Una guida pratica all’Analisi Esplorativa dei Dati (EDA) utilizzando Python
Guida pratica all'Analisi Esplorativa dei Dati (EDA) con Python
In questo articolo, spiegherò una delle parti più importanti del ciclo di vita di un progetto di scienza dei dati, ossia l’analisi esplorativa dei dati passo dopo passo con il codice.
Useremo il dataset del Titanic di Kaggle per mostrare l’analisi esplorativa dei dati (EDA).
Il primo passo in un progetto di machine learning è esplorare i dati. Iniziamo.
Importare alcune librerie di base.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore')Lettura dei dati di addestramento
- Sbloccare il potenziale del testo Un’analisi più approfondita dei metodi di pulizia del testo pre-embedding
- Da grezzo a raffinato un viaggio attraverso la pre-elaborazione dei dati – Parte 1
- I migliori podcast sull’IA del 2023
Per leggere i dati, utilizzeremo la funzione read_csv di Pandas. La funzione read_csv richiede il percorso del file CSV come primo argomento.
training_data = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')train = training_data.copy()train.head()
Rimozione delle caratteristiche non necessarie (PassengerId e Name)
Dalla nostra intuizione, possiamo dire che l’esito della sopravvivenza di una persona non dipende dal suo nome o dall’ID del passeggero, quindi rimuoveremo queste due caratteristiche dai dati.
## rimozione delle caratteristiche non importanti (PassengerId e Name)train.drop(columns=['PassengerId','Name'], axis=1, inplace=True)Trovare le informazioni di base sui dati
train.info()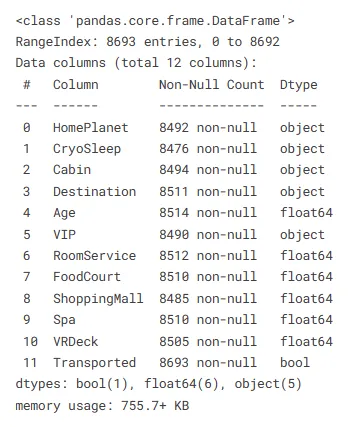
Dividere i dati in due parti: una per le caratteristiche indipendenti e l’altra per le caratteristiche dipendenti
## dividere i dati in caratteristiche indipendenti e dipendentiX = train.drop(['Transported'],axis=1)y = train['Transported']Ottenere i nomi delle caratteristiche numeriche e categoriche nei dati
## ottenere i nomi delle caratteristiche numeriche e categoriche in Xnum_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"Le caratteristiche numeriche nei dati sono {num_feat}.\n")print(f"Le caratteristiche categoriche nei dati sono {cat_feat}.")
Trasformare la caratteristica ‘Cabin’ in tre diverse caratteristiche e quindi rimuovere la caratteristica originale ‘Cabin’
La caratteristica ‘Cabin’ è composta da tre informazioni: la cabina, il numero di cabina e il lato della cabina. Rimuoveremo la barra obliqua e separeremo queste tre informazioni e creeremo tre nuove caratteristiche che contengono queste tre parti della caratteristica ‘Cabin’. Inoltre, dopo aver creato tre nuove caratteristiche, rimuoveremo la caratteristica originale ‘Cabin’.
## rimozione '/' dai valori della caratteristica 'Cabin'X['Cabin'] = X['Cabin'].str.replace('/','')## creazione di tre nuove caratteristiche dividendo la caratteristica 'Cabin' originaleX['Cabin_deck'] = X['Cabin'].str[0]X['Cabin_num'] = X['Cabin'].str[1].apply(pd.to_numeric)X['Cabin_side'] = X['Cabin'].str[2]## Rimozione della caratteristica 'Cabin' originaleX.drop(['Cabin'], axis=1,inplace=True)Verifica dei nomi delle nuove caratteristiche numeriche e categoriche dopo la trasformazione della caratteristica Cabin
Vengono create alcune nuove caratteristiche e alcune vecchie caratteristiche vengono rimosse. Quindi, troviamo nuovamente i nomi delle caratteristiche categoriche e numeriche dopo la trasformazione.
## ottenere nuovamente i nomi delle caratteristiche numeriche e categorichenum_feat = [feature for feature in X.columns if X[feature].dtypes != 'O' ]cat_feat = [feature for feature in X.columns if feature not in num_feat]print(f"Le caratteristiche numeriche nel dataset sono {num_feat}.\n")print(f"Le caratteristiche categoriche nel dataset sono {cat_feat}.")
Si noti che questo metodo per trovare le caratteristiche numeriche darà risultati impropri se abbiamo una caratteristica con un tipo di dati booleano. Poiché non abbiamo una tale caratteristica nel nostro dataset, possiamo usare questo metodo in modo sicuro.
Verifica se ci sono caratteristiche con varianza zero
Dato che maggiore è la varianza dei dati, maggiore sarà il suo contributo alla previsione della caratteristica dipendente, rimuoveremo qualsiasi caratteristica che non contribuisce alla previsione, ovvero la caratteristica con varianza zero.
## verificare se ci sono caratteristiche con varianza zero (caratteristiche numeriche)for feature in num_feat: if X[feature].var() == 0: print(feature)Questo non darà alcun output, ovvero i dati non hanno caratteristiche numeriche con varianza zero.
## verificare se ci sono caratteristiche con varianza zero (caratteristiche categoriche)for feature in cat_feat: if X[feature].nunique() == 1: print(feature)Anche questo blocco di codice non darà alcun output, ovvero i dati non hanno caratteristiche categoriche con varianza zero.
Verifica dei valori unici nelle caratteristiche categoriche
Verifica dei valori unici nei dati delle caratteristiche categoriche e il loro conteggio. Se una delle caratteristiche categoriche ha un numero molto elevato di valori unici, rimuoveremo quella colonna. Questo perché tali colonne sono meno propense a contribuire molto alla formazione del nostro modello.
## verifica dei valori unici in ciascuna delle caratteristiche categoriche for feature in cat_feat: print(f"I valori unici in {feature} sono {X[feature].unique()} (totale {X[feature].nunique()}).\n")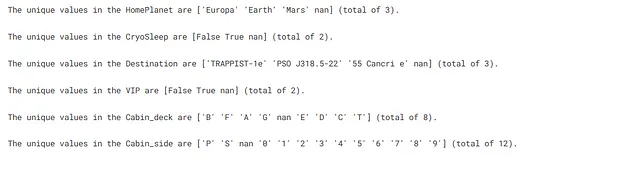
Qui non sembra esserci una caratteristica categorica con un numero molto elevato di valori unici.
Verifica della correlazione tra le caratteristiche indipendenti e le caratteristiche dipendenti
Verifichiamo la correlazione tra le caratteristiche dei dati. Questo ci dirà molte cose. Alcune di queste sono:
- La correlazione tra le caratteristiche indipendenti e la caratteristica dipendente. Se una delle caratteristiche indipendenti ha una correlazione molto bassa con la nostra caratteristica dipendente, allora quella caratteristica indipendente contribuirà molto poco alla formazione del nostro modello. Quindi, possiamo rimuovere quella caratteristica. Questo ci permetterà di mantenere solo le caratteristiche rilevanti per la formazione del nostro modello e ridurrà l’overfitting del modello sui dati.
- La correlazione tra le caratteristiche indipendenti. Questo ci dirà quali caratteristiche indipendenti sono altamente correlate. Supponiamo di avere due caratteristiche altamente correlate, in tal caso, possiamo facilmente rimuoverne una dai nostri dati. Questo renderà il nostro modello più robusto e preverrà anche l’overfitting.
Trovare una correlazione tra le caratteristiche indipendenti numeriche e la caratteristica dipendente.
## verifica della correlazione tra le caratteristiche indipendenti numeriche e le caratteristiche dipendenti dall'importazione sklearn.preprocessing import OrdinalEncoderimport matplotlib.pyplot as pltimport seaborn as snsdf1 = pd.DataFrame(X[num_feat], columns=num_feat) # dataframe con caratteristica numericadf2 = pd.DataFrame(y, columns=['Transported']) # dataframe con caratteristica dipendentedf_num = pd.concat([df1, df2], axis=1) # dataframe con tutte le caratteristiche numeriche e una caratteristica dipendenteplt.figure(figsize=(12,8))corr = df_num.corr()mask = np.triu(np.ones_like(corr, dtype=bool))sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)plt.tight_layout()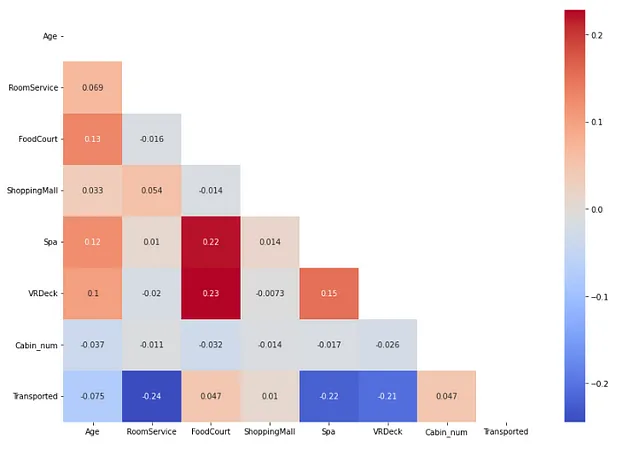
Qui non abbiamo trovato due caratteristiche indipendenti numeriche che siano altamente correlate tra loro.
Trovare una correlazione tra caratteristiche indipendenti categoriche e la caratteristica dipendente.
## controllo della correlazione tra le caratteristiche indipendenti categoriche e le caratteristiche dipendenti
from sklearn.preprocessing import OrdinalEncoder
df1 = pd.DataFrame(OrdinalEncoder().fit_transform(X[cat_feat]), columns=cat_feat) # dataframe con le caratteristiche categoriche codificate
df2 = pd.DataFrame(y, columns=['Trasportato']) # dataframe con la caratteristica dipendente
df_cat = pd.concat([df1, df2], axis=1) # dataframe con tutte le caratteristiche categoriche codificate e una caratteristica dipendente
plt.figure(figsize=(12,8))
corr = df_cat.corr()
mask = np.triu(np.ones_like(corr, dtype=bool))
sns.heatmap(corr, annot=True, cmap='coolwarm',mask=mask)
plt.tight_layout()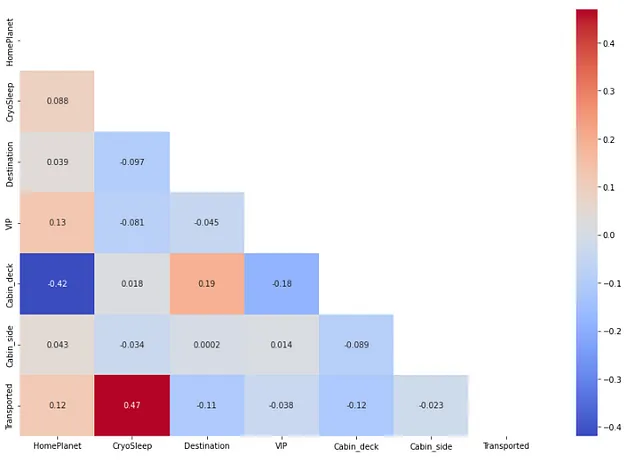
Anche qui non abbiamo trovato due caratteristiche categoriche che siano altamente correlate. Nota che qui stiamo eseguendo una codifica delle caratteristiche categoriche affinché la funzione di correlazione possa funzionare.
Verifica della presenza di valori mancanti nei nostri dati
## controllo il numero di valori mancanti in ciascuna delle caratteristiche
missing_values_df = pd.DataFrame()
missing_values_df['Caratteristiche'] = X.columns
missing_values_df['Numero_di_valori_mancanti'] = X.isnull().sum().to_numpy()
missing_values_df['Percentuale_di_valori_mancanti (%)'] = missing_values_df['Numero_di_valori_mancanti'].apply(lambda x: np.round((x/X.shape[0])*100),2)
missing_values_df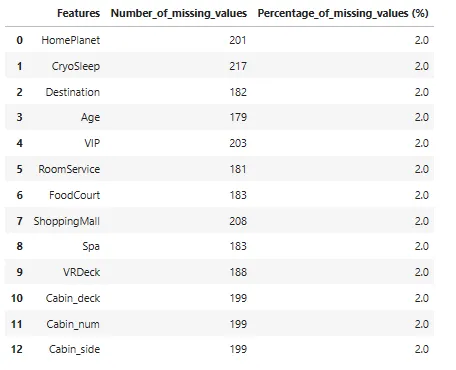
Visualizziamo i valori mancanti per divertimento.
import missingno as msgnmsgn.matrix(X)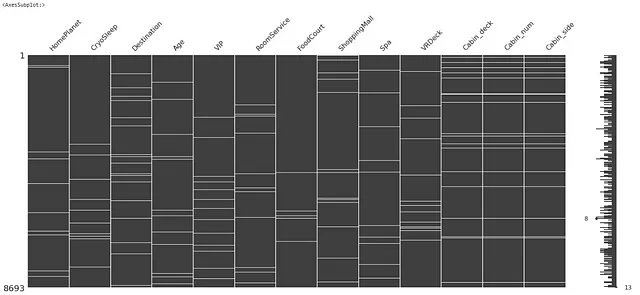
Nel diagramma sopra, i valori mancanti sono mostrati con le linee di colore bianco in ciascuna caratteristica dei dati.
I dati sembrano avere una quantità molto bassa di valori mancanti (circa il 2% della dimensione totale dei dati)
Gestire i valori mancanti è una delle attività più importanti nella fase di preelaborazione dei dati. Rimuovere o imputare i dati mancanti è un’operazione molto comune per gestire i dati mancanti. Tuttavia, non è sempre la migliore opzione per gestire i dati mancanti. In alcuni casi, i dati mancanti potrebbero essere dovuti a condizioni specifiche durante la raccolta dei dati o potrebbe esserci un caso in cui i dati mancano secondo un certo modello specifico.
Per rendere questo concetto chiaro, prendiamo un esempio. Supponiamo di condurre un sondaggio tra gli studenti universitari. Una delle domande del sondaggio riguarda il peso di una persona. In questo caso, alcune studentesse potrebbero essere restie a inserire il loro peso nel sondaggio (questo è dovuto all’idea che le studentesse universitarie siano più consapevoli del loro peso rispetto ai ragazzi. Non so se sia vero, ma assumiamolo per il nostro esempio). Quindi otterremo molti valori mancanti per l’età nel caso delle ragazze. Questo è un esempio di dati mancanti secondo un certo modello.
Consideriamo un altro caso del nostro sondaggio. Supponiamo che un’altra domanda nel nostro sondaggio riguardi la forza muscolare. Per questo tipo di domanda, molti ragazzi universitari potrebbero essere restii a fornire una risposta (questo è ancora dovuto a un’idea simile, ovvero che i ragazzi universitari siano molto consapevoli della loro forma fisica o forza). Quindi otterremo un alto numero di valori mancanti nel caso dei ragazzi.
Dobbiamo prendere una decisione su come gestire i valori mancanti in base a criteri simili a quelli menzionati in precedenza. Un modo per mantenere il pattern dei valori mancanti durante la sostituzione dei valori mancanti è utilizzare SimpleImputer di Scikit-Learn con il suo argomento chiamato add_indicator.
Verifica la presenza di valori anomali nei dati utilizzando i grafici di distribuzione e i boxplot
- Utilizzando i grafici di distribuzione
Possiamo confermare la presenza di valori anomali nei dati se la distribuzione delle caratteristiche nei dati è asimmetrica.
## Verifica la presenza di valori anomali nelle caratteristiche numeriche utilizzando i grafici di distribuzionesns.set_style('darkgrid')plt.figure(figsize=(22,13))for index, feature in enumerate(num_feat): plt.subplot(3,3,index+1) sns.distplot(X[feature],kde=True, color='b') plt.xlabel(feature) plt.ylabel('distribuzione') plt.title(f"Distribuzione di {feature}")plt.tight_layout()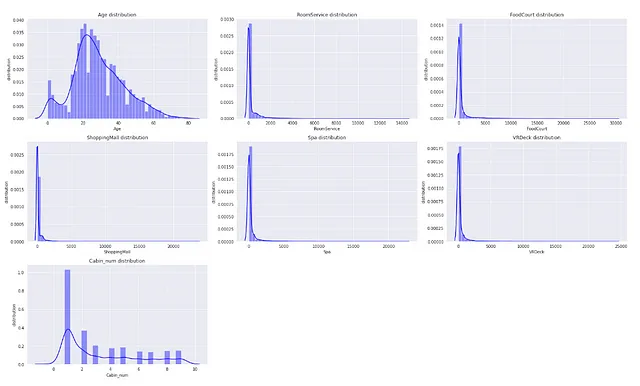
2. Utilizzando i boxplot
Il boxplot è un modo più intuitivo per visualizzare i valori anomali nei nostri dati.
Se il valore > (valore del terzo quartile + costante * intervallo interquartile) ==> il valore è un valore anomalo
Se il valore < (valore del primo quartile – costante * intervallo interquartile) ==> il valore è un valore anomalo
Di solito, il valore costante utilizzato è 1.5. Nel boxplot, i valori anomali sono rappresentati dalla presenza di cerchi vuoti nella maggior parte dei casi.
## visualizzando chiaramente i valori anomali utilizzando il boxplotX[num_feat].plot(kind='box',figsize=(15,10))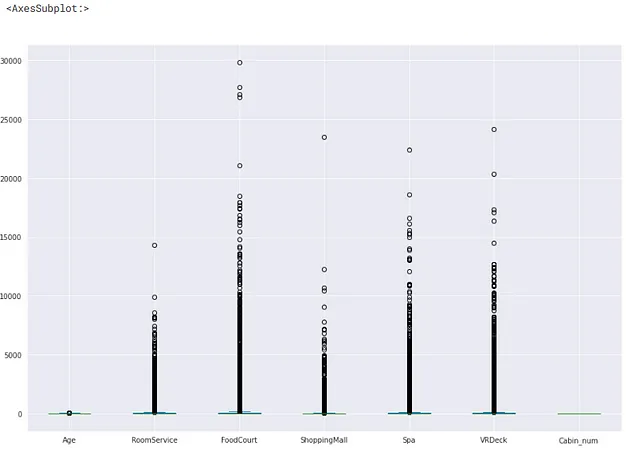
Si noti che questa distribuzione è prima di occuparsi dei valori mancanti nei dati. La distribuzione potrebbe cambiare se imputiamo i valori mancanti. Pertanto, è una buona pratica verificare la distribuzione dei dati dopo aver affrontato i valori mancanti nei dati.
Per il problema in questione, dovremmo analizzare il valore anomalo prima di rimuoverlo completamente dai nostri dati, poiché a volte la presenza del valore anomalo può aiutarci nel nostro scopo. Ad esempio, se stiamo effettuando un rilevamento delle frodi con carte di credito, in tal caso stiamo cercando valori anomali nei nostri dati per rilevare frodi. Quindi, non ha senso rimuovere i valori anomali. Ma d’altra parte, i valori anomali possono anche rendere il nostro modello meno accurato. La figura seguente mostra come si dovrebbe procedere nell’analisi dei valori anomali per un problema.
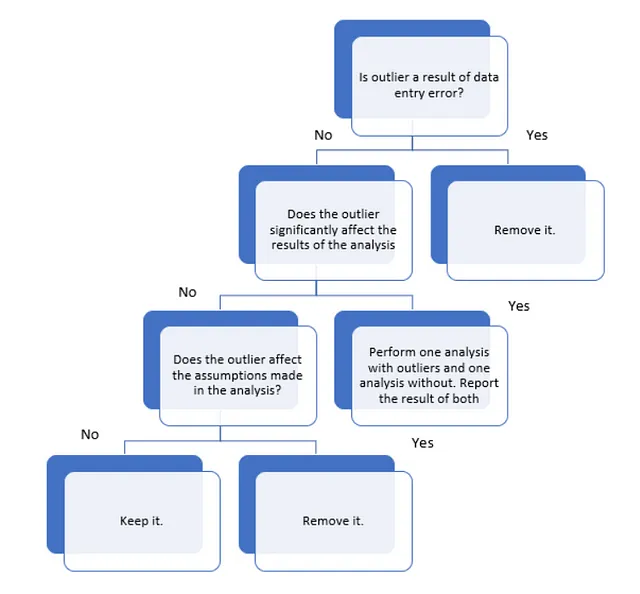
Il nostro obiettivo qui è prevedere se un passeggero è sopravvissuto o meno in base alle sue informazioni come l’età, quanto ha speso per il servizio in camera, ecc. Quindi, per il nostro problema, i valori anomali sarebbero le persone molto anziane o molto giovani, le persone che hanno speso una quantità molto alta o molto bassa per il servizio in camera, il food court, il centro commerciale, la spa, VRDeck, ecc.
Seguiamo il diagramma sopra per analizzare i valori anomali. Nel nostro problema, i valori anomali come i dati di persone con un’età molto alta non possono essere considerati come risultato di alcuna immissione di dati. Inoltre, questi valori anomali influenzeranno molto probabilmente il nostro modello poiché questi valori anomali rappresentano una parte molto piccola dei nostri dati complessivi e quindi non possono essere considerati rappresentativi di tutti i nostri dati. Quindi, è saggio rimuovere i valori anomali dai nostri dati.
Verifica la multicolinearità tra le caratteristiche indipendenti utilizzando pairplot e utilizzando il valore VIF
Nella nostra analisi, la multicolinearità si verifica quando due o più caratteristiche indipendenti sono altamente correlate tra loro, in modo tale che non forniscono informazioni univoche al processo di addestramento del nostro modello di apprendimento automatico. Possiamo verificare ciò utilizzando tre metodi: utilizzando un grafico di correlazione (come quello che abbiamo creato in precedenza), utilizzando pairplot e utilizzando il valore VIF. Di questi tre, il VIF è un modo sicuro per verificare la multicolinearità.
Qui verificheremo la multi-collinearità per le caratteristiche numeriche.
- Utilizzando pairplot
Possiamo essere sicuri della multi-collinearità tra due caratteristiche se il loro grafico mostra qualche tipo di pattern.
sns.pairplot(X[num_feat], corner=True,diag_kind='kde')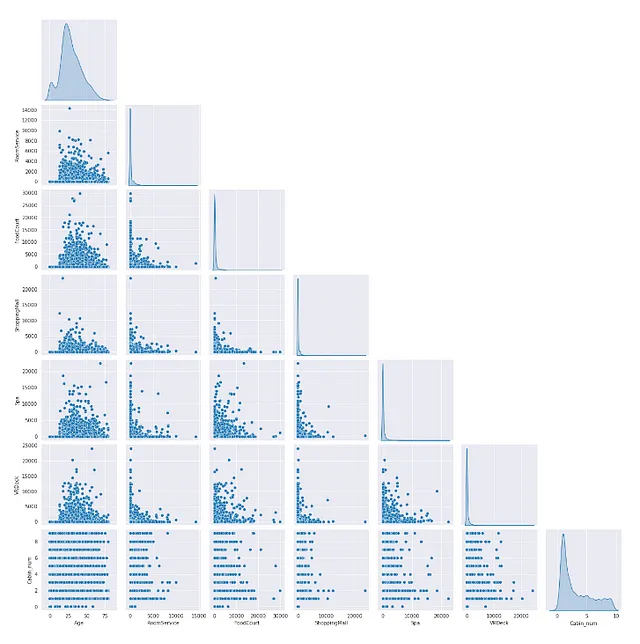
Non vediamo molto un pattern tra le caratteristiche numeriche nei nostri dati.
2. Utilizzando il valore VIF
Interpretazione dei valori VIF:
VIF = 1: Non c’è correlazione tra una data variabile predittiva e altre variabili predittive nel modello.VIF tra 1 e 5: C’è una correlazione moderata tra una data variabile predittiva e altre variabili predittive nel modello.VIF > 5: C’è una correlazione severa tra una data variabile predittiva e altre variabili predittive nel modello.
## Trovare la multi-collinearità nelle caratteristiche indipendenti numeriche# Utilizziamo le seguenti regole di base per interpretare i valori VIF:from patsy import dmatricesfrom statsmodels.stats.outliers_influence import variance_inflation_factorfrom sklearn.impute import SimpleImputer#create DataFrame to hold VIF valuesvif_df = pd.DataFrame()vif_df['Variable'] = num_feat #calculate VIF for each predictor variable # riempiremo i valori mancanti nei dati con la media dei dati prima di alimentarli alla funzionenum_df = pd.DataFrame(SimpleImputer(strategy='mean').fit_transform(X[num_feat]), columns=num_feat)vif_df['VIF'] = [variance_inflation_factor(num_df.values, i) for i in range(num_df.shape[1])]def mc_check(x): if x == 1: return 'Basso' elif (x > 1 and x < 5): return 'Moderato' elif (x >= 5): return 'Severo'vif_df['Presenza di Multi-Collinearità'] = vif_df['VIF'].apply(mc_check)#visualizza VIF per ogni variabile predittiva print(vif_df)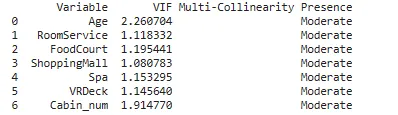
Esaminando la distribuzione delle caratteristiche categoriche
## Esaminare la distribuzione delle caratteristiche categorichesns.set_style('darkgrid')plt.figure(figsize=(22,7))for index, feature in enumerate(cat_feat): plt.subplot(2,3,index+1) sns.countplot(x=feature,data=X,palette='coolwarm') plt.xlabel(feature) plt.ylabel('distribuzione') plt.title(f"Distribuzione di {feature}") plt.tight_layout()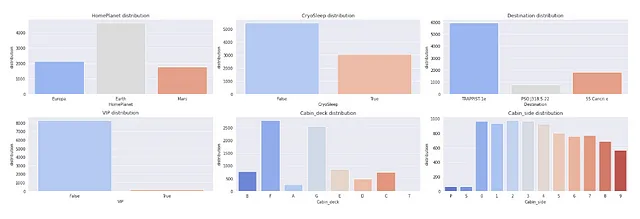
Verifica se l’insieme di dati è sbilanciato o meno
Un insieme di dati è chiamato sbilanciato se il numero di punti dati per ciascuno dei valori unici della caratteristica dipendente differisce di molto. Un insieme di dati sbilanciato crea problemi durante la suddivisione dell’insieme di dati in dati di addestramento e di convalida. E il modello di apprendimento automatico addestrato su tali dati non generalizzerà bene su nuovi dati.
## Verifica se l'insieme di dati è sbilanciato o nonotrain['Transported'].value_counts()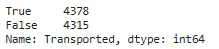
Qui possiamo vedere che il conteggio di ‘True’ e ‘False’ non differisce di molto. Quindi possiamo concludere che i nostri dati non sono sbilanciati.
Questa è una spiegazione molto basilare su come di solito viene condotta un’analisi esplorativa dei dati (EDA). Potrebbero esserci molti altri passaggi coinvolti nell’EDA, ma quelli derivano dalla pratica. Inoltre, ci sono molti altri modi per creare diversi tipi di grafici interessanti e intuitivi per visualizzare i dati, gli outlier, i valori mancanti e molto altro. Esplorare tali cose è qualcosa che consiglio vivamente. Per trovare molte idee interessanti del genere, Kaggle è un ottimo posto.
Risorse
Uno dei passaggi dell’EDA è stato effettuato per individuare le caratteristiche con varianza zero. Per sapere come la varianza è correlata alla quantità di informazioni che una caratteristica contiene, consulta l’articolo seguente di Casey Cheng.
Analisi delle componenti principali (PCA) spiegata visivamente senza matematica
L’Analisi delle componenti principali (PCA) è uno strumento indispensabile per la visualizzazione e la riduzione della dimensionalità dei dati…
towardsdatascience.com
Per saperne di più sui boxplot su Wikipedia.
Il codice utilizzato in questo articolo è preso in prestito dal mio quaderno Kaggle. Controlla l’intero codice utilizzando il seguente link.
airship-titanic-4
Esplora ed esegui codice di machine learning con Kaggle Notebooks | Utilizzando dati da Spaceship Titanic
www.kaggle.com
Outro
Spero che ti sia piaciuto questo articolo. Seguimi su VoAGI per leggere altri articoli simili.
Collegati con me su LinkedIn.
Per saperne di più su di me, visita il mio sito web.
Scrivimi all’indirizzo [email protected]






