Pulizia dei dati con Pandas
Pulizia dati con Pandas

Introduzione
Se ti occupi di Data Science, il termine “data cleaning” potrebbe suonarti familiare. In caso contrario, permettimi di spiegarti di cosa si tratta. I nostri dati spesso provengono da diverse fonti e non sono puliti. Potrebbero contenere valori mancanti, duplicati, formati errati o indesiderati, ecc. Eseguire i tuoi esperimenti su questi dati disordinati porta a risultati errati. Pertanto, è necessario preparare i tuoi dati prima di alimentare il tuo modello. Questa preparazione dei dati mediante l’individuazione e la risoluzione degli errori potenziali, delle inesattezze e delle incongruenze è definita come Data Cleaning.
- Come diventare un analista di ricerca? Descrizione, competenze e salario
- Questo articolo sull’IA spiega come i linguaggi di programmazione possono potenziarsi reciprocamente attraverso l’ottimizzazione delle istruzioni
- Microsoft Research rilascia il quartetto heavy-metal dei compilatori di intelligenza artificiale Rammer, Roller, Welder e Grinder
In questo tutorial, ti guiderò attraverso il processo di pulizia dei dati utilizzando Pandas.
Dataset
Lavorerò con il famoso dataset Iris. Il dataset Iris contiene misurazioni di quattro caratteristiche di tre specie di fiori Iris: lunghezza del sepalo, larghezza del sepalo, lunghezza del petalo e larghezza del petalo. Utilizzeremo le seguenti librerie:
- Pandas: Potente libreria per la manipolazione e l’analisi dei dati
- Scikit-learn: Fornisce strumenti per la preelaborazione dei dati e l’apprendimento automatico
Passaggi per la Pulizia dei Dati
1. Caricamento del Dataset
Carica il dataset Iris utilizzando la funzione read_csv() di Pandas:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
Output:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
Il parametro header=0 indica che la prima riga del file CSV contiene i nomi delle colonne (header).
2. Esplora il dataset
Per ottenere informazioni sul nostro dataset, stamperemo alcune informazioni di base utilizzando le funzioni integrate in pandas
print(iris_data.info())
print(iris_data.describe())
Output:
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 150 non-null int64
1 sepal_length 150 non-null float64
2 sepal_width 150 non-null float64
3 petal_length 150 non-null float64
4 petal_width 150 non-null float64
5 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
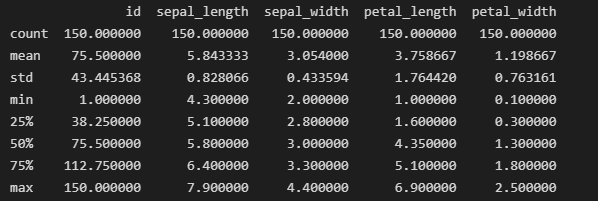
La funzione info() è utile per comprendere la struttura complessiva del data frame, il numero di valori non nulli in ogni colonna e l’utilizzo della memoria. Mentre le statistiche di riepilogo forniscono una panoramica delle caratteristiche numeriche nel tuo dataset.
3. Verifica la distribuzione delle classi
Questo è un passaggio importante per capire come le classi sono distribuite nelle colonne categoriche, il che è un compito importante per la classificazione. È possibile eseguire questo passaggio utilizzando la funzione value_counts() in pandas.
print(iris_data['species'].value_counts())
Output:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
I nostri risultati mostrano che il dataset è bilanciato con un numero uguale di rappresentazioni di ogni specie. Questo crea la base per una valutazione e un confronto equo tra tutte e 3 le classi.
4. Rimozione dei valori mancanti
Dato che è evidente dal metodo info() che abbiamo 5 colonne senza valori mancanti, salteremo questo passaggio. Ma se incontri valori mancanti, usa il seguente comando per gestirli:
iris_data.dropna(inplace=True)
5. Rimozione dei duplicati
I duplicati possono distorcere la nostra analisi, quindi li rimuoviamo dal nostro dataset. Verificheremo prima la loro esistenza utilizzando il comando seguente:
duplicate_rows = iris_data.duplicated()
print("Numero di righe duplicate:", duplicate_rows.sum())
Output:
Numero di righe duplicate: 0
Non abbiamo duplicati per questo dataset. Tuttavia, i duplicati possono essere rimossi tramite la funzione drop_duplicates().
iris_data.drop_duplicates(inplace=True)
6. Codifica one-hot
Per l’analisi categorica, eseguiremo la codifica one-hot sulla colonna delle specie. Questo passaggio viene eseguito a causa della tendenza degli algoritmi di Machine Learning a funzionare meglio con dati numerici. Il processo di codifica one-hot trasforma le variabili categoriche in un formato binario (0 o 1).
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

7. Normalizzazione delle colonne dei valori float
La normalizzazione è il processo di ridimensionamento delle caratteristiche numeriche in modo che abbiano una media di 0 e una deviazione standard di 1. Questo processo viene effettuato per garantire che le caratteristiche contribuiscano in modo equo all’analisi. Normalizzeremo le colonne dei valori float per un ridimensionamento uniforme.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
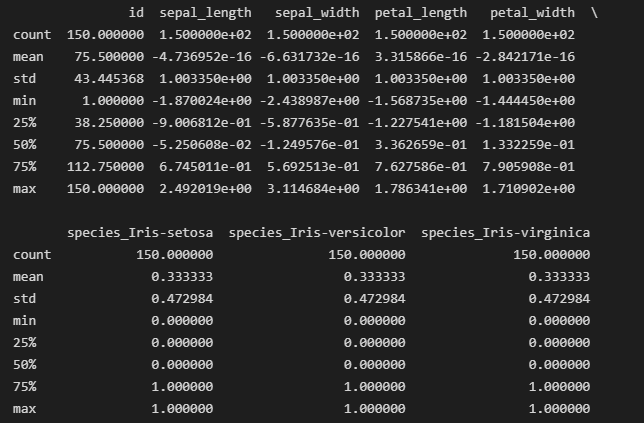
8. Salva il dataset pulito
Salva il dataset pulito nel nuovo file CSV.
iris_data.to_csv('cleaned_iris.csv', index=False)
Conclusione
Congratulazioni! Hai pulito con successo il tuo primo dataset utilizzando pandas. Potresti incontrare ulteriori sfide nel gestire dataset complessi. Tuttavia, le tecniche fondamentali menzionate qui ti aiuteranno a iniziare e a preparare i tuoi dati per l’analisi.
Kanwal Mehreen è una sviluppatrice di software in erba con un forte interesse per la scienza dei dati e le applicazioni dell’IA in medicina. Kanwal è stata selezionata come Google Generation Scholar 2022 per la regione APAC. Kanwal ama condividere conoscenze tecniche scrivendo articoli su argomenti di tendenza ed è appassionata di migliorare la rappresentazione delle donne nell’industria tecnologica.






