Raccolta dati in primo piano i modelli di linguaggio stanno oltrepassando il limite allenandosi su tutti i contenuti?
La raccolta dati dei modelli di linguaggio supera i limiti allenandosi su tutti i contenuti?
Mentre i modelli abilitati per lo scraping cercano di ottenere ciò che desiderano, i dati puliti provenienti da fonti affidabili diventeranno sempre più importanti
Mentre stavo concludendo la ricerca per questo articolo e mi apprestavo a iniziare a scriverlo, OpenAI ha fatto un annuncio perfetto da abbinarci: stanno disabilitando temporaneamente la funzione “Naviga con Bing” su ChatGPT. Se non l’hai mai usata prima, questa è una funzionalità disponibile solo per gli utenti Plus a pagamento. Plus ti offre principalmente accesso a due cose:
- Naviga con Bing – Di default, ChatGPT non si collega a dati di siti web in tempo reale (ad esempio, se gli chiedi quali sono i prossimi film Marvel nel 2023, non ti darà una risposta perché i suoi dati di addestramento si fermano a settembre 2021). Naviga con Bing va oltre questa limitazione, sfruttando informazioni in tempo reale provenienti da siti web in tutto il mondo, a cui OpenAI ora ha accesso grazie alla partnership con Microsoft Bing.
- Plugin – Queste sono integrazioni integrate in ChatGPT da aziende indipendenti per esporre le loro funzionalità attraverso l’interfaccia utente di ChatGPT (ad esempio, OpenTable ti consente di cercare prenotazioni in ristoranti, Kayak ti consente di cercare voli all’interno di ChatGPT se utilizzi i loro plugin); Al momento sono sperimentali e sono funzionalità “interessanti”, ma gli utenti non le hanno trovate ancora utili.
Quindi, Naviga con Bing è particolarmente importante per ChatGPT perché il suo più grande concorrente, Google Bard, ha la capacità di utilizzare dati in tempo reale da Google Search. Ecco alcuni esempi di risposte da ChatGPT e Bard per i film Marvel nel 2023:
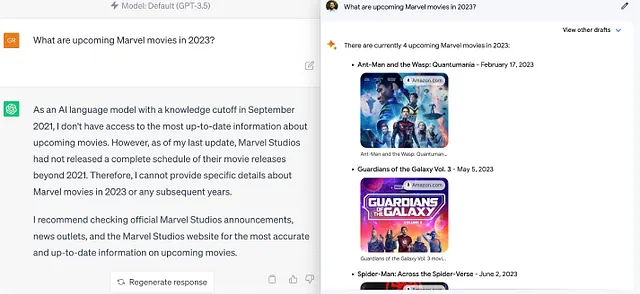
Quindi, puoi capire perché sia non banale per OpenAI disabilitare Naviga con Bing (anche temporaneamente). La motivazione è interessante:
Abbiamo appreso che la versione beta di ChatGPT Browse può occasionalmente mostrare contenuti in modi che non desideriamo. Ad esempio, se un utente chiede specificamente il testo completo di un URL, potrebbe inavvertitamente soddisfare questa richiesta. A partire dal 3 luglio 2023, abbiamo disabilitato temporaneamente la funzione beta Naviga con Bing per un eccesso di cautela, mentre risolviamo questo problema per fare le cose nel modo corretto nei confronti dei proprietari dei contenuti. Stiamo lavorando per ripristinare la versione beta il più rapidamente possibile e apprezziamo la tua comprensione!
È interessante perché mette in luce una questione più ampia: aziende come OpenAI e Google Bard utilizzano una grande quantità di dati per addestrare i loro modelli, ma non è chiaro se dispongano delle autorizzazioni per utilizzare questi dati e come compensano i creatori/piazzamenti dei contenuti per l’utilizzo di questi dati.
In questo articolo, affronteremo alcune cose:
- Cosa sono i modelli di linguaggio di grandi dimensioni (LLM) e perché hanno bisogno di dati?
- Dove ottengono questi dati?
- Perché aziende come OpenAI e Google dovrebbero preoccuparsi di come ottengono i dati?
- Quali strategie stanno adottando le piattaforme di contenuti per rispondere a questo problema?
Alla fine dell’articolo, speriamo che tu possa avere una visione più completa di questo argomento in rapida evoluzione. Andiamo avanti.
Cosa sono i modelli di linguaggio di grandi dimensioni e perché hanno bisogno di dati?
Inizieremo con una semplice spiegazione di come funzionano i modelli di apprendimento automatico: diciamo che vuoi prevedere quanto sarà in ritardo l’orario di arrivo del tuo prossimo volo. Una versione molto semplice può essere un’ipotesi umana (ad esempio, se il tempo è brutto o se la compagnia aerea è pessima, è probabile che sia in ritardo). Se vuoi rendere questa previsione più affidabile, puoi prendere dati reali sugli orari di arrivo dei voli e confrontarli con vari fattori (ad esempio, come gli orari di arrivo sono correlati alla compagnia aerea, all’aeroporto di destinazione, alla temperatura, alle precipitazioni, ecc.).
Ora puoi fare un passo avanti, utilizzare i dati e creare un’equazione matematica per prevedere questo. Ad esempio: Minuti di ritardo = A * punteggio di affidabilità della compagnia aerea + B * affollamento di un aeroporto + C * quantità di pioggia. Come calcoli A, B, C? Utilizzando la grande quantità di dati passati sugli orari di arrivo che hai e facendo qualche calcolo su di essi.
Questa equazione in termini matematici viene chiamata “regressione” ed è uno dei modelli di apprendimento automatico di base più comunemente utilizzati. Si noti che il modello è essenzialmente una formula matematica composta da “caratteristiche” (ad esempio, punteggio di affidabilità della compagnia aerea, affollamento di un aeroporto, quantità di pioggia) e “pesi” (ad esempio, A, B, C, che indicano quanto peso ogni variabile aggiunge alla previsione).
Lo stesso concetto può essere esteso ad altri modelli più complessi, come le “reti neurali” (che avrai sentito nel contesto del deep learning) o i modelli di grande dimensione del linguaggio (spesso abbreviati in LLM e sono i modelli sottostanti per tutti i prodotti di intelligenza artificiale basati su testo come la ricerca di Google, ChatGPT e Google Bard).
Non entreremo troppo nei dettagli, ma ciascuno di questi modelli, compresi i LLM, è una combinazione di “caratteristiche” e “pesi”. I modelli più performanti hanno la migliore combinazione di caratteristiche e pesi, il modo per ottenere questa combinazione è attraverso l’addestramento con una TON di dati. Più dati hai, più performante sarà il modello. Pertanto, avere un volume massiccio di dati è fondamentale e le aziende che addestrano questi modelli devono procurarsi questi dati.
Da dove stanno ottenendo questi dati?
In generale, le fonti di dati possono essere ampiamente suddivise in:
- Dati open source: Queste sono fonti di dati ad alto volume disponibili tipicamente per scopi commerciali, inclusa la formazione dei LLM. Esempi di grandi fonti di dati open source includono Wikipedia, CommonCrawl (un repository aperto di dati di crawling web), Project Gutenberg (eBook gratuiti), BookCorpus (libri gratuiti scritti da autori non pubblicati) per citarne alcuni.
- Siti web di contenuti indipendenti: Questi includono un ampio insieme di siti web come pubblicazioni di notizie (pensa a Washington Post, the Guardian), piattaforme specifiche per creatori (pensa a Kickstarter, Patreon, VoAGI) e piattaforme di contenuti generati dagli utenti (pensa a Reddit, Twitter). Di solito hanno politiche più restrittive per quanto riguarda l’estrazione dei loro contenuti, soprattutto se viene utilizzata per scopi commerciali.
In un mondo ideale, le aziende LLM elencherebbero esplicitamente tutte le fonti di dati utilizzate / estratte e lo farebbero nel rispetto delle politiche di chi possiede i contenuti. Tuttavia, molte di esse non sono state trasparenti al riguardo, il più grande trasgressore è OpenAI (creatore di ChatGPT). Google ha pubblicato un set di dati utilizzato per l’addestramento, chiamato C-4. Washington Post ha realizzato un’analisi interessante di questi dati, ecco le prime 30 fonti in base alla loro analisi:
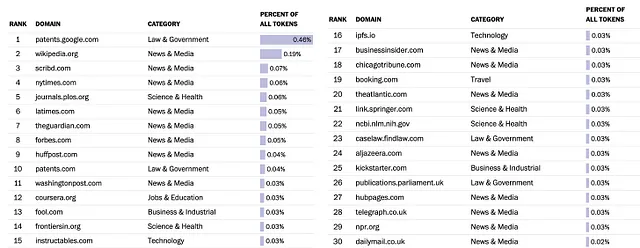
La maggior parte di questi dati è stata acquisita tramite scraping e le piattaforme di contenuti sostengono che questi dati sono stati estratti in violazione delle loro condizioni d’uso. Sono chiaramente insoddisfatte, soprattutto considerando la quantità di vantaggi che le aziende LLM riescono a ottenere dai dati.
Perché aziende come OpenAI e Google dovrebbero preoccuparsi di come ottengono i dati?
Ok, i fornitori di contenuti si lamentano. E quindi? Dovrebbero preoccuparsi di questo le aziende che producono prodotti LLM, oltre a voler essere “onesti” per il bene del loro cuore?
L’acquisizione di dati sta diventando sempre più critica per due motivi principali.
Complicazioni legali: Le aziende che sviluppano LLM si trovano sempre più coinvolte in cause legali da parte di creatori e editori di contenuti che ritengono che i loro dati siano stati utilizzati senza autorizzazione. Le battaglie legali possono essere costose e danneggiare la reputazione delle aziende coinvolte. Ad esempio:
- Microsoft, GitHub e OpenAI sono stati citati in giudizio per presunta violazione del diritto d’autore per la riproduzione di codice open source tramite intelligenza artificiale
- Getty Images fa causa a Stable Diffusion, un generatore di arte AI
- Gli strumenti di arte AI Stable Diffusion e Midjourney vengono presi di mira con una causa di violazione del diritto d’autore
[nota a margine: Stable Diffusion, Midjourney sono generatori di immagini AI e non generatori di linguaggio e quindi non sono “LLM”, ma i principi stessi di ciò che costituisce un modello e come vengono addestrati sono gli stessi]
Fare progressi con i clienti aziendali: I clienti aziendali che utilizzano LLM o le loro derivazioni devono essere certi della legittimità dei dati di addestramento. Non vogliono affrontare sfide legali a causa delle pratiche di acquisizione dei dati dei LLM che utilizzano, soprattutto se non possono trasferire la responsabilità di tali cause legali ai fornitori dei LLM.
È davvero possibile costruire modelli efficaci con tutte queste restrizioni di acquisizione dati disordinate? È una domanda legittima. Un esempio di applicazione di questi principi è l’annuncio recente di Adobe Firefly (è un prodotto interessante e in versione beta aperta, puoi provarlo) – il prodotto ha una vasta gamma di funzionalità, tra cui il testo in immagine, ovvero puoi digitare una riga di testo e genererà un’immagine per te.
Ciò che rende Firefly un ottimo esempio è:
- Adobe utilizza solo immagini che fanno parte di Adobe Stock per le quali possiedono già le licenze, oltre a immagini open source non soggette a restrizioni di licenza. Inoltre, hanno anche annunciato di voler costruire IA generative in modo da consentire ai creatori di monetizzare il loro talento e che annunceranno un modello di compensazione per i contributori di Adobe Stock una volta che Firefly sarà uscito dalla versione beta
- Adobe proteggerà i propri clienti per gli output di Firefly (a partire dalla funzione di testo in immagine) – se non hai mai sentito il termine “proteggere” prima, in parole semplici, Adobe afferma di essere sicura di aver acquisito i dati in modo corretto per i propri modelli e quindi è disposta a coprire qualsiasi azione legale che potrebbe essere intentata se qualcuno citasse in giudizio un cliente di Adobe per l’uso degli output di Firefly.
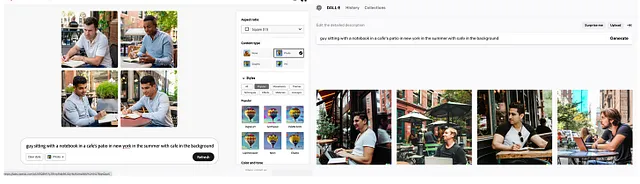
Una critica all’approccio di acquisizione pulita dei dati è che potrebbe compromettere la qualità degli output generati dai modelli. Il lato opposto di questo argomento è che dati di alta qualità posseduti dai fornitori di contenuti possono fornire input di migliore qualità per l’addestramento del modello (garbage in, garbage out è reale quando si tratta di addestramento del modello). Nell’immagine sottostante, a sinistra c’è un output di Adobe Firefly, a destra quello di Dall-E di OpenAI. Se li confronti, sono abbastanza simili e l’output di Firefly è probabilmente più realistico, il che dimostra che è possibile costruire modelli linguistici di alta qualità basandosi solo su dati acquisiti correttamente.
Quali strategie stanno adottando le piattaforme di contenuti per rispondere a questo?
Diverse aziende che dispongono di un’ampia quantità di contenuti hanno espresso con forza l’intenzione di addebitare alle aziende di intelligenza artificiale l’utilizzo dei loro dati. È importante notare che la maggior parte di loro non ha assunto una posizione anti-intelligenza artificiale (ovvero non stanno dicendo che l’IA prenderà il controllo del nostro business, quindi stiamo chiudendo l’accesso ai contenuti). Sono per lo più favorevoli a una struttura commerciale che definisca come avverrà l’accesso a questi dati e come saranno compensati.
StackOverflow, probabilmente il forum più popolare che i programmatori utilizzano quando hanno bisogno di aiuto, ha pianificato di iniziare ad addebitare ai grandi sviluppatori di IA l’accesso ai 50 milioni di contenuti Q&A presenti nel suo servizio. Il CEO di StackOverflow, Prashanth Chandrasekar, ha espresso alcuni argomenti ragionevoli:
- Il ricavo aggiuntivo sarà vitale per garantire che StackOverflow possa continuare ad attirare utenti e mantenere informazioni di alta qualità, il che aiuterà anche i futuri chatbot a generare nuove conoscenze sulla piattaforma
- StackOverflow continuerà a concedere gratuitamente la licenza dei dati a determinate persone e aziende e prevede di addebitare solo alle aziende che sviluppano LLM per scopi commerciali
- Egli sostiene che gli sviluppatori di LLM stanno violando i termini di servizio di Stack Overflow, che a suo avviso rientrano in una licenza Creative Commons che richiede a chiunque utilizzi successivamente i dati di menzionare la fonte da cui provengono (cosa che gli LLM non fanno)
Reddit ha fatto un annuncio simile (insieme ai suoi controversi cambiamenti nella tariffazione dell’API che hanno chiuso diverse app di terze parti). Il CEO di Reddit, Steve Huffman, ha dichiarato al Times: “Il corpus di dati di Reddit è davvero prezioso, ma non dobbiamo fornire tutto quel valore a alcune delle più grandi aziende del mondo gratuitamente”.
Twitter ha interrotto l’accesso gratuito alle loro API all’inizio di quest’anno ed ha anche annunciato un cambiamento recente che limita il numero di tweet che un utente può vedere in un giorno, nel tentativo di prevenire lo scraping non autorizzato dei dati. Anche se l’implementazione e la diffusione delle politiche lasciano molto a desiderare, l’intento è chiaro: non intendono fornire accesso gratuito ai dati per scopi commerciali.
Un altro gruppo che ha espresso una posizione unitaria e una critica ai LLM sono le organizzazioni di notizie. La News/Media Alliance (NMA), che rappresenta editori di media stampati e digitali negli Stati Uniti, ha pubblicato quello che chiamano principi di intelligenza artificiale (AI). Sebbene non ci siano molti dettagli tattici qui, il messaggio che cercano di trasmettere è chiaro:
Gli sviluppatori e gli attuatori di AI generativa (GAI) non dovrebbero utilizzare la proprietà intellettuale degli editori senza il loro permesso, e gli editori dovrebbero avere il diritto di negoziare un compenso equo per l’utilizzo della loro proprietà intellettuale da parte di questi sviluppatori.
Pertanto, è necessario stipulare accordi scritti e formali.
Il principio dell’uso equo non giustifica l’uso non autorizzato dei contenuti, degli archivi e dei database degli editori da parte dei sistemi GAI. Qualsiasi uso precedente o attuale di tali contenuti senza permesso esplicito costituisce una violazione del diritto d’autore.
Anche in questo caso, le loro argomentazioni non mirano a chiudere queste attività, ma a stipulare accordi commerciali per utilizzare questi dati in conformità con la legge sul copyright, sostenendo inoltre che i modelli di compensazione (ad esempio, le licenze) esistono già nel mercato odierno e quindi non rallenteranno l’innovazione.
Conclusione
Questo è solo l’inizio. Le piattaforme con un elevato volume di contenuti probabilmente cercheranno una compensazione per i loro dati. Anche le aziende che non hanno ancora annunciato questa intenzione ma che hanno già altri programmi di licenza dei dati (ad esempio, LinkedIn, Foursquare, Reuters) probabilmente li adatteranno per le aziende di AI/LLM.
Anche se questo sviluppo potrebbe sembrare un ostacolo all’innovazione, è un passo necessario per la sostenibilità a lungo termine delle piattaforme di contenuti. Assicurando loro una compensazione equa, i creatori di contenuti possono continuare a produrre contenuti di qualità, che a loro volta contribuiranno a rendere i LLM più efficaci.
Grazie per la lettura! Se ti è piaciuto questo articolo, considera di iscriverti alla newsletter Unpacked, dove pubblico analisi approfondite settimanali su argomenti tecnologici e commerciali attuali. Puoi anche seguirmi su Twitter @viggybala. Cordiali saluti, Viggy.






