Esplorazione di Data Mesh Un cambiamento di paradigma nell’architettura dei dati
Esplorazione del Data Mesh Un cambiamento di paradigma nell'architettura dei dati

In risposta ai cambiamenti tecnologici, organizzativi e aziendali, l’architettura dei dati si è evoluta negli ultimi dieci anni circa. Ma questa evoluzione è stata abbastanza significativa? La maggior parte delle organizzazioni ha tipicamente un’architettura dei dati centralizzata. Che, per design, consolida i dati sotto un unico ombrello, spesso gestito da un team dati dedicato.
Pur essendo efficace nel garantire sicurezza e migliore governance, l’architettura dei dati centralizzata ha limitazioni in termini di scalabilità, flessibilità e accessibilità, tra gli altri.
Ecco Data Mesh, un concetto (quasi) analogo ai microservizi nell’architettura del software. Data Mesh mira a decentralizzare la gestione dei dati proprio come i microservizi si concentrano sulla decentralizzazione dei componenti dell’applicazione. Distribuisce la proprietà e la responsabilità dei dati tra i team specifici del dominio, riconoscendo i dati come una risorsa strategica, meglio gestita alla sua fonte.
- Hasdx e Diffusione Stabile Confrontando due modelli di generazione di immagini AI
- La Cina mira alla sicurezza dei dati di intelligenza artificiale generativa con nuove proposte regolamentari
- Implementazione della tariffazione delle camere d’albergo basata sulla domanda nella scienza dei dati utilizzando MLOps
In questo articolo, esploreremo Data Mesh, i suoi principi chiave, i fattori da considerare e le sfide associate all’adozione di un’architettura di data mesh.
Cos’è una Data Mesh?
Il concetto di Data Mesh è stato introdotto per la prima volta da Zhamak Dehghani, nell’articolo “Come andare oltre un Monolithic Data Lake verso una Distributed Data Mesh“, che ne illustra i principi e i concetti alla base della data mesh. Questo articolo e le successive discussioni all’interno delle comunità dei dati hanno svolto un ruolo significativo nella popolarizzazione dell’architettura della data mesh.
Una Data Mesh è un’approccio contemporaneo all’architettura e alla gestione dei dati che si discosta dai tradizionali modelli di dati centralizzati. Introduce una struttura decentralizzata per organizzare, distribuire e utilizzare gli asset dati di un’organizzazione.
In una data mesh, la proprietà e le responsabilità dei dati sono distribuite tra i team specifici del dominio o i team di prodotti dati, concedendo loro autonomia nella gestione dei loro dati all’interno dei rispettivi domini.
Questo approccio decentralizzato mira a risolvere le limitazioni associate ai modelli di dati centralizzati, come sfide di scalabilità, silos di dati e tempi di risposta lenti alle mutevoli esigenze dei dati. Definisce un’architettura che incoraggia l’autonomia dei team specifici del dominio, l’agilità e la responsabilità dei dati all’interno di un’organizzazione. Inoltre, consente la gestione efficiente di diverse fonti di dati, garantendo allo stesso tempo la qualità e la rilevanza dei dati.
Principi chiave nell’architettura di Data Mesh
L’architettura di Data Mesh si basa su un insieme di principi progettati per affrontare le sfide dello scaling e della gestione dei dati all’interno e tra le organizzazioni. Questi principi forniscono una base per un approccio decentralizzato e più scalabile alla gestione dei dati.
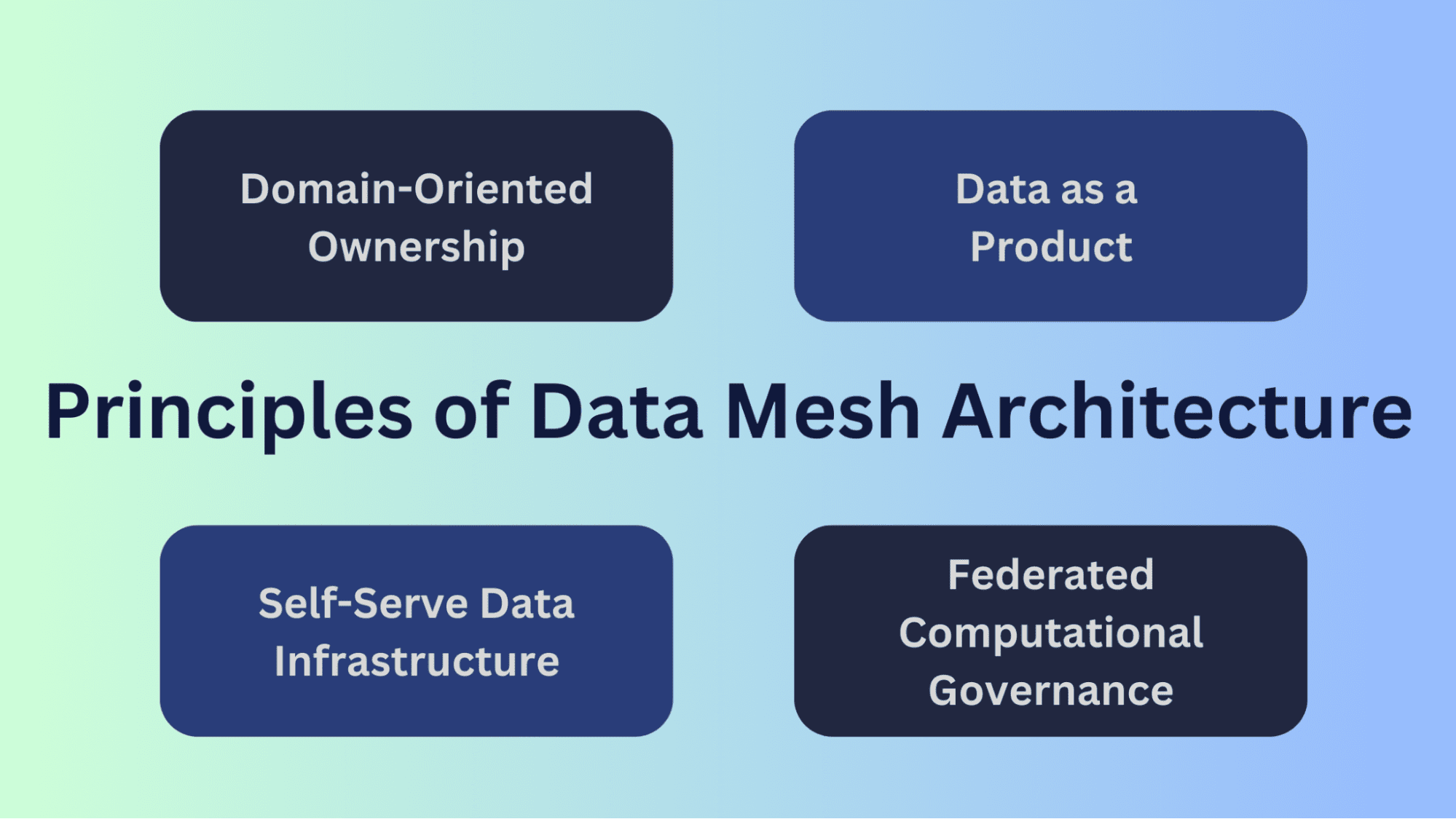
Proprietà orientata al dominio
In una data mesh, la proprietà dei dati è decentralizzata e distribuita tra vari domini o unità aziendali all’interno dell’organizzazione. Ogni dominio è responsabile dei dati generati e utilizzati all’interno della sua area specifica di competenza o funzionalità. Questo principio riconosce che gli esperti del dominio sono i più adatti a comprendere e gestire i dati all’interno dei rispettivi domini.
La proprietà orientata al dominio migliora la qualità e l’accuratezza dei dati perché coloro che sono più vicini alla fonte dei dati hanno una profonda comprensione del loro contesto e possono garantirne l’integrità. Promuove anche un senso di proprietà e responsabilità dei dati, incoraggiando i team del dominio a mantenere elevati standard di dati.
Dati come prodotto
I dati in una data mesh sono trattati come un prodotto anziché come un sottoprodotto delle operazioni aziendali. Ogni dominio è responsabile della fornitura di prodotti dati ben definiti che sono progettati, confezionati e resi disponibili per il consumo da parte di altri domini all’interno dell’organizzazione. Questi prodotti dati hanno definizioni chiare, meccanismi di accesso e accordi di livello di servizio (SLA).
Trattando i dati come un prodotto, si incentiva i produttori di dati a concentrarsi sul fornire dati di alta qualità e di valore ai consumatori. Assicura inoltre che i prodotti dati siano progettati tenendo conto delle esigenze degli utenti, rendendo i dati più accessibili e utilizzabili per una vasta gamma di stakeholder.
Infrastruttura Dati Self-Serve
Data Mesh favorisce lo sviluppo di un’infrastruttura dati self-serve che permette ai consumatori di dati come analisti, scienziati dei dati e utenti aziendali di accedere e elaborare dati in modo indipendente. Questa infrastruttura include cataloghi di dati, meccanismi di scoperta dei dati e pipeline di elaborazione dati che consentono ai consumatori di trovare, capire e utilizzare i dati senza doversi affidare pesantemente ai team di ingegneria dei dati centralizzati.
L’infrastruttura dati self-serve riduce i collo di bottiglia e accelera l’accesso ai dati permettendo a un’ampia gamma di utenti di lavorare con i dati. Democratizza i dati all’interno dell’organizzazione, rendendoli più accessibili e consentendo decisioni e insight più rapidi.
Governance Computazionale Federata
Per mantenere la qualità, sicurezza e conformità dei dati in un’architettura dati decentralizzata, il data mesh utilizza una governance computazionale federata. Ogni dominio definisce ed attua le proprie politiche di governance personalizzate in base alle esigenze specifiche dei propri dati. Pur esistendo standard e linee guida globali, i singoli domini hanno autonomia nella governance dei propri asset dati.
Ciò bilancia la necessità di standard globali con la flessibilità richiesta dai domini individuali. Permette ai domini di adattare le pratiche di governance alle proprie sfide uniche relative ai dati, garantendo al contempo che i dati rimangano sicuri, conformi e di alta qualità.
Questi quattro principi chiave del data mesh, quindi, mirano collettivamente ad affrontare le sfide dello scale delle operazioni dati nelle grandi organizzazioni promuovendo:
- decentralizzazione,
- pensiero di prodotto dati,
- self-service e
- governance efficace.
Implementando questi principi, le organizzazioni possono sfruttare appieno il potenziale dei propri asset dati, migliorare la collaborazione tra i team di dominio e rendere i dati una risorsa più preziosa ed accessibile per tutti gli stakeholder.
Stai Implementando un Data Mesh? Ecco i Fattori da Considerare
Passare a un data mesh spesso comporta un cambiamento culturale significativo all’interno di un’organizzazione. Un data mesh favorisce la collaborazione, la condivisione della proprietà e il pensiero di prodotto dati, allineando le pratiche dati più strettamente alla cultura e ai valori in evoluzione dell’organizzazione. Ecco alcuni fattori che le organizzazioni potrebbero considerare quando implementano un data mesh.
Obiettivi Aziendali e Strategia
Qualsiasi cambiamento significativo nell’architettura dati dovrebbe essere allineato agli obiettivi aziendali e agli obiettivi strategici dell’organizzazione.
L’implementazione di un data mesh dovrebbe essere vista come un abilitatore strategico, migliorando la capacità dell’organizzazione di sfruttare efficacemente i dati per raggiungere i suoi obiettivi complessivi.
Infrastruttura Esistente
Le organizzazioni devono valutare e considerare la propria infrastruttura dati attuale e gli investimenti quando valutano la fattibilità di un data mesh.
Passare a un data mesh potrebbe richiedere adeguamenti allo stack tecnologico e all’infrastruttura esistente, rendendo essenziale allineare questi aspetti al nuovo approccio.
Complessità dei Dati e Scalabilità
Quando le organizzazioni affrontano una crescente complessità dei dati e di scala, devono considerare approcci alternativi alla gestione dati. Un data mesh offre scalabilità e adattabilità, soprattutto quando si tratta di ambienti dati complessi e di larga scala.
Quindi un data mesh è una buona scelta quando il volume, la varietà o la velocità dei dati rendono difficile una gestione centralizzata, o quando i requisiti dei dati sono diversi tra diverse unità aziendali o domini.
Governance e Conformità dei Dati
Mantenere la qualità, la privacy, la sicurezza e la conformità dei dati è un aspetto complesso della gestione dei dati, soprattutto in ambienti decentralizzati.
Una strategia data mesh deve affrontare queste complessità in modo efficace, garantendo che le pratiche di governance dei dati e i requisiti regolatori vengano rispettati.
Accessibilità e Proprietà dei Dati
Nelle organizzazioni con fonti dati distribuite e diversi domini, la gestione dati centralizzata tradizionale potrebbe non essere sufficiente. L’implementazione di un data mesh allinea l’proprietà dei dati con i team specifici del dominio, permettendo loro di assumersi la responsabilità dei propri dati, il che può essere particolarmente prezioso in tali ambienti.
Inoltre, per facilitare la presa di decisioni basate sui dati nell’intera organizzazione, è fondamentale rendere i dati più accessibili. Un data mesh democratizza l’accesso ai dati, consentendo a un’ampia gamma di utenti di accedere e utilizzare i dati, migliorando la presa di decisioni in vari dipartimenti o team.
Sfide nell’adozione di un’architettura Data Mesh
Passare da un’architettura dei dati centralizzata a un data mesh non è privo di sfide. In questa sezione, approfondiamo alcune di esse: dalla governance al monitoraggio.
Governo dei dati
In un data mesh, la governance dei dati diventa più complessa perché i dati sono distribuiti tra diversi domini e team. Garantire standard consistenti di qualità dei dati, privacy, sicurezza e conformità in questi domini può essere una sfida:
- Stabilire chiaramente la proprietà dei dati e la responsabilità per le attività di governo dei dati, come la definizione degli schemi dei dati e i controlli di accesso, può essere una sfida quando sono coinvolti più team.
- Sviluppare e applicare politiche e pratiche di governo dei dati che si allineino alla natura decentralizzata di un data mesh richiede una pianificazione attenta.
Ricerca dei dati
In un data mesh decentralizzato, trovare e accedere ai dati può essere una sfida. Assicurarsi che i dati siano catalogati, etichettati e documentati correttamente è fondamentale per consentire la ricerca dei dati. Ecco alcune strategie:
- Implementare pratiche efficaci di gestione dei metadati per fornire contesto e descrizioni per i set di dati, facilitando agli utenti la comprensione delle risorse di dati disponibili.
- Sviluppare e gestire un catalogo dei dati o un repository dei metadati che consenta agli utenti di cercare e trovare in modo efficiente i set di dati pertinenti.
Proprietà dei dati
Una definizione chiara e coerente di proprietà e responsabilità dei dati per ciascun dominio dei dati e prodotto dei dati è cruciale in un data mesh. Determinare chi è responsabile della gestione, dell’aggiornamento e della cura dei dati può essere una sfida, specialmente quando ci sono più stakeholder. Le organizzazioni possono affrontare questa sfida:
- Assicurarsi che i proprietari dei dati abbiano l’autorità e le risorse necessarie per gestire efficacemente i loro domini dei dati.
- Istituire meccanismi per risolvere conflitti o dispute legati alla proprietà dei dati e alle responsabilità.
Monitoraggio e osservabilità
In un data mesh, il monitoraggio dello stato di salute, delle prestazioni e dell’affidabilità dei flussi di dati e dei prodotti di dati può essere complesso. Alcune strategie includono:
- Implementare strumenti e pratiche robusti di monitoraggio e osservabilità per tracciare la qualità dei dati, la latenza e l’utilizzo tra diversi domini.
- Sviluppare meccanismi di allarme e reporting per individuare e risolvere rapidamente problemi che possono influire sulla disponibilità o l’affidabilità dei dati.
Abbiamo evidenziato alcune sfide nell’implementazione di un data mesh. Questi sono più dei punti da tenere presente quando si passa a un’architettura dei dati decentralizzata.
Conclusioni
Il Data Mesh rappresenta quindi un cambiamento di paradigma nell’architettura dei dati, offrendo soluzioni alle sfide dei modelli centralizzati. Abbiamo discusso di come la distribuzione della proprietà dei dati, la promozione del pensiero del prodotto dei dati e la possibilità di accesso self-service siano vantaggiosi. Tuttavia, per una corretta implementazione, è necessaria una valutazione attenta dei fattori culturali e tecnologici, nonché un approccio proattivo alla governance dei dati. Bala Priya C è una sviluppatrice e scrittrice tecnica dell’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e bere caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità degli sviluppatori attraverso la stesura di tutorial, guide pratiche, articoli di opinione e altro ancora.
[Bala Priya C](https://twitter.com/balawc27) è una sviluppatrice e scrittrice tecnica dell’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e bere caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità degli sviluppatori attraverso la stesura di tutorial, guide pratiche, articoli di opinione e altro ancora.



