PyTorch LSTM – Forme di Input, Stato Nascosto, Stato della Cellula e Output
PyTorch LSTM - Input, Hidden State, Cell State, and Output Forms
In Pytorch, per utilizzare un LSTM (con nn.LSTM()), è necessario capire come devono essere modellati i tensori che rappresentano la serie temporale di input, il vettore di stato nascosto e il vettore di stato della cella. In questo articolo, supponiamo che si stia lavorando con una serie temporale multivariata. Ogni serie temporale multivariata nel dataset contiene più serie temporali univariate.
Ecco le differenze rispetto a LSTMCell di pytorch discusse nel seguente link:
Pytorch LSTMCell — forme di input, stato nascosto e stato della cella
In pytorch, per utilizzare un LSTMCell, è necessario capire come devono essere modellati i tensori che rappresentano la serie temporale di input, lo stato nascosto…
VoAGI.com
- Ricercatori dell’UCI e di Harvard presentano TalkToModel che spiega ai suoi utenti i modelli di apprendimento automatico
- Come il nuovo paradigma di Google AI elimina il costo di composizione negli algoritmi di apprendimento automatico a più passaggi per una maggiore utilità
- Una nuova ricerca sull’IA da Tel Aviv e dall’Università di Copenhagen introduce un approccio plug-and-play per il rapido perfezionamento dei modelli di diffusione testo-immagine utilizzando un segnale discriminativo.
- Con nn.LSTM possono essere creati diversi livelli di LSTM, impilandoli per formare una LSTM impilata. La seconda LSTM prende in input l’output della prima LSTM e così via.
2. può essere aggiunto il dropout nella classe nn.LSTM.
3. È possibile fornire input non raggruppati a nn.LSTM.
C’è un’altra differenza significativa che verrà discussa successivamente in questo post.
In questo articolo utilizziamo la seguente terminologia,
batch = numero di serie temporali multivariate in un unico batch dal dataset
input_features = numero di serie temporali univariate in una serie temporale multivariata
time steps = numero di time steps in ogni serie temporale multivariata
Il batch di serie temporali multivariate da fornire come input al LSTM dovrebbe essere un tensore di forma (time_steps, batch, input_features)
La seguente immagine dà un’idea di questa forma per l’input:

Tuttavia, nell’LSTM, c’è un altro modo di modellare l’input. Questo è spiegato di seguito.
Nell’inizializzazione di un oggetto LSTM, devono essere forniti gli argomenti input_features e hidden_size.
Qui,
input_features = numero di serie temporali univariate in una serie temporale multivariata (stesso valore di input_features menzionato in precedenza)
hidden_size = numero di dimensioni nel vettore di stato nascosto.
Altri argomenti che la classe LSTM può prendere:
num_layers = numero di livelli LSTM impilati l’uno sull’altro. Quando più livelli sono impilati l’uno sull’altro, si parla di LSTM impilata. Per impostazione predefinita, il numero di layer = 1
dropout = se diverso da zero, verrà aggiunto un layer di dropout all’output di ogni layer LSTM con una probabilità di dropout pari a questo valore. Per impostazione predefinita, questo valore è 0, il che significa che non c’è dropout.
batch_first = se True, i tensori di input e output avranno dimensioni (batch, time_steps, input_features) invece di (time_steps, batch, input_features). Per impostazione predefinita, questo è False.
proj_size = dimensione della proiezione. Se proj_size > 0, verrà utilizzato LSTM con proiezioni.
La serie temporale e lo stato nascosto iniziale e lo stato della cella iniziale dovrebbero essere forniti come input per una propagazione in avanti attraverso l’LSTM.
La propagazione in avanti di input, stato nascosto iniziale e stato della cella iniziale attraverso l’oggetto LSTM dovrebbe essere nel formato:
LSTM(input_time_series, (h_0, c_0))
Vediamo come modellare il vettore di stato nascosto e il vettore di stato della cella prima di fornirli all’LSTM per la propagazione in avanti.
h_0 – (num_layers, batch, h_out). Qui h_out = proj_size se proj_size > 0 altrimenti hidden_size
c_0 – (num_layers, batch, hidden_size)
La seguente immagine aiuta a capire la forma dei vettori nascosti.

Una figura simile si applica anche ai vettori di stato delle celle.
Dall’immagine si può capire che la dimensionalità dei vettori nascosti e dei vettori di stato delle celle per tutti i livelli è la stessa.
Considera il seguente frammento di codice:
import torch
import torch.nn as nn
lstm_0 = nn.LSTM(10, 20, 2) # (input_features, hidden_size, num_layers)
inp = torch.randn(4, 3, 10) # (time_steps, batch, input_features) -> input time series
h0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> valore iniziale dello stato nascosto
c0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> valore iniziale dello stato della cella
output, (hn, cn) = lstm_0(input, (h0, c0)) # passaggio in avanti dell'input attraverso l'LSTMChiamare nn.LSTM() chiamerà il metodo magico __init__() e creerà l’oggetto LSTM. Nel codice sopra, questo oggetto è referenziato come lstm_0.
Nei RNN in generale (LSTM è un tipo di RNN), ogni time_step della serie temporale di input deve essere passato all’RNN uno alla volta in un ordine sequenziale per essere elaborato dall’RNN.
Per elaborare serie temporali multivariate in batch utilizzando un LSTM, ogni time_step in tutte le MTS nel batch deve essere passato attraverso l’LSTM in sequenza.
Una singola chiamata al passaggio in avanti dell’LSTM elabora l’intera serie processando ogni time step in sequenza. Questo è diverso da LSTMCell in cui una singola chiamata elabora solo un time_step e non l’intera serie.
L’output del codice sopra è:
tensor([[[ 3.8995e-02, 1.1831e-01, 1.1922e-01, 1.3734e-01, 1.6157e-02, 3.3094e-02, 2.8738e-01, -6.9250e-02, -1.8313e-01, -1.2594e-01, 1.4951e-01, -3.2489e-01, 2.1723e-01, -1.1722e-01, -2.5523e-01, -6.5740e-02, -5.2556e-02, -2.7092e-01, 3.0432e-01, 1.4228e-01], [ 9.2476e-02, 1.1557e-02, -9.3600e-03, -5.2662e-02, 5.5299e-03, -6.2017e-02, -1.9826e-01, -2.7072e-01, -5.5575e-02, -2.3024e-03, -2.6832e-01, -5.8481e-01, -8.3415e-03, -2.8817e-01, 4.6101e-03, 3.5043e-02, -6.2501e-01, 4.2930e-02, -5.4698e-01, -5.8626e-01], [-2.8034e-01, -3.4194e-01, -2.1888e-02, -2.1787e-01, -4.0497e-01, -3.6124e-01, -1.5303e-01, -In questa output ci sono 4 array corrispondenti ai 4 passaggi temporali. Ogni di questi passaggi temporali contiene 3 array corrispondenti ai 3 MTS nel batch. Ogni di questi 3 array contiene 20 elementi -> questo è lo stato nascosto. Quindi per ogni vettore x_t in ogni passaggio temporale in ogni MTS, viene prodotto uno stato nascosto. Questi sono gli stati nascosti nell'ultimo strato del LSTM impilato.
Output: (output_multivariate_time_series, (h_n, c_n))
Se si stampa hn che è presente nel codice sopra, il seguente è l'output:
tensor([[[-0.3046, -0.1601, -0.0024, -0.0138, -0.1810, -0.1406, -0.1181, 0.0634, 0.0936, -0.1094, -0.2822, -0.2263, -0.1090, 0.2933, 0.0760, -0.1877, -0.0877, -0.0813, 0.0848, 0.0121], [ 0.0349, -0.2068, 0.1353, 0.1121, 0.1940, -0.0663, -0.0031, -0.2047, -0.0008, -0.0439, -0.0249, 0.0679, -0.0530, 0.1078, -0.0631, 0.0430, 0.0873, -0.1087, 0.3161, -0.1618], [-0.0528, -0.2693, 0.1001, -0.1097, 0.0097, -0.0677, -0.0048, 0.0509, 0.0655, 0.0075, -0.1127, -0.0641, 0.0050, 0.1991, 0.0370, -0.0923, 0.0629, 0.0122, 0.0688, -0.2374]], [[ 0.0273, -0.1082, 0.0243, -0.0924, 0.0077, 0.0359, 0.1209, 0.0545, -0.0838, 0.0139, 0.0086, -0.2110, 0.0880, -0.1371, -0.0171, 0.0332, 0.0509, -0.1481, 0.2044, -0.1747], [ 0.0087, -0.0943, 0.0111, -0.0618, -0.0376, -0.1297, 0.0497, 0.0071, -0.0905, 0.0700, -0.1282, -0.2104, 0.1350, -0.1672, 0.0697, 0.0679, 0.0512, 0.0183, 0.1531, -0.2602], [-0.0705, -0.1263, 0.0099, -0.0797, -0.1074, -0.0752, 0.1020, 0.0254, -0.1382, -0.0007, -0.0787, -0.1934, 0.1283, -0.0721, 0.1132, 0.0252, 0.0765, 0.0238, 0.1846, -0.2379]]], grad_fn=<StackBackward0>)
Questo contiene i vettori di stato nascosto nel primo strato e nel secondo strato del LSTM impilato per l'ultimo passaggio temporale in ciascuno dei 3 MTS del batch. Se si nota, lo stato nascosto del secondo strato (ultimo strato) è lo stesso dello stato nascosto all'ultimo passaggio temporale nell'output menzionato in precedenza.
Quindi, la dimensionalità di output di MTS è (time_steps, batch, hidden_size).
Questa dimensionalità di output può essere compresa dalla figura sottostante:
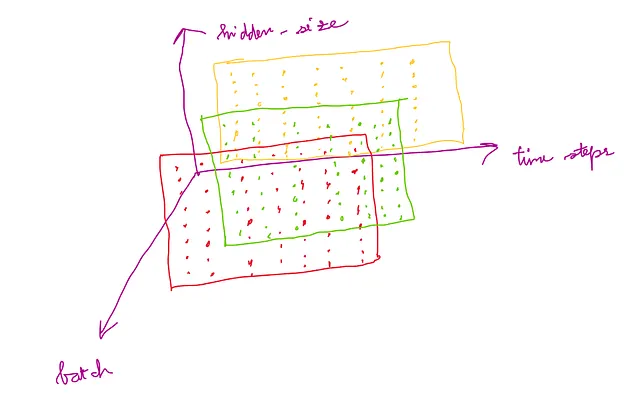
La dimensionalità di h_n: (num_layers, batch, h_out)
La dimensionalità di c_n: (num_layers, batch, hidden_size)