Quantizzazione a 4 bit con GPTQ
Quantizzazione 4 bit GPTQ
Quantizza i tuoi LLM personali usando AutoGPTQ
Recenti progressi nella quantizzazione dei pesi ci permettono di eseguire grandi modelli di linguaggio su hardware di consumo, come un modello LLaMA-30B su una GPU RTX 3090. Ciò è possibile grazie a nuove tecniche di quantizzazione a 4 bit con una degradazione delle prestazioni minima, come GPTQ, GGML e NF4.
Nell’articolo precedente, abbiamo introdotto le tecniche di quantizzazione naive a 8 bit e l’eccellente LLM.int8(). In questo articolo, esploreremo l’algoritmo GPTQ per capire come funziona e lo implementeremo utilizzando la libreria AutoGPTQ.
Puoi trovare il codice su Google Colab e GitHub.
🧠 Quantizzazione Ottimale del Cervello
Iniziamo introducendo il problema che stiamo cercando di risolvere. Per ogni layer ℓ nella rete, vogliamo trovare una versione quantizzata Ŵₗ dei pesi originali Wₗ. Questo è chiamato il problema di compressione layer-wise. Più specificamente, per minimizzare la degradazione delle prestazioni, vogliamo che le uscite (ŴᵨXᵨ) di questi nuovi pesi siano il più vicine possibile a quelle originali (WᵨXᵨ). In altre parole, vogliamo trovare:
- Guida del Data Scientist alla tipizzazione in Python migliorare la chiarezza del codice
- Predizione di serie temporali multivariate con BQML
- Affascinanti modi in cui l’IA sta aiutando le persone a padroneggiare il tedesco e altre lingue
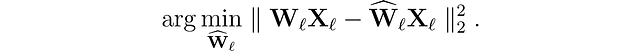
Sono state proposte diverse approcci per risolvere questo problema, ma qui siamo interessati al framework Optimal Brain Quantizer (OBQ).
Questo metodo è ispirato a una tecnica di potatura per rimuovere con attenzione i pesi da una rete neurale densa completamente addestrata (Optimal Brain Surgeon). Utilizza una tecnica di approssimazione e fornisce formule esplicite per il miglior singolo peso w𐞥 da rimuovere e l’aggiornamento ottimale δꟳ per regolare l’insieme dei pesi non quantizzati rimanenti F per compensare la rimozione:
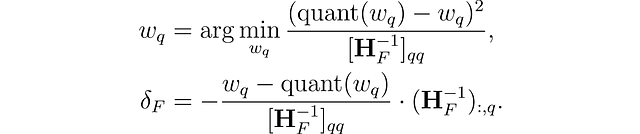
dove quant(w) è l’arrotondamento del peso dato dalla quantizzazione e Hꟳ è l’Hessiano.
Utilizzando OBQ, possiamo quantizzare prima il peso più semplice e poi regolare tutti i pesi non quantizzati rimanenti per compensare questa perdita di precisione. Successivamente, selezioniamo il peso successivo da quantizzare, e così via.

