Conoscere le diverse misure di performance per il problema di classificazione del Machine Learning
Misure di performance per classificazione in Machine Learning
Questo articolo ti insegnerà le diverse misure di prestazione utilizzate nei compiti di classificazione di machine learning. L’articolo tratterà anche l’uso corretto di queste misure di prestazione.
Iniziamo con la domanda: cosa si intende per misura di prestazione?
Nel contesto del machine learning, possiamo considerare le misure di prestazione come uno strumento di misurazione che ci dirà quanto è buono il nostro modello addestrato.
Di solito, “precisione” è considerata una misura standard di prestazione. Ma questo approccio ha uno svantaggio nel caso di un problema di classificazione. Cerchiamo di capirlo con un esempio.
Supponiamo di avere un set di dati di validazione con 100 righe. La colonna target ha solo due valori unici, ovvero “A” e “B” (tipico problema di classificazione binaria). Supponiamo che ci siano 80 A e 20 B nella colonna target del nostro set di dati di validazione. Ora utilizziamo un modello di base che restituisce sempre “A”, indipendentemente dalle caratteristiche di input, per prevedere l’output per il nostro set di dati di validazione. Poiché questo modello è estremamente semplice, è molto probabile che non sia in grado di generalizzare bene sui nuovi dati. Ma comunque otteniamo un’accuratezza dell’80% sui dati di validazione. Questo è molto fuorviante.
- Esplora intuitivamente le metriche R2 e R2 corretto
- Migliori strumenti di correzione grammaticale AI 2023
- Prevedere i Cambiamenti Precancerosi nelle Donne ad Alto Rischio un Approccio Rivoluzionario basato su Deep Learning per la Mammografia
Questo tipo di set di dati, in cui alcune classi sono molto più frequenti di altre, viene chiamato set di dati sbilanciato. La misura di accuratezza fornisce risultati fuorvianti per i set di dati sbilanciati. Ecco perché abbiamo bisogno di altri mezzi per misurare le prestazioni del nostro modello.
Non è consigliato utilizzare la misura di accuratezza per i set di dati sbilanciati.
Nota: È possibile utilizzare la misura di accuratezza per i set di dati bilanciati.
Impariamo alcune altre misure di prestazione.
- matrice di confusione
- precisione
- richiamo
- f1-score
- L’area sotto la curva caratteristica di funzionamento del ricevitore (ROC)
Matrice di confusione
L’idea generale della matrice di confusione è contare quante volte le istanze di “A” vengono classificate come “B” e viceversa.
Per calcolare la matrice di confusione, è prima necessario avere delle previsioni che possono essere confrontate con i valori target effettivi.
Ogni riga nella matrice di confusione rappresenta una classe effettiva, mentre ogni colonna rappresenta una classe prevista.
Prendiamo ad esempio una situazione in cui la colonna target ha categorie uniche chiamate “A” e “B”. Chiamiamo B un non-A qui.
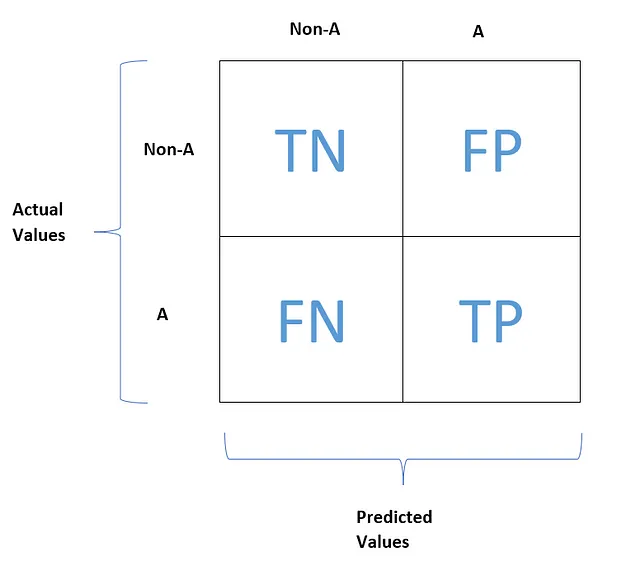
Questa è l’aspetto tipico di una matrice di confusione.
TN, FP, FN e TP stanno rispettivamente per vero negativo, falso positivo, falso negativo e vero positivo. Ora cerchiamo di capire cosa significano questi termini.
Vero negativo (TN) rappresenta il conteggio dei valori di feature negativi (non-A) che sono stati correttamente previsti come negativi.
Falso positivo (FP) rappresenta il conteggio dei valori di feature negativi (non-A) che sono stati erroneamente previsti come positivi.
Falso negativo (FN) rappresenta il conteggio dei valori di feature positivi (A) che sono stati erroneamente previsti come negativi.
Vero positivo (TP) rappresenta il conteggio dei valori di feature positivi (A) che sono stati correttamente previsti come negativi.
Possiamo considerare un classificatore perfetto quando:
- FP = FN = 0
- TP ≥ 0 e TN ≥ 0
In altre parole, la matrice di confusione di un classificatore perfetto avrebbe valori diversi da zero solo sulla sua diagonale principale.
La matrice di confusione ti fornirà molte informazioni sulle prestazioni del modello. Inoltre, essendo una matrice, è un po’ difficile da comprendere con un solo sguardo. Quindi, vorremmo una misura più concisa per valutare le prestazioni del nostro modello.
Precisione, Richiamo e F1-Score
Precisione e richiamo ci forniscono metriche concise per la misurazione delle prestazioni di un modello.
La precisione può essere considerata come l’accuratezza delle previsioni positive. È possibile trovare facilmente la precisione osservando la matrice di confusione.

Inoltre, il richiamo può essere trovato prendendo il rapporto tra il numero di osservazioni positive correttamente previste e il numero totale di osservazioni positive.

Il richiamo ha anche altri nomi come sensibilità o tasso di veri positivi.
Spesso è conveniente combinare precisione e richiamo in una singola metrica chiamata f1-score, specialmente se si desidera un modo semplice per confrontare due classificatori.
La media armonica di precisione e richiamo è chiamata f1-score.

In generale, la media armonica darà più peso a un valore più basso. Ecco perché il classificatore otterrà un alto f1-score se sia la precisione che il richiamo sono alti.
Ma questo non sarà sempre il caso. In alcuni casi, potrebbe essere necessaria una maggiore precisione e un minor richiamo e in altri casi potrebbe essere necessaria una minore precisione e un maggiore richiamo. Dipende dal compito in questione. Prendiamo due esempi per rendere più chiaro.
Esempio 1:
Se si addestra un classificatore per rilevare video sicuri per i bambini. Quindi, per questo classificatore, va bene se alcuni dei video sicuri vengono previsti come non sicuri. Ma il numero di volte in cui il video non sicuro viene previsto come sicuro dovrebbe essere il più basso possibile. Questo implica che dovremmo avere condizioni rigide per questo classificatore come alto FN e basso FP.
Un alto FN implica un valore di richiamo basso e un basso FP implica un valore di precisione alto.

Esempio 2:
Supponiamo di addestrare un classificatore per rilevare un ladro in una telecamera di sorveglianza. Quindi, in questo caso, va bene se una persona innocente viene prevista come un ladro (Moralmente, questa non è la via corretta, ma consideriamo solo il contesto dell’apprendimento automatico). Ma il numero di volte in cui un ladro viene previsto come una persona innocente dovrebbe essere il più basso possibile. Questo implica che dovremmo avere condizioni rigide per questo classificatore come basso FN e alto FP.
Un basso FN implica un valore di richiamo alto e un alto FP implica una precisione bassa.
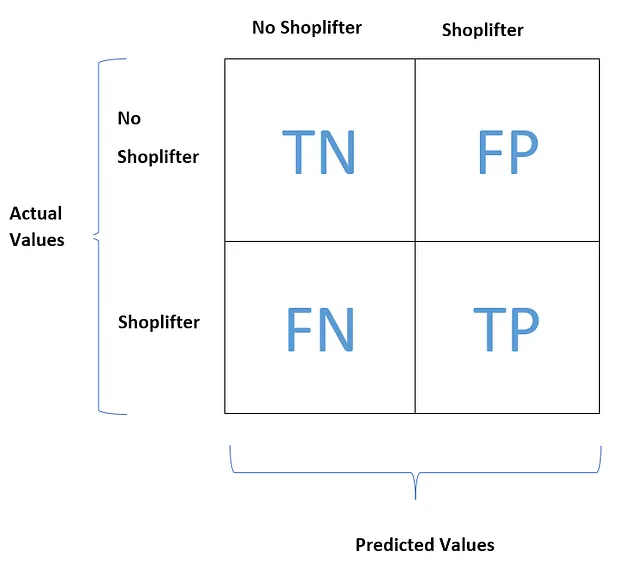
Torniamo al caso di un alto richiamo e una precisione alta. Purtroppo, questo non è possibile in scenari reali. Otteniamo o un alto richiamo e una bassa precisione o un basso richiamo e una precisione alta.
In questo caso, cercheremo di osservare la curva precisione-richiamo e selezionare il punto sul grafico in cui la precisione e il richiamo sono entrambi abbastanza alti secondo il compito.
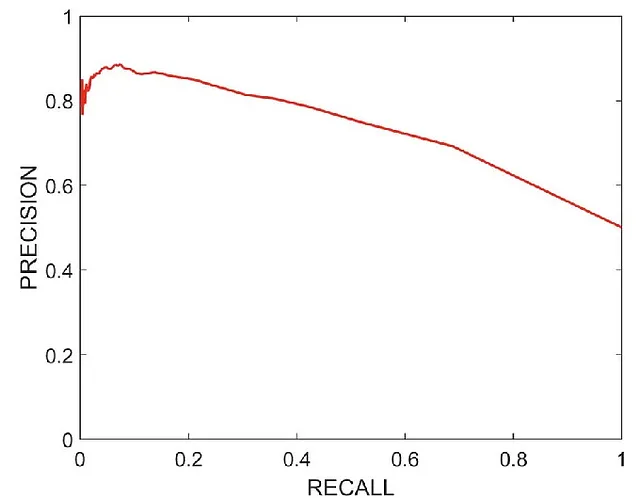
Questa è come appare tipicamente una curva precisione-richiamo. Osservando il grafico possiamo ottenere il punto in cui richiamo = 0.65 e precisione = 0.75. In questo caso, abbiamo ottenuto un valore abbastanza alto sia per la precisione che per il richiamo.
Curva della caratteristica di funzionamento del ricevitore (ROC)
La curva ROC viene utilizzata come metrica per il problema di classificazione binaria. La curva ROC mostra il tasso di veri positivi (cioè richiamo) rispetto al tasso di falsi positivi.
Ecco come apparirà tipicamente una curva ROC.
Il tasso di veri positivi (TPR) e il tasso di falsi positivi (FPR) possono essere ottenuti utilizzando le seguenti formule.
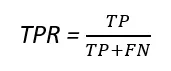
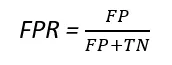
La linea tratteggiata rappresenta la curva ROC di un modello di classificazione puramente casuale; un buon classificatore rimane sempre il più lontano possibile da quella linea (verso l’angolo in alto a sinistra).
Un modo per determinare quanto la curva ROC del nostro modello si discosta dalla curva ROC del modello casuale è calcolare l’area sotto la curva. Se l’area sotto la curva ROC del nostro modello è pari a 1, allora il modello si discosta quanto più possibile dalla curva ROC del modello casuale. Pertanto, in questo caso, il nostro modello potrebbe essere considerato un modello perfetto. Un modello con un’area maggiore sotto la curva ROC sarà un modello migliore.
L’area sotto la curva ROC può essere utilizzata per confrontare due classificatori. Un classificatore con un’area maggiore sotto la sua curva ROC sarà un modello migliore in termini di prestazioni.
Quando utilizzare una curva di precisione-richiamo e quando utilizzare una curva ROC?
Come regola generale, si dovrebbe preferire una curva di precisione-richiamo quando la classe positiva è rara o quando si dà maggiore importanza ai falsi positivi rispetto ai falsi negativi. Altrimenti, utilizzare la curva ROC.
Ad esempio, se stiamo studiando un’infezione di una malattia rara, avremo una classe positiva rara. In questo caso, la curva di precisione-richiamo sarebbe la scelta migliore come misura delle prestazioni.
Ulteriori letture:
Documentazione di scikit-learn
Libro intitolato “Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow”
(1527) The NO CONFUSION matrix! // What is the confusion matrix? // Confusion matrix visual explanation — YouTube
(1527) Never Forget Again! // Precision vs Recall with a Clear Example of Precision and Recall — YouTube
Outro
Spero che ti sia piaciuto questo articolo. Seguimi su VoAGI per leggere altri articoli simili.
Connettiti con me su
Sito web
Scrivimi a [email protected]






