n_samples) * np.dot(X.T, loss) db = (1 / n_samples) * np.sum(loss) # Aggiorniamo i Parametri del Modello self.weights = self.weights - self.lr * dw self.bias = self.bias - self.lr * dbLa funzione di addestramento inizializza i valori dei pesi e del bias. Successivamente, iteriamo sul dataset più volte, ottimizzando questi valori verso la convergenza, in modo che la perdita si minimizzi.
Sulla base delle equazioni sopra, la funzione sigmoide è implementata come segue:
def sigmoid(x): return 1 / (1 + np.exp(-x))Usiamo quindi questa funzione per generare previsioni utilizzando:
linear_pred = np.dot(X, self.weights) + self.biaspredictions = sigmoid(linear_pred)Calcoliamo la perdita su questi valori e ottimizziamo i pesi:
loss = predictions - y # Gradiente Discendente basato sulla Perditadw = (1 / n_samples) * np.dot(X.T, loss)db = (1 / n_samples) * np.sum(loss)# Aggiorniamo i Parametri del Modelloself.weights = self.weights - self.lr * dwself.bias = self.bias - self.lr * dbInferenza
def predict( self, X : np.ndarray, threshold:float=0.5 ): linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) # Convertiamo in Etichetta 0 o 1 y_pred = [0 if y <= threshold else 1 for y in predictions] return y_predUna volta adattati i nostri dati durante l’addestramento, possiamo utilizzare i pesi e il bias appresi per generare previsioni in modo simile. L’output del modello è nell’intervallo [0, 1], come la funzione sigmoide. Quindi possiamo utilizzare un valore di soglia come 0.5. Tutti i valori superiori a questa probabilità vengono etichettati come etichette positive e tutti i valori inferiori a questa soglia vengono etichettati come etichette negative.
Codice Completo
import numpy as npdef sigmoid(x): return 1 / (1 + np.exp(-x))class LogisticRegression(): def __init__( self, learning_rate:float=0.001, n_iters:int=10000 ) -> None: self.n_iters = n_iters self.lr = learning_rate self.weights = None self.bias = None def fit( self, X : np.ndarray, y : np.ndarray ): n_samples, n_features = X.shape # Inizializziamo Pesi e Bias con Valori Casuali # La dimensione della matrice dei pesi è basata sul numero di caratteristiche dei dati # Il bias è un valore scalare self.weights = np.random.rand(n_features) self.bias = 0 for iteration in range(self.n_iters): # Otteniamo le previsioni dal Modello linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) loss = predictions - y # Gradiente Discendente basato sulla Perdita dw = (1 / n_samples) * np.dot(X.T, loss) db = (1 / n_samples) * np.sum(loss) # Aggiorniamo i Parametri del Modello self.weights = self.weights - self.lr * dw self.bias = self.bias - self.lr * db def predict( self, X : np.ndarray, threshold:float=0.5 ): linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) # Convertiamo in Etichetta 0 o 1 y_pred = [0 if y <= threshold else 1 for y in predictions] return y_predValutazione
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfrom sklearn.metrics import accuracy_scorefrom model import LogisticRegressionif __name__ == "__main__": data = load_breast_cancer() X, y = data.data, data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True) model = LogisticRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) score = accuracy_score(y_pred, y_test) print(score)Possiamo utilizzare lo script sopra per testare il nostro modello di regressione logistica. Utilizziamo il dataset del cancro al seno di Scikit-Learn per l’addestramento. Possiamo poi confrontare le nostre previsioni con le etichette originali.
Facendo attenzione a regolare alcuni degli iperparametri, ho ottenuto un punteggio di accuratezza superiore al 90%.
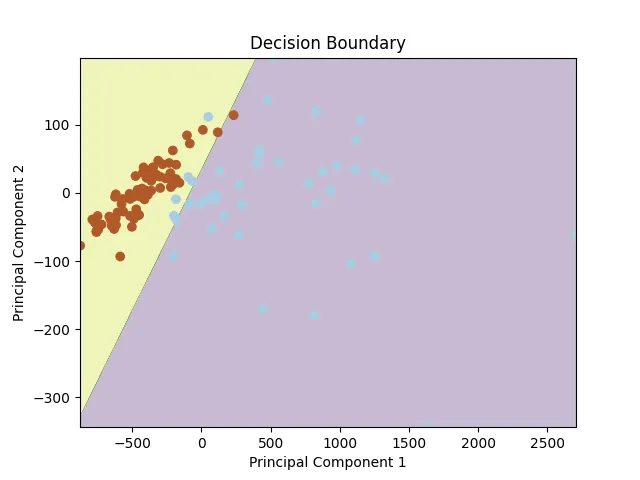
Possiamo utilizzare diverse tecniche di riduzione della dimensionalità, come l’PCA, per visualizzare il confine decisionale. Dopo aver ridotto le nostre caratteristiche a due dimensioni, otteniamo il seguente confine decisionale.
Conclusione
In conclusione, questo articolo ha esplorato l’intuizione matematica della regressione logistica e ne ha dimostrato l’implementazione utilizzando NumPy. La regressione logistica è un algoritmo di classificazione prezioso che utilizza la funzione sigmoide e la discesa del gradiente per trovare un confine decisionale ottimale per la classificazione binaria.
Per il codice e l’implementazione, fare riferimento a questo repository GitHub. Seguimi per ulteriori articoli sulle architetture di deep learning e gli avanzamenti della ricerca.




