FMOps/LLMOps Operazionalizzare l’IA generativa e le differenze con MLOps
Operationalizing generative AI and the differences with MLOps
Oggi, la maggior parte dei nostri clienti è entusiasta dei grandi modelli linguistici (LLM) e sta pensando a come l’IA generativa potrebbe trasformare il loro business. Tuttavia, portare tali soluzioni e modelli nelle operazioni di routine aziendali non è un compito facile. In questo post, discutiamo come operazionalizzare le applicazioni di IA generativa utilizzando i principi di MLOps che portano alle operazioni del modello di base (FMOps). Inoltre, approfondiamo il caso d’uso più comune di IA generativa delle applicazioni di testo a testo e le operazioni di LLM (LLMOps), un sottoinsieme di FMOps. La figura seguente illustra gli argomenti che discutiamo.
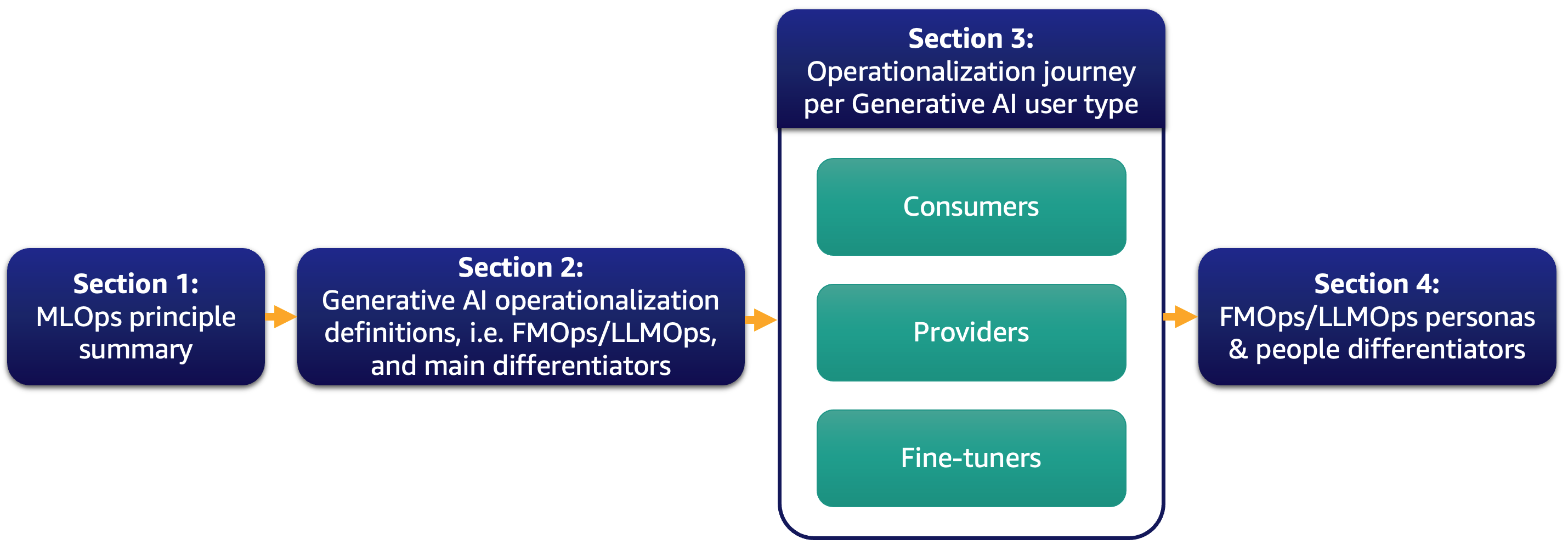
In particolare, introduciamo brevemente i principi di MLOps e ci concentriamo sulle principali differenze rispetto a FMOps e LLMOps riguardo ai processi, alle persone, alla selezione e valutazione del modello, alla privacy dei dati e al rilascio del modello. Questo si applica ai clienti che li utilizzano pronti all’uso, creano modelli di base da zero o li ottimizzano. Il nostro approccio si applica sia ai modelli open-source che a quelli proprietari allo stesso modo.
Sommario dell’operazionalizzazione di ML
Come definito nel post MLOps foundation roadmap for enterprises with Amazon SageMaker, ML e operations (MLOps) è la combinazione di persone, processi e tecnologia per rendere efficienti le soluzioni di machine learning (ML). Per raggiungere questo obiettivo, è necessaria una combinazione di team e persone che collaborano, come illustrato nella figura seguente.
- Potenziare l’esperienza di generazione di AI Introduzione del supporto di streaming in Amazon SageMaker hosting
- Come sopravvivere nel mondo dell’IA? Il tuo lavoro è a rischio?
- AI generativa innovare in modo etico e creativo per un trasferimento dati senza soluzione di continuità
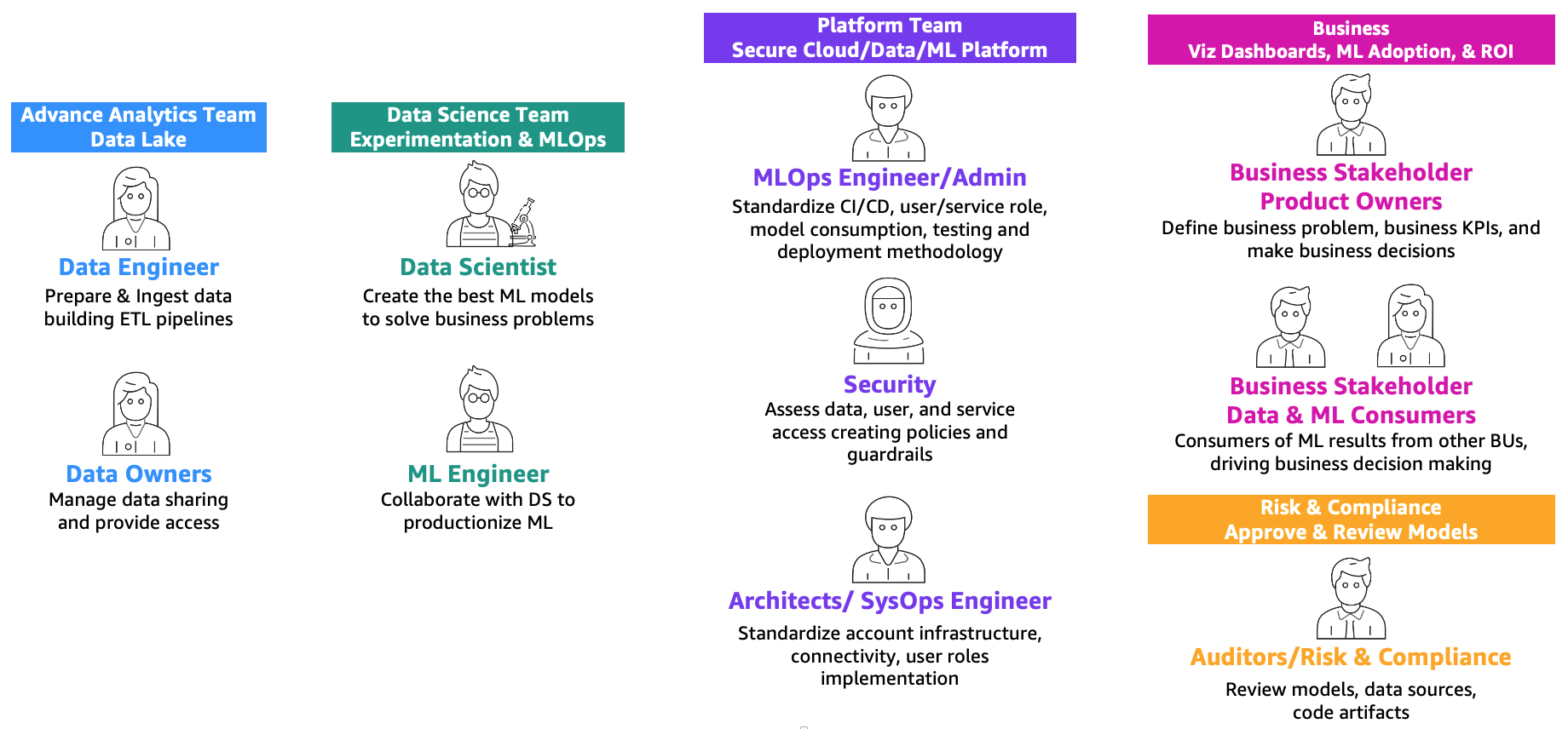
Questi team sono i seguenti:
- Team di analisi avanzata (data lake e data mesh) – Gli ingegneri dei dati sono responsabili della preparazione e dell’ingestione dei dati da diverse fonti, della costruzione dei pipeline ETL (extract, transform, and load) per curare e catalogare i dati e della preparazione dei dati storici necessari per i casi d’uso di ML. Questi proprietari dei dati si concentrano sulla fornitura di accesso ai loro dati a più unità o team aziendali.
- Team di data science – I data scientist devono concentrarsi sulla creazione del miglior modello basato su indicatori chiave di prestazione (KPI) predefiniti lavorando su notebook. Dopo il completamento della fase di ricerca, i data scientist devono collaborare con gli ingegneri di ML per creare automatizzazioni per la costruzione (ML pipelines) e il rilascio dei modelli in produzione utilizzando i pipeline CI/CD (Continuous Integration/Continuous Deployment).
- Team aziendale – Un product owner è responsabile della definizione del caso aziendale, dei requisiti e dei KPI da utilizzare per valutare le prestazioni del modello. I consumatori di ML sono altri stakeholder aziendali che utilizzano i risultati dell’inferenza (previsioni) per prendere decisioni.
- Team di piattaforma – Gli architetti sono responsabili dell’architettura cloud complessiva dell’azienda e di come tutti i diversi servizi sono collegati tra loro. Gli esperti di sicurezza esaminano l’architettura in base alle politiche e alle esigenze di sicurezza aziendale. Gli ingegneri di MLOps sono responsabili di fornire un ambiente sicuro per i data scientist e gli ingegneri di ML per rendere operative in produzione i casi d’uso di ML. In particolare, sono responsabili della standardizzazione dei pipeline CI/CD, dei ruoli utente e dei servizi e della creazione di contenitori, del consumo del modello, dei test e della metodologia di rilascio in base ai requisiti aziendali e di sicurezza.
- Team di rischio e conformità – Per ambienti più restrittivi, gli ispettori sono responsabili della valutazione dei dati, del codice e degli artefatti del modello e si assicurano che l’azienda sia conforme alle normative, come la privacy dei dati.
Si noti che una stessa persona può coprire più ruoli a seconda della dimensione e della maturità di MLOps dell’azienda.
Queste persone hanno bisogno di ambienti dedicati per svolgere i diversi processi, come illustrato nella figura seguente.
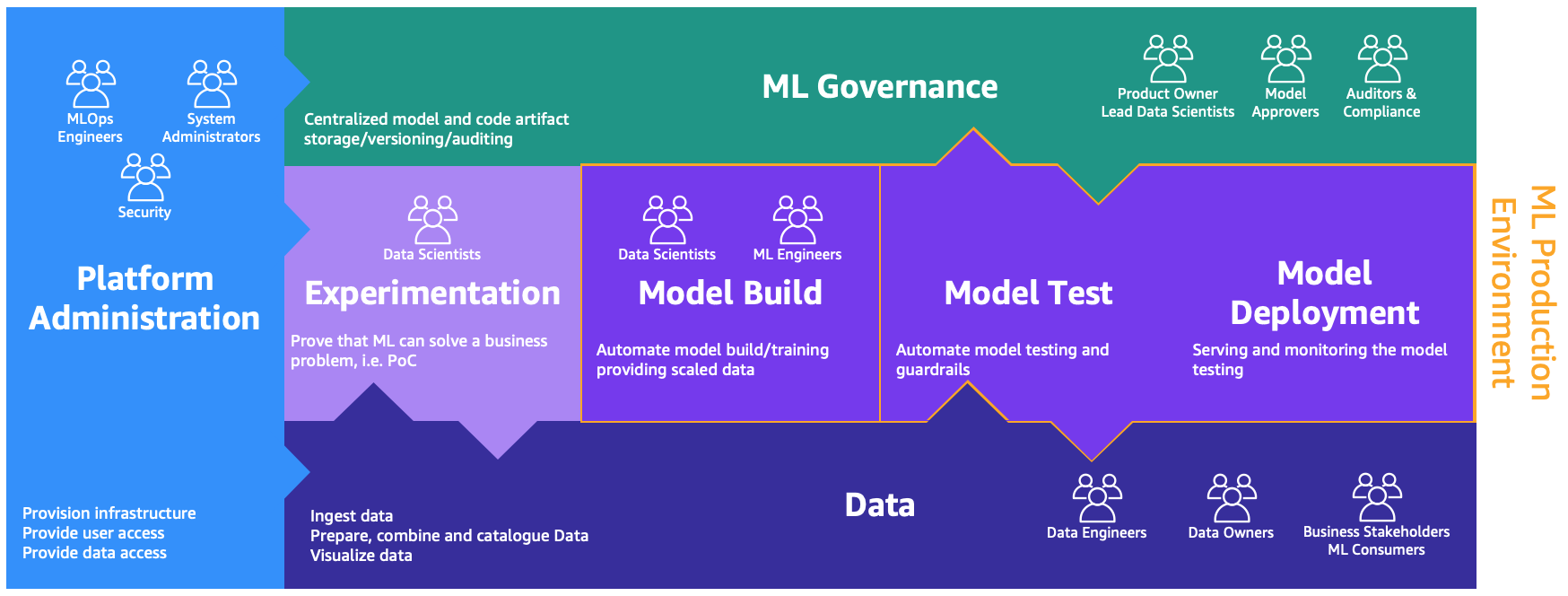
Gli ambienti sono i seguenti:
- Amministrazione della piattaforma – L’ambiente di amministrazione della piattaforma è il luogo in cui il team della piattaforma ha accesso per creare account AWS e collegare gli utenti e i dati corretti.
- Dati – Il livello dei dati, spesso noto come data lake o data mesh, è l’ambiente in cui gli ingegneri o i proprietari dei dati e gli stakeholder aziendali utilizzano per preparare, interagire e visualizzare i dati.
- Sperimentazione – I data scientist utilizzano un ambiente di sandbox o sperimentazione per testare nuove librerie e tecniche di ML per dimostrare che il loro proof of concept può risolvere i problemi aziendali.
- Costruzione del modello, test del modello, distribuzione del modello – L’ambiente di costruzione, test e distribuzione del modello è il livello di MLOps, in cui i data scientist e gli ingegneri di ML collaborano per automatizzare e spostare la ricerca in produzione.
- Governance di ML – L’ultimo pezzo del puzzle è l’ambiente di governance di ML, in cui tutti gli artefatti del modello e del codice vengono archiviati, esaminati e auditati dalle persone corrispondenti.
Il diagramma seguente illustra l’architettura di riferimento, che è già stata discussa nella roadmap di fondazione MLOps per le aziende con Amazon SageMaker.
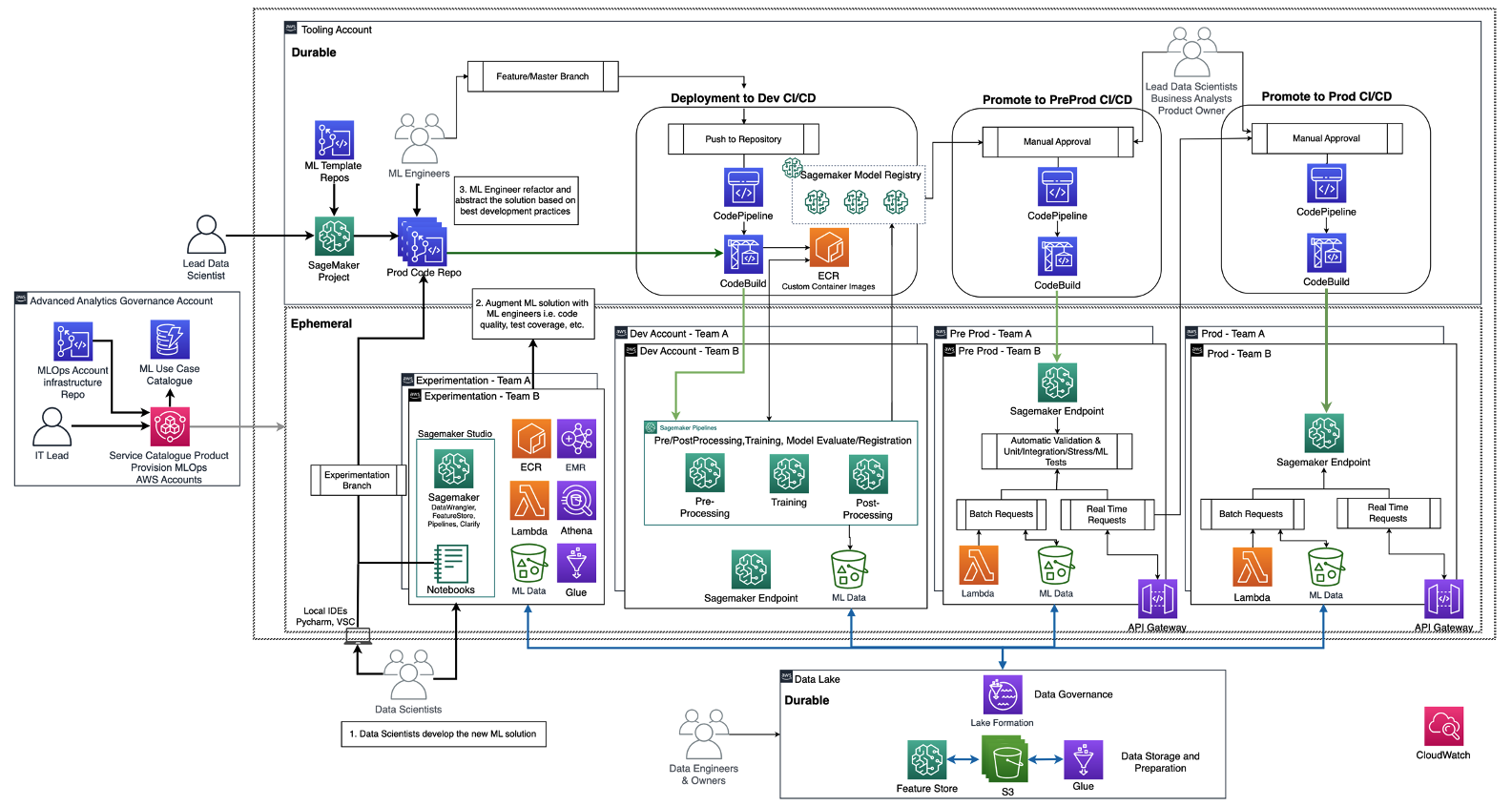
Ogni unità aziendale ha il proprio set di account di sviluppo (addestramento e costruzione automatizzati del modello), pre-produzione (test automatici) e produzione (deploy e servizio del modello) per industrializzare i casi d’uso di ML, che recuperano i dati da un data lake centralizzato o decentralizzato. Tutti i modelli prodotti e l’automazione del codice sono memorizzati in un account strumentale centralizzato utilizzando la funzionalità di un registro dei modelli. Il codice di infrastruttura per tutti questi account è versionato in un account di servizio condiviso (account di governance di analisi avanzata) che il team della piattaforma può astrarre, templetizzare, mantenere e riutilizzare per l’onboarding alla piattaforma MLOps di ogni nuovo team.
Definizioni di generative AI e differenze rispetto a MLOps
Nel ML classico, la combinazione precedente di persone, processi e tecnologia può aiutarti a produrre i tuoi casi d’uso di ML. Tuttavia, nella generative AI, la natura dei casi d’uso richiede l’estensione di tali capacità o nuove capacità. Una di queste nuove nozioni è il modello fondamentale (FM). Sono chiamati così perché possono essere utilizzati per creare una vasta gamma di altri modelli di intelligenza artificiale, come illustrato nella figura seguente.
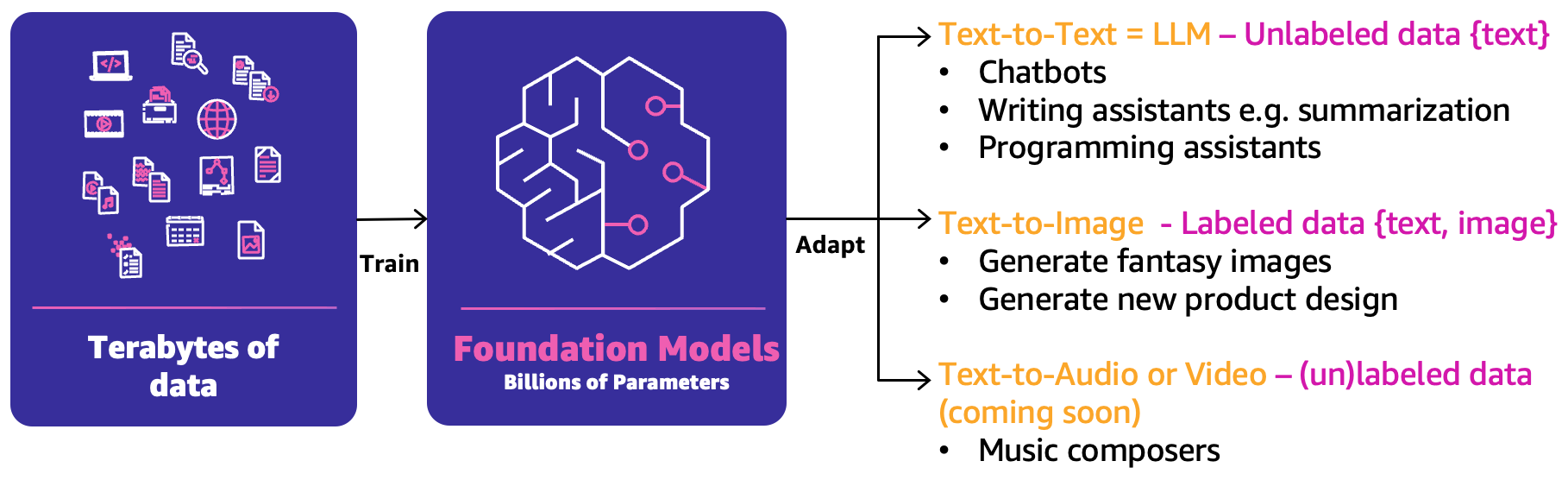
FM è stato addestrato sulla base di terabyte di dati e ha centinaia di miliardi di parametri per essere in grado di predire la prossima migliore risposta basata su tre principali categorie di casi d’uso di generative AI:
- Testo-testo – Gli FM (LLM) sono stati addestrati sulla base di dati non etichettati (come testo libero) e sono in grado di predire la prossima migliore parola o sequenza di parole (paragrafi o lunghi saggi). I principali casi d’uso riguardano chatbot simili a umani, sintesi o altre creazioni di contenuti come il codice di programmazione.
- Testo-immagine – Sono stati utilizzati dati etichettati, come coppie di <testo, immagine>, per addestrare gli FM, che sono in grado di predire la migliore combinazione di pixel. Esempi di casi d’uso sono la generazione di design di abbigliamento o immagini personalizzate immaginarie.
- Testo-audio o video – Sia dati etichettati che non etichettati possono essere utilizzati per l’addestramento di FM. Un esempio principale di caso d’uso di generative AI è la composizione musicale.
Per industrializzare questi casi d’uso di generative AI, dobbiamo prendere in prestito ed estendere il dominio MLOps per includere quanto segue:
- Operazioni del modello fondamentale (FMOps) – Questo può industrializzare soluzioni di generative AI, inclusi tutti i tipi di casi d’uso
- Operazioni del modello di linguaggio fondamentale (LLMOps) – Questo è un sottoinsieme di FMOps che si concentra sulla produzione di soluzioni basate su LLM, come il testo-testo
La figura seguente illustra l’intersezione di questi casi d’uso.
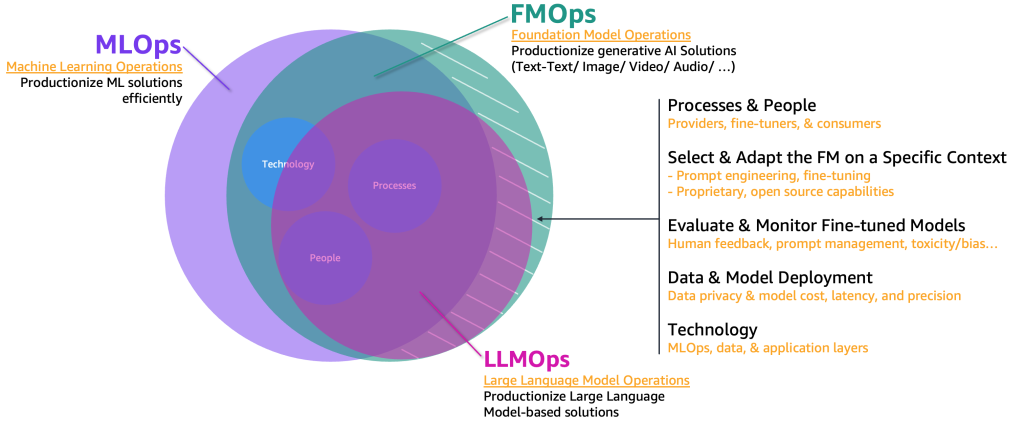
Rispetto al ML classico e a MLOps, FMOps e LLMOps differiscono in base a quattro principali categorie che copriremo nelle sezioni seguenti: persone e processi, selezione e adattamento di FM, valutazione e monitoraggio di FM, privacy dei dati e distribuzione del modello, e bisogni tecnologici. Il monitoraggio sarà trattato in un post separato.
Percorso di operationalization per tipo di utente di generative AI
Per semplificare la descrizione dei processi, dobbiamo categorizzare i principali tipi di utenti di generative AI, come mostrato nella figura seguente.
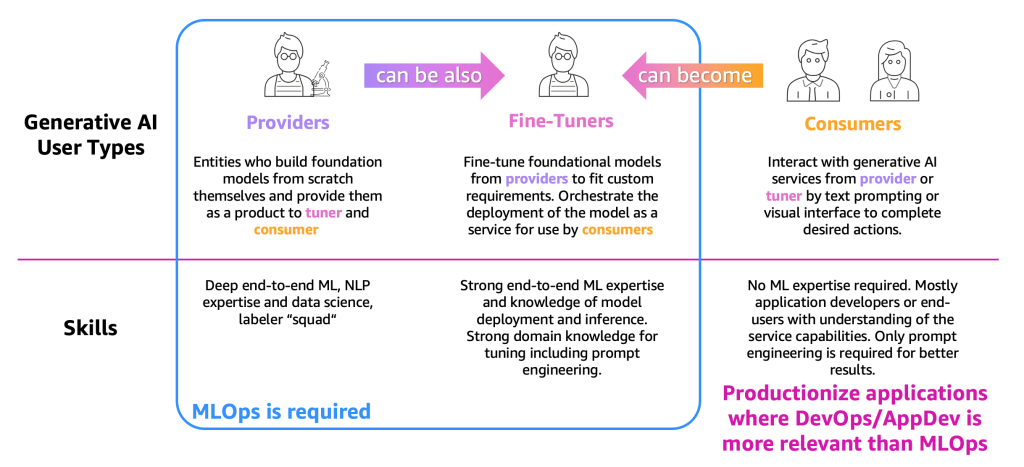
Le tipologie di utenti sono le seguenti:
- Provider – Utenti che costruiscono FM da zero e le offrono come prodotto ad altri utenti (fine-tuner e consumatori). Hanno una profonda competenza in ML end-to-end e nell’elaborazione del linguaggio naturale (NLP), nonché competenze in scienze dei dati e squadre di etichettatori ed editor di dati massicci.
- Fine-tuner – Utenti che riallenano (fine-tuning) le FM dei provider per adattarle alle esigenze personalizzate. Coordinano il rilascio del modello come servizio per l’uso da parte dei consumatori. Questi utenti hanno bisogno di solide competenze in ML end-to-end e scienze dei dati e di conoscenze sul rilascio e l’inferenza del modello. È necessaria anche una solida conoscenza del dominio per l’ottimizzazione, compresa l’ingegneria delle prompt.
- Consumatori – Utenti che interagiscono con i servizi di IA generativi forniti dai provider o dai fine-tuner tramite prompt di testo o un’interfaccia visiva per completare azioni desiderate. Non è richiesta competenza in ML, ma principalmente sviluppatori di applicazioni o utenti finali con una comprensione delle capacità del servizio. È necessaria solo l’ingegneria delle prompt per ottenere risultati migliori.
In base alla definizione e alle competenze ML richieste, MLOps è richiesto principalmente per i provider e i fine-tuner, mentre i consumatori possono utilizzare i principi di produzione delle applicazioni, come DevOps e AppDev, per creare le applicazioni di IA generative. Inoltre, abbiamo osservato un movimento tra le tipologie di utenti, in cui i provider potrebbero diventare fine-tuner per supportare casi d’uso basati su un settore specifico (come il settore finanziario) o i consumatori potrebbero diventare fine-tuner per ottenere risultati più accurati. Ma osserviamo i processi principali per ogni tipologia di utente.
Il percorso dei consumatori
La figura seguente illustra il percorso dei consumatori.
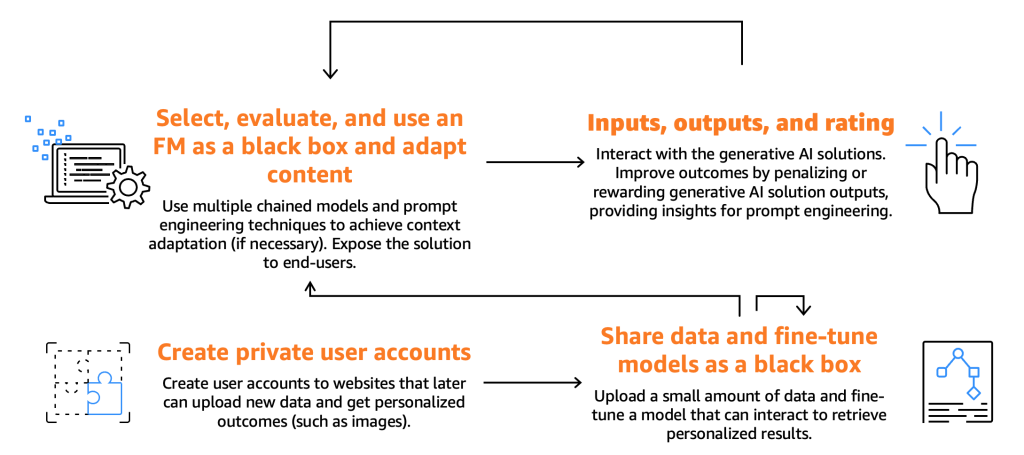
Come già accennato, i consumatori devono selezionare, testare e utilizzare una FM, interagendo con essa fornendo input specifici, noti come prompt. I prompt, nel contesto della programmazione informatica e dell’IA, si riferiscono all’input fornito a un modello o a un sistema per generare una risposta. Ciò può essere sotto forma di testo, comando o domanda, che il sistema utilizza per elaborare e generare un output. L’output generato dalla FM può quindi essere utilizzato dagli utenti finali, che dovrebbero anche essere in grado di valutare questi output per migliorare le future risposte del modello.
Oltre a questi processi fondamentali, abbiamo notato che i consumatori esprimono il desiderio di perfezionare un modello sfruttando le funzionalità offerte dai fine-tuner. Ad esempio, su un sito web che genera immagini, gli utenti finali possono creare account privati, caricare foto personali e successivamente generare contenuti correlati a quelle immagini (ad esempio, generare un’immagine che rappresenti l’utente finale su una moto brandendo una spada o situato in una località esotica). In questo scenario, l’applicazione di IA generativa, progettata dal consumatore, deve interagire con il backend del fine-tuner tramite API per fornire questa funzionalità agli utenti finali.
Tuttavia, prima di approfondire questo aspetto, concentriamoci sul percorso di selezione del modello, test, utilizzo, interazione input-output e valutazione, come mostrato nella figura seguente.
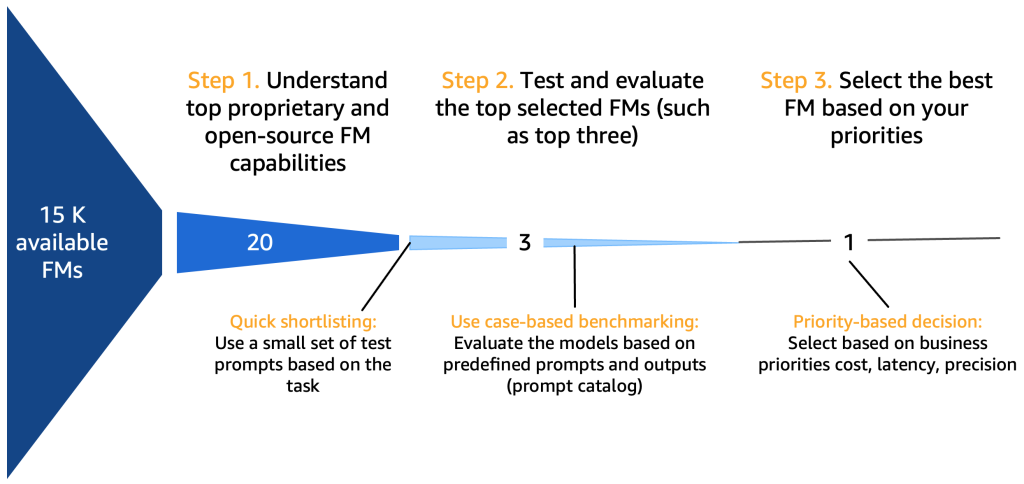
*15K FM di riferimento disponibili
Step 1. Comprendere le capacità principali delle FM
Ci sono molte dimensioni che devono essere prese in considerazione nella selezione dei modelli di base, a seconda del caso d’uso, dei dati disponibili, delle normative, ecc. Una buona checklist, sebbene non esaustiva, potrebbe essere la seguente:
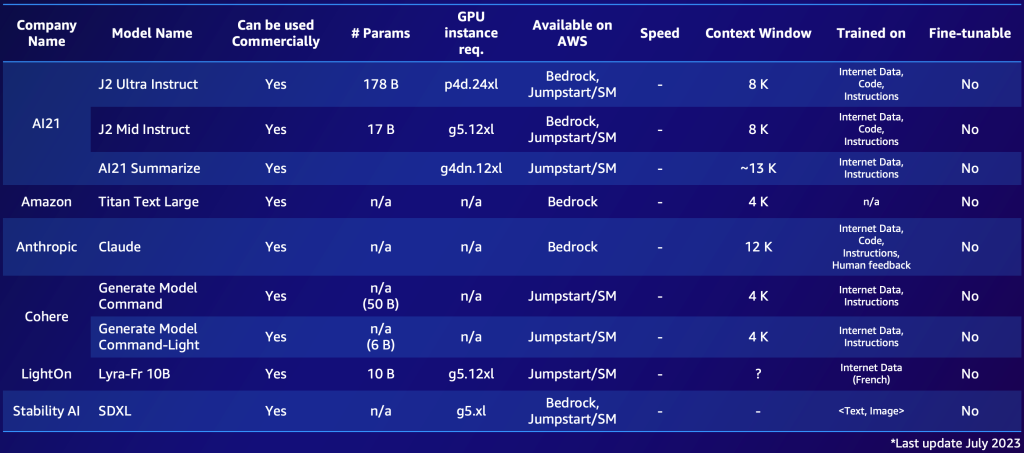
- FM proprietario o open-source – I modelli proprietari spesso comportano un costo finanziario, ma offrono generalmente prestazioni migliori (in termini di qualità del testo o dell’immagine generata), essendo sviluppati e mantenuti da team dedicati di fornitori di modelli che garantiscono prestazioni e affidabilità ottimali. D’altra parte, osserviamo anche l’adozione di modelli open-source che, oltre ad essere gratuiti, offrono vantaggi aggiuntivi come l’accessibilità e la flessibilità (ad esempio, ogni modello open-source è fine-tunable). Un esempio di modello proprietario è il modello Claude di Anthropic, e un esempio di modello open-source ad alte prestazioni è Falcon-40B, a partire da luglio 2023.
- Licenza commerciale – Le considerazioni relative alla licenza sono cruciali nella scelta di un FM. È importante notare che alcuni modelli sono open-source ma non possono essere utilizzati per scopi commerciali, a causa di restrizioni o condizioni di licenza. Le differenze possono essere sottili: ad esempio, il modello xgen-7b-8k-base appena rilasciato è open source e utilizzabile a scopo commerciale (licenza Apache-2.0), mentre la versione fine-tuned del modello xgen-7b-8k-inst è stata rilasciata solo per scopi di ricerca. Quando si seleziona un FM per un’applicazione commerciale, è essenziale verificare l’accordo di licenza, comprenderne i limiti e assicurarsi che sia in linea con l’uso previsto del progetto.
- Parametri – Il numero di parametri, che consistono nei pesi e nei bias nella rete neurale, è un altro fattore chiave. Più parametri significa generalmente un modello più complesso e potenzialmente potente, in quanto può catturare pattern e correlazioni più intricate nei dati. Tuttavia, il compromesso è che richiede più risorse computazionali e, quindi, costa di più in termini di esecuzione. Inoltre, osserviamo una tendenza verso modelli più piccoli, soprattutto nello spazio open-source (modelli che vanno da 7 a 40 miliardi) che si comportano bene, specialmente quando vengono raffinati.
- Velocità – La velocità di un modello è influenzata dalla sua dimensione. I modelli più grandi tendono a elaborare i dati più lentamente (latenza più elevata) a causa della maggiore complessità computazionale. Pertanto, è fondamentale bilanciare la necessità di un modello con un’elevata capacità predittiva (spesso modelli più grandi) con i requisiti pratici di velocità, specialmente nelle applicazioni, come i chatbot, che richiedono risposte in tempo reale o quasi reali.
- Dimensione della finestra di contesto (numero di token) – La finestra di contesto, definita dal numero massimo di token che possono essere inseriti o restituiti per prompt, è cruciale per determinare quanto contesto il modello può considerare contemporaneamente (un token corrisponde approssimativamente a 0,75 parole per l’inglese). I modelli con finestre di contesto più ampie possono comprendere e generare sequenze di testo più lunghe, cosa che può essere utile per compiti che coinvolgono conversazioni o documenti più lunghi.
- Training dataset – È importante anche comprendere
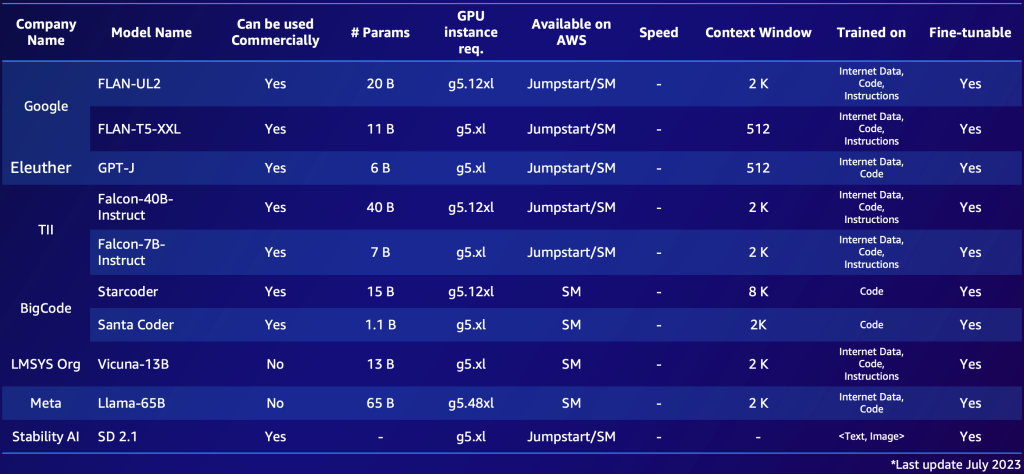
Di seguito è riportato un esempio di due elenchi, uno per i modelli proprietari e uno per i modelli open-source. Potresti compilare tabelle simili in base alle tue esigenze specifiche per ottenere una panoramica rapida delle opzioni disponibili. Nota che le prestazioni e i parametri di questi modelli cambiano rapidamente e potrebbero essere obsoleti al momento della lettura, mentre altre capacità potrebbero essere importanti per i clienti specifici, come la lingua supportata.
Di seguito è riportato un esempio di FMs proprietari notevoli disponibili su AWS (luglio 2023).
Di seguito è riportato un esempio di FMs open-source notevoli disponibili su AWS (luglio 2023).
Dopo aver compilato una panoramica di 10-20 modelli candidati potenziali, diventa necessario affinare ulteriormente questo elenco. In questa sezione, proponiamo un meccanismo rapido che fornirà due o tre modelli finali validi come candidati per il prossimo round.
Il diagramma seguente illustra il processo di selezione iniziale.
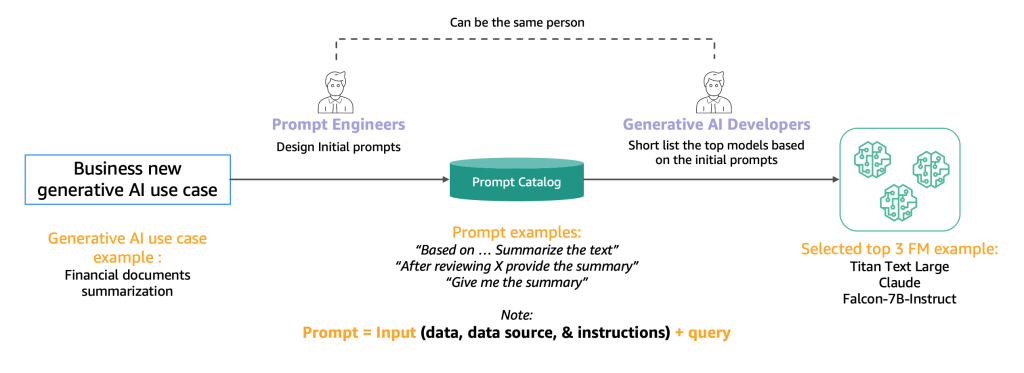
Tipicamente, gli ingegneri delle prompt, esperti nella creazione di prompt di alta qualità che consentono ai modelli di intender e elaborare gli input degli utenti, sperimentano con vari metodi per svolgere lo stesso compito (come la sintesi) su un modello. Suggeriamo che questi prompt non siano creati al volo, ma siano estratti in modo sistematico da un catalogo di prompt. Questo catalogo di prompt è un luogo centrale per memorizzare i prompt al fine di evitare duplicazioni, consentire il controllo delle versioni e condividere i prompt all’interno del team per garantire coerenza tra i diversi tester di prompt nelle diverse fasi di sviluppo, che introduciamo nella prossima sezione. Questo catalogo di prompt è analogo a un repository Git di un feature store. Lo sviluppatore di AI generativa, che potrebbe essere la stessa persona dell’ingegnere delle prompt, deve quindi valutare l’output per determinare se sarebbe adatto all’applicazione di AI generativa che sta cercando di sviluppare.
Passaggio 2. Test e valutazione del top FM
Dopo che l’elenco è stato ridotto a circa tre FMs, consigliamo un passaggio di valutazione per testare ulteriormente le capacità dei FMs e la loro idoneità per il caso d’uso. A seconda della disponibilità e della natura dei dati di valutazione, suggeriamo diversi metodi, come illustrato nella figura seguente.
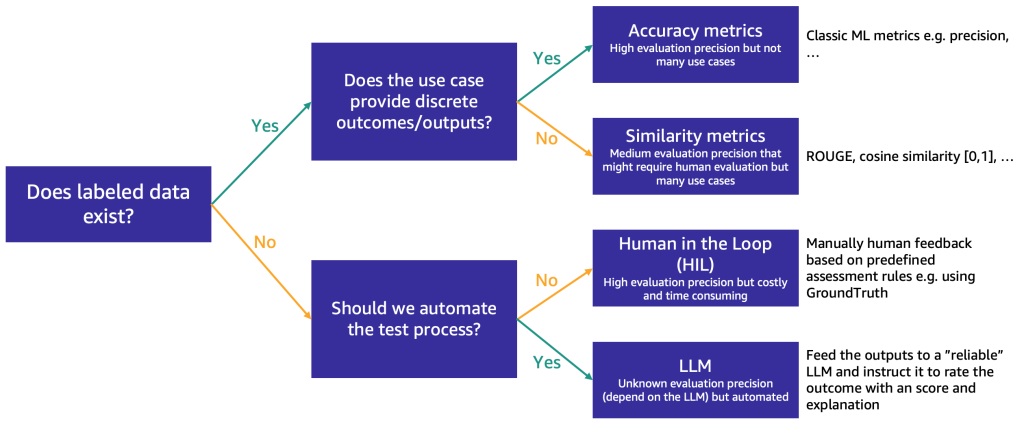
Il metodo da utilizzare prima dipende dal fatto che si disponga o meno di dati di test con etichette.
Se si dispone di dati con etichette, è possibile utilizzarli per effettuare una valutazione del modello, come facciamo con i modelli tradizionali di ML (inserendo alcuni campioni e confrontando l’output con le etichette). A seconda che i dati di test abbiano etichette discrete (come analisi del sentiment positive, negative o neutre) o siano testo non strutturato (come sintesi), proponiamo diversi metodi di valutazione:
- Metriche di accuratezza – Nel caso di output discreti (come analisi del sentiment), è possibile utilizzare metriche di accuratezza standard come precisione, richiamo e punteggio F1
- Metriche di similarità – Se l’output è non strutturato (come una sintesi), suggeriamo metriche di similarità come ROUGE e similarità del coseno
Alcuni casi d’uso non si prestano a avere una risposta univoca (ad esempio, “Crea una breve storia per bambini per mia figlia di 5 anni”). In tali casi, diventa più difficile valutare i modelli perché non si dispone di dati di test con etichette. Proponiamo due approcci, a seconda dell’importanza della revisione umana del modello rispetto alla valutazione automatizzata:
- Human-in-the-Loop (HIL) – In questo caso, un team di tester di prompt rivedrà le risposte di un modello. A seconda dell’importanza dell’applicazione, i tester di prompt potrebbero rivedere il 100% delle risposte del modello o solo un campione.
- Valutazione basata su LLM – In questo scenario, i tester di prompt sono sostituiti da un LLM, idealmente uno più potente (sebbene forse più lento e costoso) rispetto a quelli in fase di test. L’LLM rivedrà tutte le risposte generate dal modello e le valuterà. Questo metodo potrebbe comportare una qualità inferiore, ma è un’opzione di valutazione più economica e veloce che potrebbe fornire una buona valutazione iniziale delle prestazioni dei modelli.
Ad esempio, possiamo utilizzare il seguente prompt di esempio per un LLM, che include la query di input, la risposta del LLM e le istruzioni: “Desideriamo richiedere il tuo feedback sulle prestazioni di un assistente AI in risposta alla domanda dell’utente mostrata sopra. Ti preghiamo di valutare l’utilità, la pertinenza, l’accuratezza e il livello di dettaglio della risposta dell’assistente. L’assistente riceverà un punteggio complessivo su una scala da 1 a 10, dove un punteggio più alto indica una migliore performance complessiva”.
Questo prompt verrà inviato a un altro LLM (l’EvalLLM) per la valutazione. Di seguito è riportato un esempio in cui la risposta del modello Falcon-40B è stata valutata da un EvalLLM (in questo caso Claude). Utilizziamo la domanda “Cosa succederebbe se il Canale di Suez non fosse mai stato costruito?”. La risposta è la seguente:
Domanda: Cosa succederebbe se il Canale di Suez non fosse mai stato costruito?
falcon-40b-instruct
Se il Canale di Suez non fosse mai stato costruito, le navi dovrebbero viaggiare attorno all’Africa per navigare tra il Mediterraneo e il Mar Rosso. Ciò comporterebbe un significativo aumento di tempo e distanza del viaggio, rendendolo meno efficiente e più costoso. Inoltre, senza il Canale di Suez, molti paesi del Medio Oriente e del Nord Africa sarebbero stati molto meno connessi al resto del mondo, ostacolando lo sviluppo economico e culturale.
Recensione (Punteggio: 9/10)
La risposta dell’assistente è molto pertinente, precisa e dettagliata. Fornisce una risposta eccellente alla domanda ipotetica dell’utente sulla non esistenza del Canale di Suez. L’assistente sottolinea correttamente le implicazioni sul viaggio marittimo e l’impatto economico e culturale sul Medio Oriente e il Nord Africa. Tuttavia, avrebbe potuto approfondire ulteriormente le implicazioni geopolitiche o l’impatto sui modelli di commercio globale per una risposta più completa.
La seguente figura illustra un esempio di processo di valutazione end-to-end.
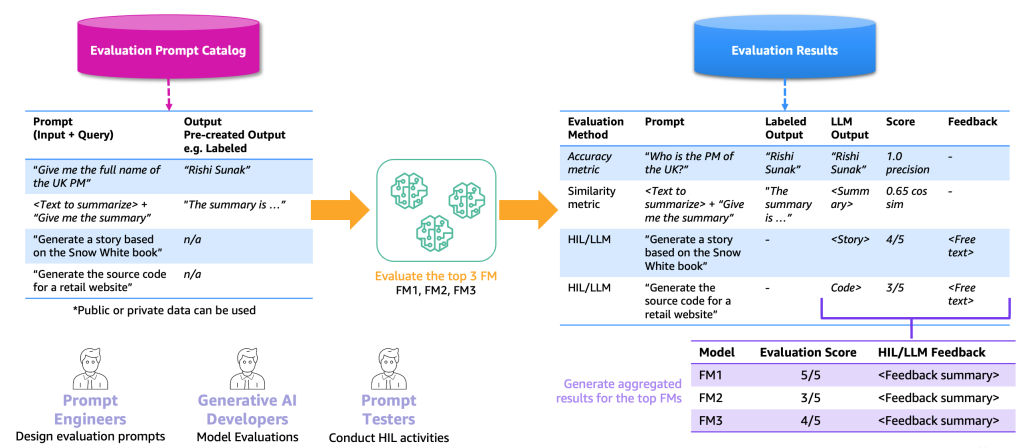
Basandoci su questo esempio, per effettuare la valutazione, dobbiamo fornire i prompt di esempio, che conserviamo nel catalogo dei prompt, e un dataset di valutazione etichettato o non etichettato basato sulle nostre specifiche applicazioni. Ad esempio, con un dataset di valutazione etichettato, possiamo fornire prompt (input e query) come “Dammi il nome completo del primo ministro del Regno Unito nel 2023” e output e risposte, come “Rishi Sunak”. Con un dataset non etichettato, forniamo solo la domanda o l’istruzione, come “Genera il codice sorgente per un sito web di vendita al dettaglio”. Chiamiamo la combinazione di catalogo dei prompt e dataset di valutazione il catalogo dei prompt di valutazione. Il motivo per cui differenziamo il catalogo dei prompt e il catalogo dei prompt di valutazione è perché quest’ultimo è dedicato a un caso d’uso specifico anziché a prompt e istruzioni generici (come la risposta a una domanda) che il catalogo dei prompt contiene.
Con questo catalogo dei prompt di valutazione, il passo successivo è alimentare i prompt di valutazione ai migliori FMs. Il risultato è un dataset di risultati di valutazione che contiene i prompt, gli output di ciascun FM e l’output etichettato insieme a un punteggio (se esiste). Nel caso di un catalogo di prompt di valutazione non etichettato, c’è un passaggio aggiuntivo per un HIL o LLM per rivedere i risultati e fornire un punteggio e un feedback (come descritto in precedenza). Il risultato finale saranno risultati aggregati che combinano i punteggi di tutti gli output (calcolando la precisione media o la valutazione umana) e consentono agli utenti di valutare la qualità dei modelli.
Dopo che i risultati della valutazione sono stati raccolti, proponiamo di scegliere un modello in base a diversi criteri. Questi di solito si riducono a fattori come precisione, velocità e costo. La seguente figura mostra un esempio.
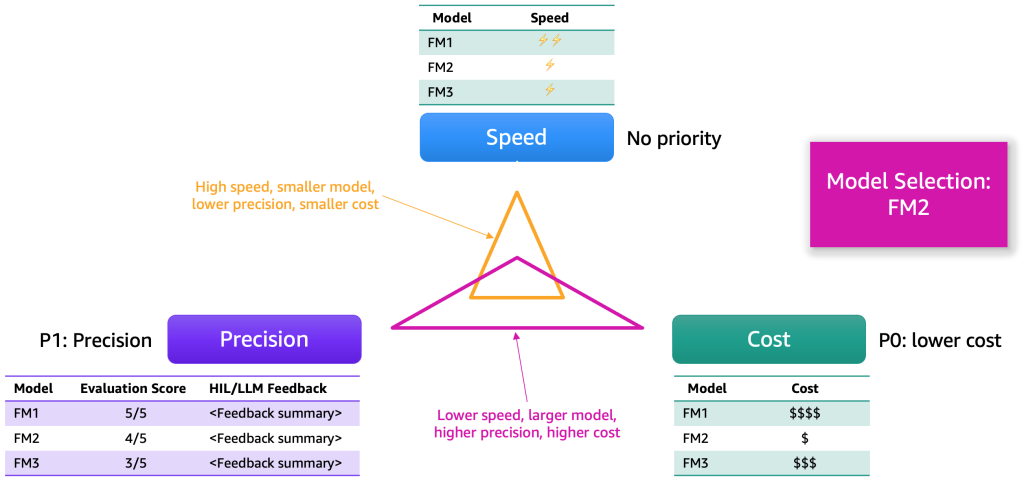
Ogni modello avrà punti di forza e compromessi in base a queste dimensioni. A seconda del caso d’uso, dovremmo assegnare priorità diverse a queste dimensioni. Nell’esempio precedente, abbiamo scelto di dare la massima priorità al costo, seguito dalla precisione e poi dalla velocità. Anche se è più lento e non efficiente come FM1, rimane sufficientemente efficace e significativamente più economico da ospitare. Di conseguenza, potremmo selezionare FM2 come scelta migliore.
Passaggio 3. Sviluppare il backend e il frontend dell’applicazione AI generativa
A questo punto, gli sviluppatori di IA generativa hanno selezionato il giusto FM per l’applicazione specifica con l’aiuto degli ingegneri e dei tester delle istruzioni. Il passo successivo è iniziare lo sviluppo dell’applicazione di IA generativa. Abbiamo separato lo sviluppo dell’applicazione di IA generativa in due livelli, un backend e un front end, come mostrato nella seguente figura.
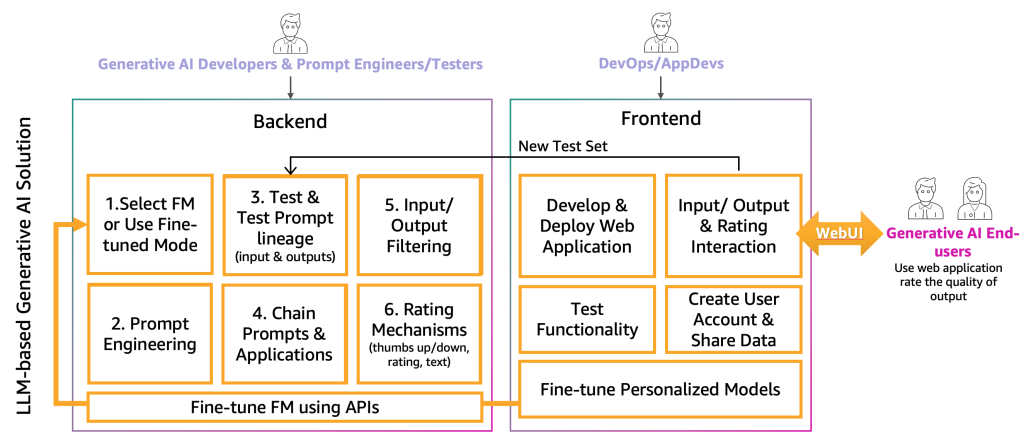
Nel backend, gli sviluppatori di IA generativa incorporano il FM selezionato nelle soluzioni e lavorano insieme agli ingegneri delle istruzioni per creare l’automazione per trasformare l’input dell’utente finale in istruzioni FM appropriate. I tester delle istruzioni creano le voci necessarie per il catalogo delle istruzioni per il testing automatico o manuale (HIL o LLM). Successivamente, gli sviluppatori di IA generativa creano il chaining delle istruzioni e il meccanismo dell’applicazione per fornire l’output finale. Il chaining delle istruzioni, in questo contesto, è una tecnica per creare applicazioni LLM più dinamiche e consapevoli del contesto. Funziona suddividendo un compito complesso in una serie di sotto-compiti più piccoli e gestibili. Ad esempio, se chiediamo a un LLM la domanda “Dove è nato il primo ministro del Regno Unito e quanto dista quel luogo da Londra”, il compito può essere suddiviso in istruzioni individuali, dove un’istruzione potrebbe essere costruita in base alla risposta di una valutazione precedente, come “Chi è il primo ministro del Regno Unito”, “Qual è il suo luogo di nascita” e “Quanto dista quel luogo da Londra?”. Per garantire una certa qualità di input e output, gli sviluppatori di IA generativa devono anche creare il meccanismo per monitorare e filtrare gli input dell’utente finale e gli output dell’applicazione. Ad esempio, se l’applicazione LLM deve evitare richieste e risposte tossiche, potrebbero applicare un rilevatore di tossicità per l’input e l’output e filtrarli. Infine, devono fornire un meccanismo di valutazione, che supporterà l’aumento del catalogo delle istruzioni di valutazione con esempi positivi e negativi. Una rappresentazione più dettagliata di questi meccanismi verrà presentata in futuri articoli.
Per fornire la funzionalità all’utente finale dell’IA generativa, è necessario lo sviluppo di un sito web front-end che interagisca con il backend. Pertanto, le persone di DevOps e AppDevs (sviluppatori di applicazioni sul cloud) devono seguire le migliori pratiche di sviluppo per implementare la funzionalità di input/output e valutazione.
Oltre a questa funzionalità di base, il front-end e il back-end devono incorporare la funzione di creazione di account utente personali, caricamento di dati, avvio del fine-tuning come una scatola nera e utilizzo del modello personalizzato invece del FM di base. La produzione di un’applicazione di IA generativa è simile a un’applicazione normale. La figura seguente rappresenta un’architettura di esempio.
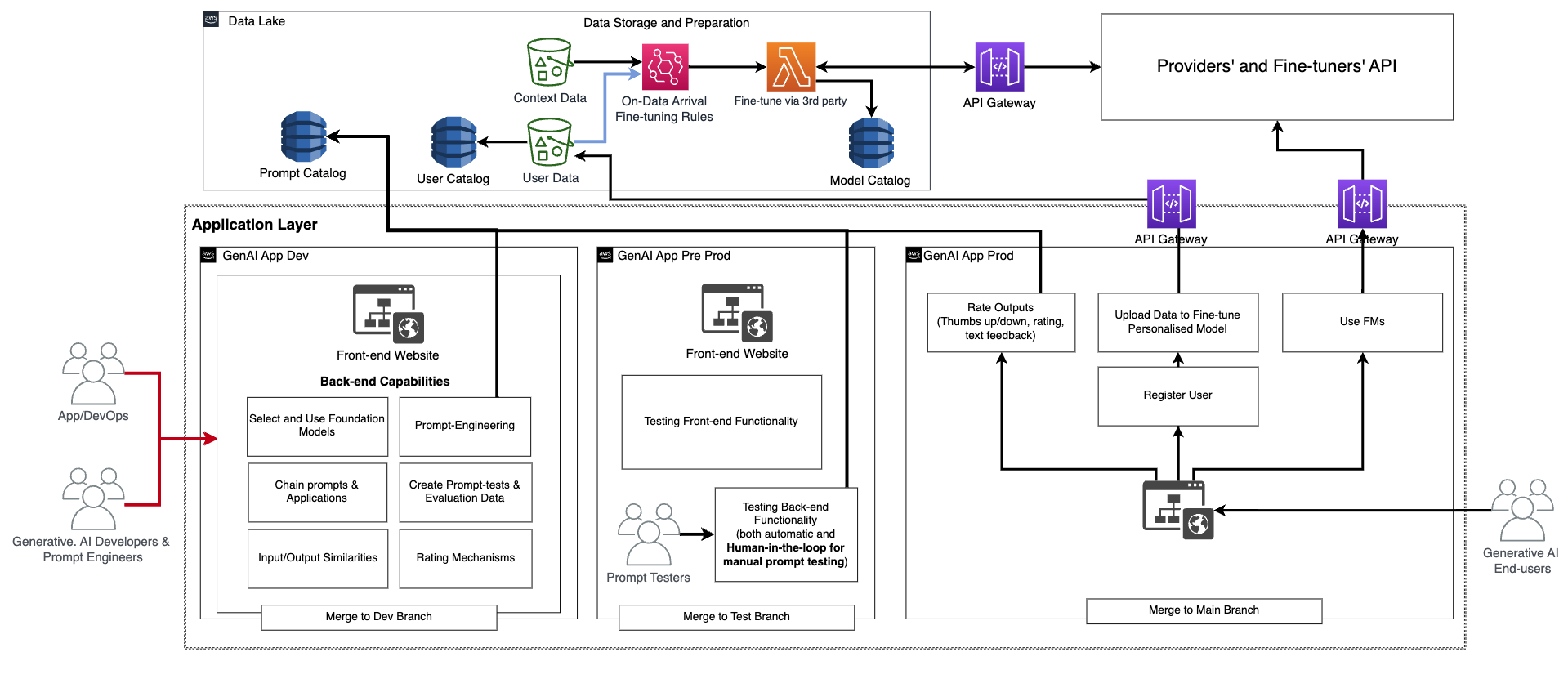
In questa architettura, gli sviluppatori di IA generativa, gli ingegneri delle istruzioni e i DevOps o gli AppDevs creano e testano l’applicazione manualmente distribuendola tramite CI/CD in un ambiente di sviluppo (generative AI App Dev nella figura precedente) utilizzando repository di codice dedicati e unendo al branch di sviluppo. In questa fase, gli sviluppatori di IA generativa utilizzeranno il FM corrispondente chiamando l’API come è stato fornito dai fornitori di fine-tuning del FM. Successivamente, per testare l’applicazione in modo estensivo, devono promuovere il codice al branch di test, che attiverà la distribuzione tramite CI/CD nell’ambiente di pre-produzione (generative AI App Pre-prod). In questo ambiente, i tester delle istruzioni devono provare un gran numero di combinazioni di istruzioni e valutare i risultati. La combinazione di istruzioni, output e valutazione deve essere spostata nel catalogo delle istruzioni di valutazione per automatizzare il processo di testing in futuro. Dopo questo test estensivo, l’ultimo passo è promuovere l’applicazione di IA generativa in produzione tramite CI/CD unendo al branch principale (generative AI App Prod). Si noti che tutti i dati, compreso il catalogo delle istruzioni, i dati e i metadati degli utenti finali, i dati di valutazione e i risultati, i dati e i metadati del modello sintonizzato, devono essere archiviati nel data lake o nel layer del data mesh. I pipeline e i repository CI/CD devono essere archiviati in un account di strumentazione separato (simile a quello descritto per MLOps).
Il percorso dei fornitori
I fornitori di FM devono addestrare FM, come modelli di deep learning. Per loro, è necessario il ciclo di vita e l’infrastruttura MLOps end-to-end. Sono necessari aggiornamenti nella preparazione dei dati storici, nella valutazione del modello e nel monitoraggio. La figura seguente illustra il loro percorso.
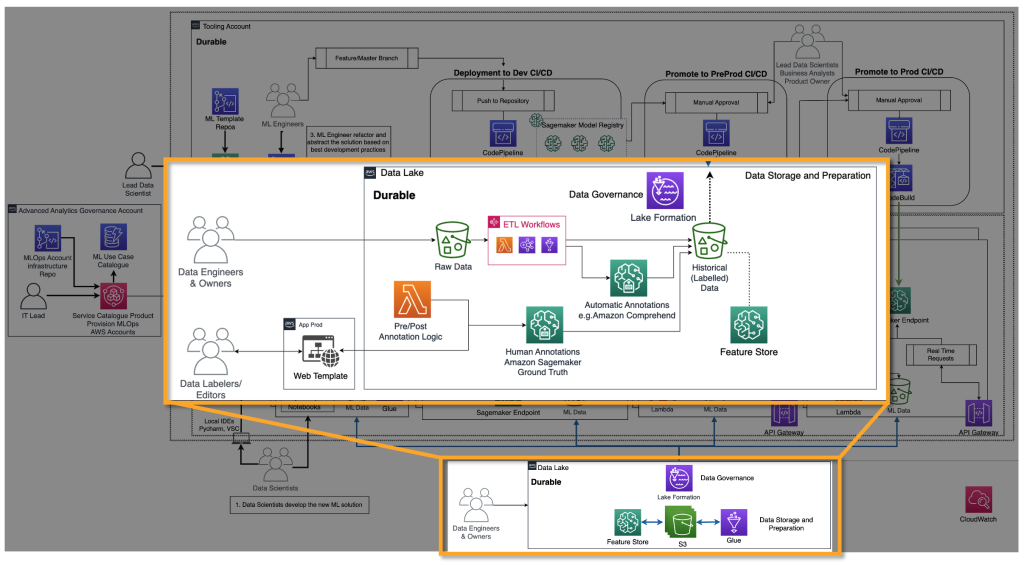
Nell’ML classico, i dati storici sono spesso creati alimentando i dati di verità fondamentale tramite pipeline ETL. Ad esempio, in un caso d’uso di previsione dell’abbandono, un’automazione aggiorna una tabella del database in base al nuovo stato di un cliente per abbandonare/non abbandonare automaticamente. Nel caso dei FM, è necessario un numero elevato di punti dati etichettati o non etichettati. Nei casi di utilizzo del testo per l’immagine, un team di etichettatori dei dati deve etichettare manualmente le coppie <testo, immagine>. Questo è un esercizio costoso che richiede un gran numero di risorse umane. Amazon SageMaker Ground Truth Plus può fornire un team di etichettatori per svolgere questa attività al posto tuo. Per alcuni casi d’uso, questo processo può essere anche parzialmente automatizzato, ad esempio utilizzando modelli simili a CLIP. Nel caso di un LLM, come il testo-testo, i dati non sono etichettati. Tuttavia, devono essere preparati e seguire il formato dei dati storici non etichettati esistenti. Pertanto, sono necessari editori di dati per eseguire la necessaria preparazione dei dati e garantire la coerenza.
Con i dati storici preparati, il passo successivo è l’addestramento e la produzione del modello. Si noti che possono essere utilizzate le stesse tecniche di valutazione descritte per i consumatori.
Il percorso dei raffinatori
I raffinatori mirano ad adattare un FM esistente al loro contesto specifico. Ad esempio, un modello FM può riassumere un testo di uso generico, ma non un rapporto finanziario in modo accurato o non può generare codice sorgente per un linguaggio di programmazione non comune. In questi casi, i raffinatori devono etichettare i dati, raffinare un modello eseguendo un lavoro di addestramento, distribuire il modello, testarlo in base ai processi dei consumatori e monitorare il modello. Il diagramma seguente illustra questo processo.
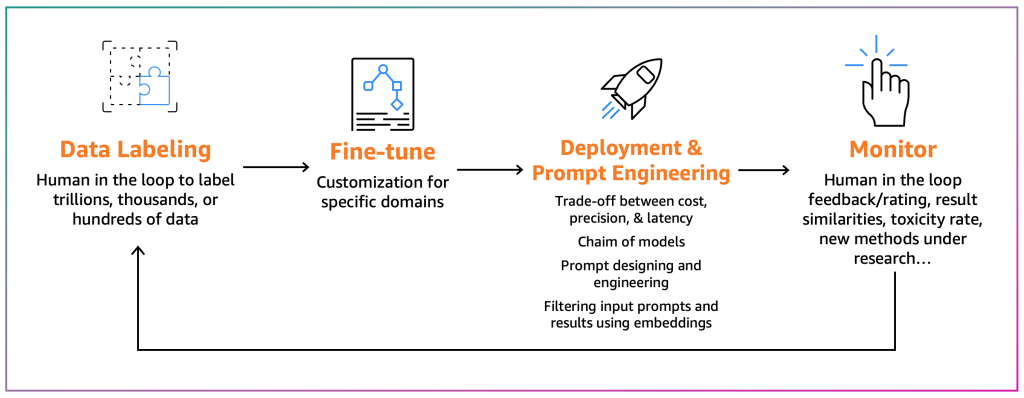
Per il momento, ci sono due meccanismi di raffinamento:
- Raffinamento – Utilizzando un FM e dati etichettati, un lavoro di addestramento ricalcola i pesi e i bias dei livelli del modello di deep learning. Questo processo può essere intensivo dal punto di vista computazionale e richiede una quantità rappresentativa di dati, ma può generare risultati accurati.
- Raffinamento con parametri efficienti (PEFT) – Invece di ricalcolare tutti i pesi e i bias, i ricercatori hanno dimostrato che aggiungendo piccoli livelli aggiuntivi ai modelli di deep learning, è possibile ottenere risultati soddisfacenti (ad esempio, LoRA). PEFT richiede una potenza computazionale inferiore rispetto al raffinamento profondo e un lavoro di addestramento con meno dati di input. Lo svantaggio è una possibile riduzione dell’accuratezza.
Il diagramma seguente illustra questi meccanismi.
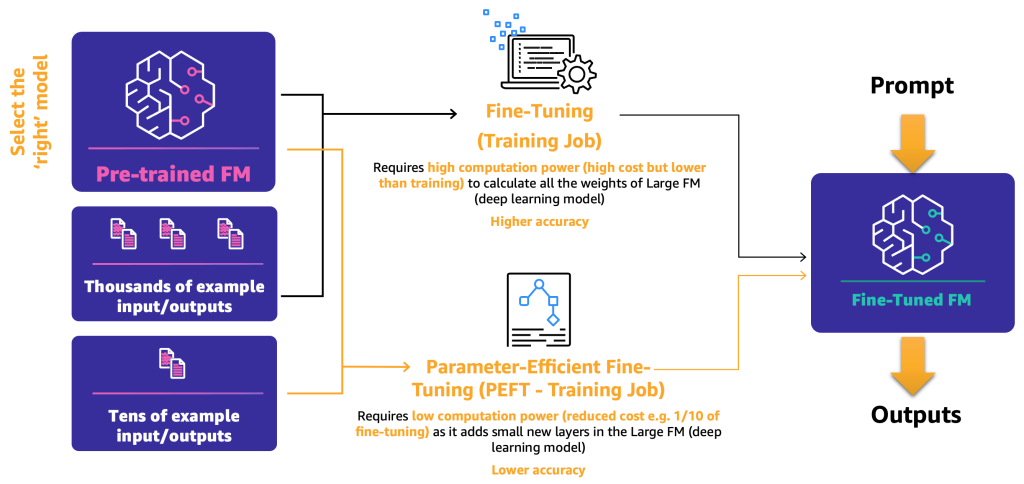
Ora che abbiamo definito i due principali metodi di raffinamento, il passo successivo è determinare come possiamo distribuire e utilizzare FM open-source e proprietari.
Con i FM open-source, i raffinatori possono scaricare l’artefatto del modello e il codice sorgente dal web, ad esempio utilizzando l’Hugging Face Model Hub. Ciò offre la flessibilità di raffinare profondamente il modello, archiviarlo in un registro di modelli locale e distribuirlo a un endpoint di Amazon SageMaker. Questo processo richiede una connessione internet. Per supportare ambienti più sicuri (ad esempio, per i clienti del settore finanziario), è possibile scaricare il modello in locale, eseguire tutti i necessari controlli di sicurezza e caricarli in un bucket locale su un account AWS. Successivamente, i raffinatori utilizzano il FM dal bucket locale senza una connessione internet. Ciò garantisce la privacy dei dati e impedisce che i dati viaggino su Internet. Il diagramma seguente illustra questo metodo.
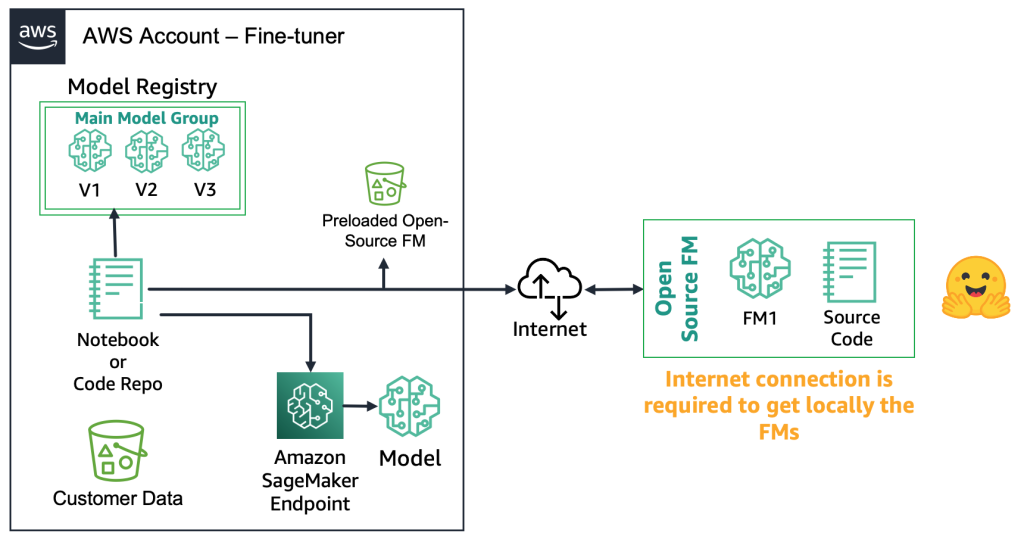
Con i FMs proprietari, il processo di distribuzione è diverso perché i tuner non hanno accesso all’artefatto del modello o al codice sorgente. I modelli sono archiviati negli account AWS dei provider FM proprietari e nei registri dei modelli. Per distribuire un tale modello in un endpoint SageMaker, i tuner possono richiedere solo il pacchetto del modello che verrà distribuito direttamente in un endpoint. Questo processo richiede che i dati del cliente vengano utilizzati negli account dei provider FM proprietari, il che solleva domande riguardo all’utilizzo di dati sensibili del cliente in un account remoto per eseguire il fine-tuning e ai modelli ospitati in un registro dei modelli condiviso tra più clienti. Ciò porta a un problema di multi-tenancy che diventa più complesso se i provider FM proprietari devono servire questi modelli. Se i tuner utilizzano Amazon Bedrock, queste sfide vengono risolte, i dati non viaggiano su Internet e i provider FM non hanno accesso ai dati dei tuner. Le stesse sfide si applicano ai modelli open source se i tuner desiderano servire modelli da più clienti, come nell’esempio che abbiamo dato in precedenza con il sito web su cui migliaia di clienti caricano immagini personalizzate. Tuttavia, questi scenari possono essere considerati controllabili perché coinvolgono solo il tuner. Il diagramma seguente illustra questo metodo.
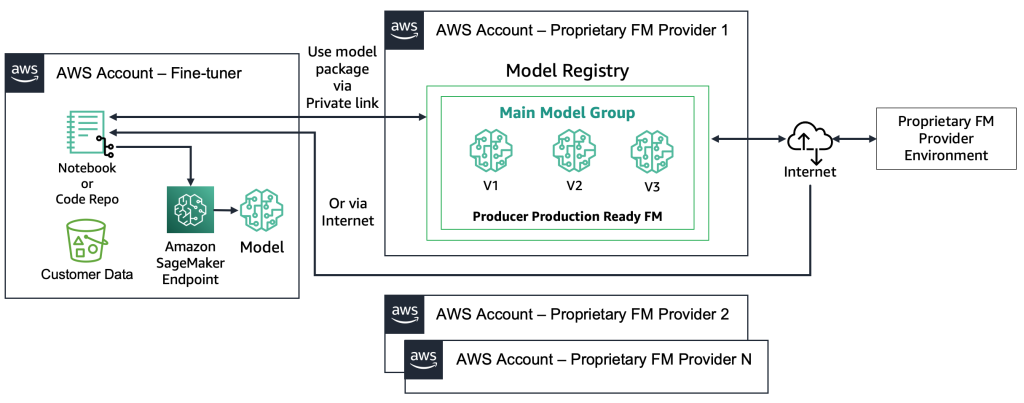
Dal punto di vista tecnologico, l’architettura che un tuner deve supportare è simile a quella per MLOps (vedi la figura seguente). Il fine-tuning deve essere condotto in fase di sviluppo creando pipeline di machine learning, ad esempio utilizzando Amazon SageMaker Pipelines; eseguendo la preelaborazione, il fine-tuning (lavoro di addestramento) e la postelaborazione; e inviando i modelli fine-tunati a un registro dei modelli locale nel caso di un FM open source (altrimenti, il nuovo modello verrà memorizzato nell’ambiente del provider FM proprietario). Quindi, in pre-produzione, è necessario testare il modello come descritto per lo scenario dei consumatori. Infine, il modello verrà servito e monitorato in produzione. Si noti che l’attuale FM (fine-tunato) richiede endpoint di istanze GPU. Se è necessario distribuire ogni modello fine-tunato su un endpoint separato, questo potrebbe aumentare i costi nel caso di centinaia di modelli. Pertanto, è necessario utilizzare endpoint multi-modello e risolvere la sfida della multi-tenancy.
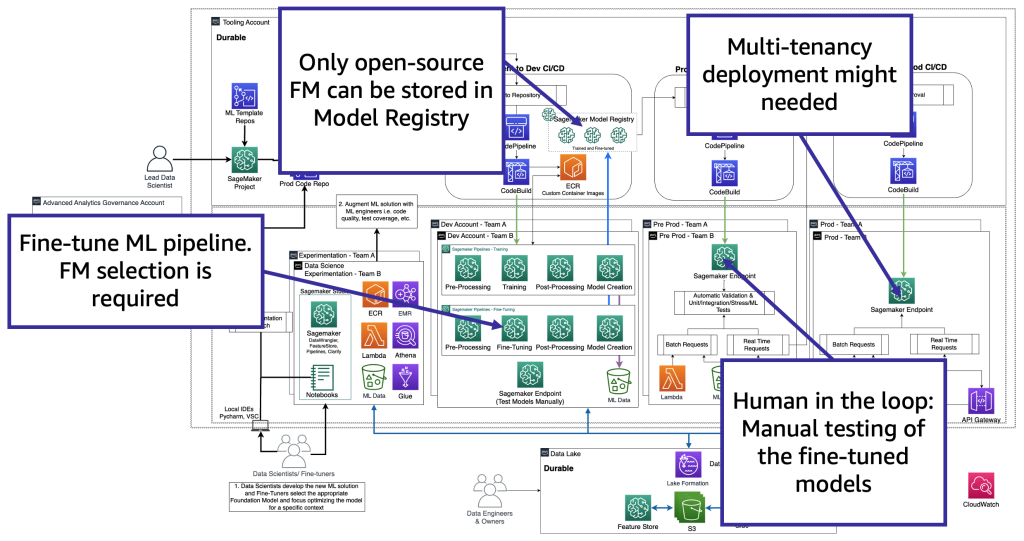
I tuner adattano un modello FM in base a un contesto specifico per usarlo per il loro scopo aziendale. Ciò significa che nella maggior parte dei casi, i tuner sono anche consumatori che devono supportare tutti i livelli, come descritto nelle sezioni precedenti, inclusi lo sviluppo di applicazioni di intelligenza artificiale generativa, i data lake e i data mesh, e MLOps.
La figura seguente illustra il ciclo di vita completo del fine-tuning di FM che i tuner devono fornire all’utente finale di intelligenza artificiale generativa.
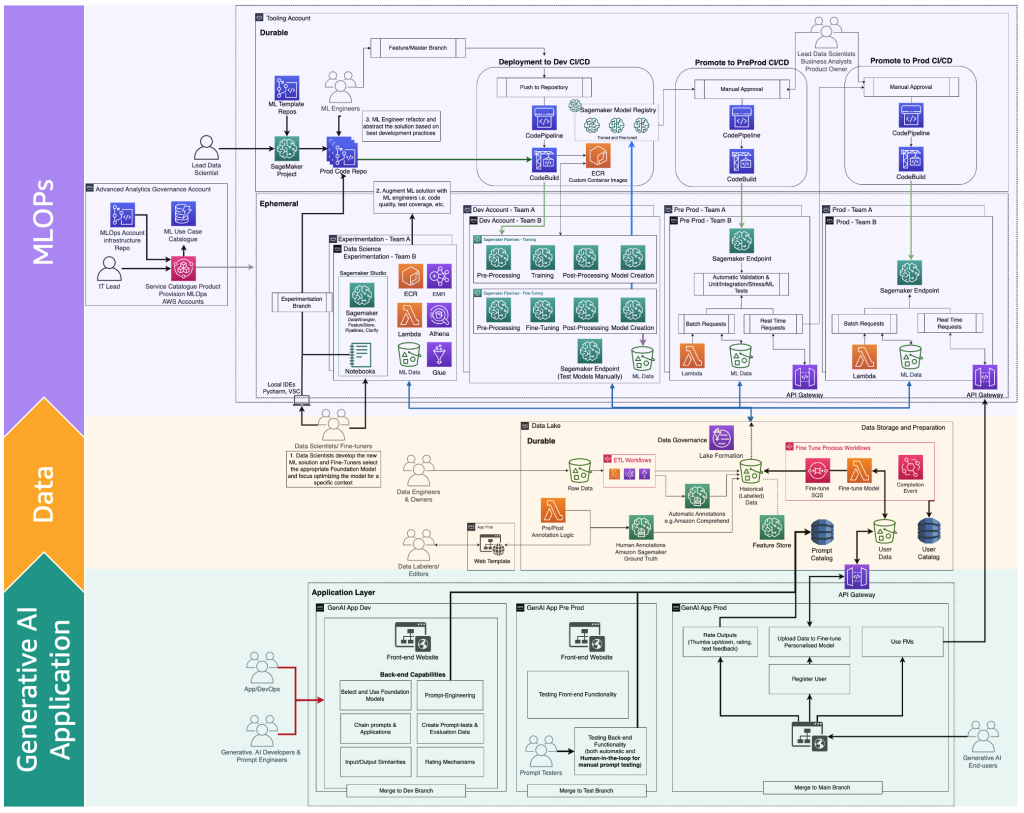
La figura seguente illustra i passaggi chiave.
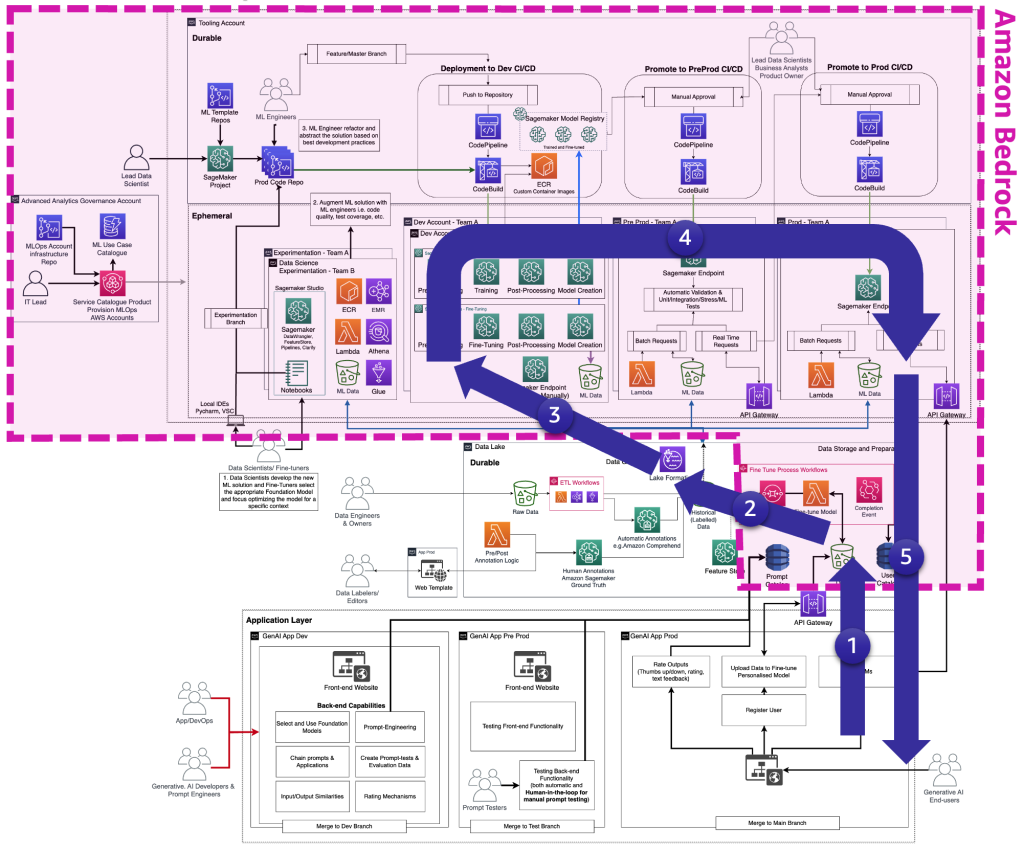
I passaggi chiave sono i seguenti:
- L’utente finale crea un account personale e carica dati privati.
- I dati vengono archiviati nel data lake e vengono preelaborati per seguire il formato previsto dal FM.
- Questo attiva una pipeline di machine learning per il fine-tuning che aggiunge il modello al registro dei modelli.
- Da lì, il modello viene o distribuito in produzione con un minimo di test o viene sottoposto a test estensivi con HIL e approvazione manuale.
- Il modello fine-tunato viene reso disponibile per gli utenti finali.
Poiché questa infrastruttura è complessa per i clienti non aziendali, AWS ha rilasciato Amazon Bedrock per alleggerire lo sforzo di creare tali architetture e avvicinare i FM fine-tunati alla produzione.
Differenziazione delle persone e dei processi di FMOps e LLMOps
In base ai percorsi precedenti dei tipi di utenti (consumatore, produttore e perfezionatore), sono richieste nuove persone con competenze specifiche, come illustrato nella figura seguente.
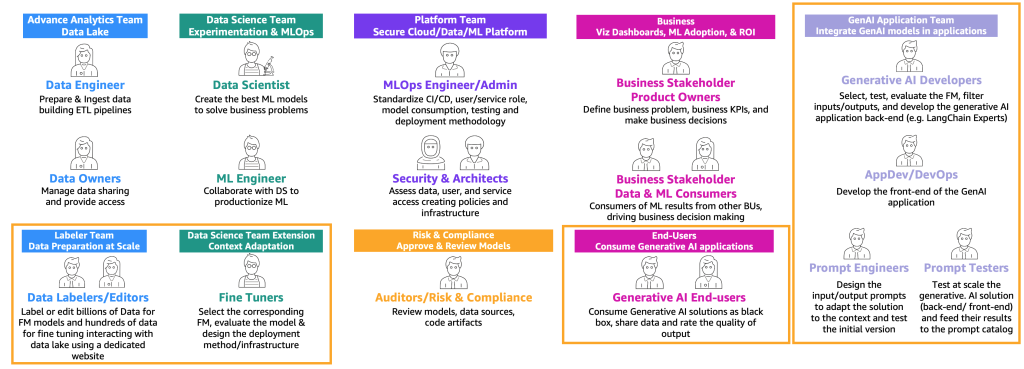
Le nuove persone sono le seguenti:
- Etichettatori e editori di dati – Questi utenti etichettano i dati, come coppie di <testo, immagine>, o preparano dati non etichettati, come testo libero, e estendono i team di analisi avanzata e gli ambienti del data lake.
- Perfezionatori – Questi utenti hanno una conoscenza approfondita delle FM e sanno come ottimizzarle, estendendo il team di data science che si concentrerà sul machine learning classico.
- Sviluppatori di generative AI – Hanno una profonda conoscenza nella selezione delle FM, nella concatenazione di prompt e applicazioni e nel filtraggio degli input e degli output. Fanno parte di un nuovo team: il team delle applicazioni di generative AI.
- Ingegneri di prompt – Questi utenti progettano i prompt di input e output per adattare la soluzione al contesto e testano e creano la versione iniziale del catalogo di prompt. Il loro team è il team delle applicazioni di generative AI.
- Tester di prompt – Testano su larga scala la soluzione di generative AI (backend e frontend) e alimentano i risultati per arricchire il catalogo di prompt e il dataset di valutazione. Il loro team è il team delle applicazioni di generative AI.
- AppDev e DevOps – Sviluppano il frontend (come un sito web) dell’applicazione di generative AI. Il loro team è il team delle applicazioni di generative AI.
- Utenti finali di generative AI – Questi utenti utilizzano le applicazioni di generative AI come scatole nere, condividono dati e valutano la qualità dell’output.
La versione estesa della mappa dei processi di MLOps per incorporare la generative AI può essere illustrata nella seguente figura.
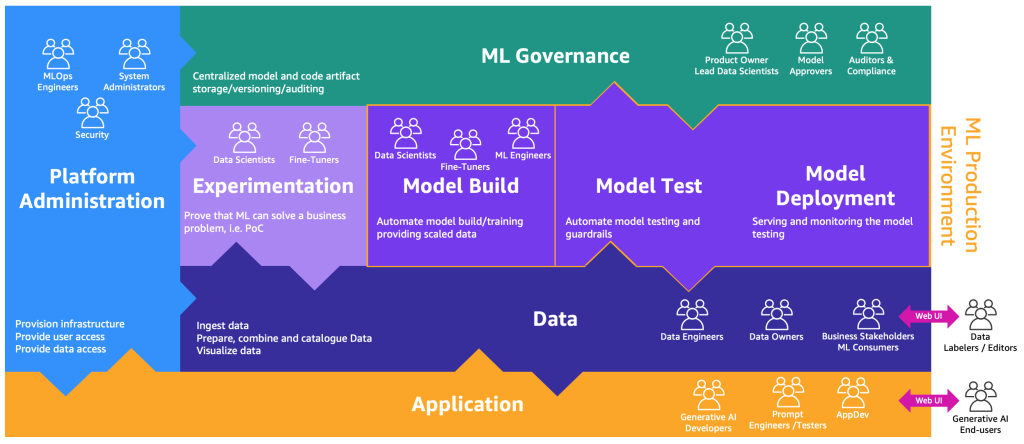
Un nuovo strato di applicazione è l’ambiente in cui sviluppatori di generative AI, ingegneri di prompt e tester e AppDevs creano il backend e il frontend delle applicazioni di generative AI. Gli utenti finali di generative AI interagiscono con il frontend delle applicazioni di generative AI tramite internet (come un’interfaccia utente web). Dall’altra parte, gli etichettatori e gli editori di dati devono pre-elaborare i dati senza accedere al backend del data lake o del data mesh. Pertanto, è necessaria un’interfaccia utente web (sito web) con un editor per interagire in modo sicuro con i dati. SageMaker Ground Truth fornisce questa funzionalità out of the box.
Conclusione
MLOps può aiutarci a rendere efficienti i modelli di machine learning. Tuttavia, per operazionalizzare le applicazioni di generative AI, sono necessarie competenze, processi e tecnologie aggiuntive, che portano a FMOps e LLMOps. In questo post, abbiamo definito i concetti principali di FMOps e LLMOps e descritto le principali differenze rispetto alle capacità di MLOps in termini di persone, processi, tecnologia, selezione ed valutazione dei modelli FM. Inoltre, abbiamo illustrato il processo di pensiero di uno sviluppatore di generative AI e il ciclo di sviluppo di un’applicazione di generative AI.
In futuro, ci concentreremo nel fornire soluzioni per il dominio di cui abbiamo discusso e forniremo maggiori dettagli su come integrare il monitoraggio delle FM (come la tossicità, il bias e le allucinazioni) e modelli architetturali di terze parti o di fonti di dati private, come Retrieval Augmented Generation (RAG), in FMOps/LLMOps.
Per saperne di più, consulta la roadmap di base di MLOps per le imprese con Amazon SageMaker e prova la soluzione end-to-end nell’implementazione delle pratiche di MLOps con i modelli pre-addestrati di Amazon SageMaker JumpStart.
Se hai commenti o domande, lasciali nella sezione dei commenti.




