Configurazione di progetti Python Parte V
'Configurazione progetti Python V'
Padronanza dell’arte della configurazione di progetti Python: una guida passo-passo
Sia che tu sia uno sviluppatore esperto o che tu stia iniziando con 🐍 Python, è importante sapere come creare progetti robusti e manutenibili. Questo tutorial ti guiderà attraverso il processo di configurazione di un progetto Python utilizzando alcuni degli strumenti più popolari ed efficaci del settore. Imparerai come utilizzare GitHub e GitHub Actions per il controllo delle versioni e l’integrazione continua, nonché altri strumenti per il testing, la documentazione, l’impacchettamento e la distribuzione. Il tutorial è ispirato a risorse come Hypermodern Python e Best Practices for a new Python project. Tuttavia, questa non è l’unico modo per fare le cose e potresti avere preferenze o opinioni diverse. Il tutorial è destinato ai principianti, ma affronta anche argomenti avanzati. In ogni sezione, automatiserai alcune attività e aggiungerai badge al tuo progetto per mostrare i tuoi progressi e risultati.
Il repository per questa serie si trova su github.com/johschmidt42/python-project-johannes
Questa parte è stata ispirata da questo post del blog:
Rilascio semantico con Python, Poetry & GitHub Actions 🚀 Sto pianificando di aggiungere alcune funzionalità a Dr. Sven grazie all’interesse dei miei colleghi. Prima di farlo, ho avuto bisogno di…
- Git Tags Cosa sono e come utilizzarli
- Ho usato ChatGPT (tutti i giorni) per 5 mesi. Ecco alcune gemme nascoste che cambieranno la tua vita.
- AI Inganna gli Scammers La Battaglia Ingeniosa contro le Chiamate Automated
Requisiti
- Sistema operativo: Linux, Unix, macOS, Windows (WSL2 con ad esempio Ubuntu 20.04 LTS)
- Strumenti: python3.10, bash, git, tree
- Sistema di controllo delle versioni (VCS) Host: GitHub
- Strumento di integrazione continua (CI): GitHub Actions
Si presume che tu sia familiare con il sistema di controllo delle versioni (VCS) git. Se non lo sei, ecco un promemoria per te: Introduzione a Git
Le commit saranno basate sulle migliori pratiche per le commit git e le commit convenzionali. Esiste il plugin di commit convenzionali per PyCharm o un’estensione di VSCode che ti aiuta a scrivere commit in questo formato.
Panoramica
- Parte I (GitHub, IDE)
- Parte II (Formattazione, Linting, CI)
- Parte III (Testing, CI)
- Parte IV (Documentazione, CI/CD)
- Parte V (Versioning & Releases, CI/CD)
- Parte VI (Containerizzazione, Docker, CI/CD)
Struttura
- Strategia di branching di Git (GitHub flow)
- Cos’è un rilascio? (zip, tar.gz)
- Versioning semantico (v0.1.0)
- Crea un rilascio manualmente (git tag, GitHub)
- Crea un rilascio automaticamente (commit convenzionali, rilasci semantici)
- CI/CD (release.yml)
- Crea un token di accesso personale (PAT)
- Flusso delle azioni di GitHub (orchestrare i flussi di lavoro)
- Badge (Rilascio)
- Bonus (Imporre commit convenzionali)
Rilasciare il software è un passo importante nel processo di sviluppo software in quanto rende le nuove funzionalità e le correzioni dei bug disponibili agli utenti. Un aspetto chiave del rilascio del software è la versione, che aiuta a tracciare e comunicare le modifiche apportate in ogni rilascio. La versione semantica è uno standard ampiamente utilizzato per la versione del software, che utilizza un numero di versione nel formato di Maggiore.Minore.Patch (ad esempio 1.2.3) per indicare il livello di modifiche apportate in un rilascio.
Le commit convenzionali sono una specifica per aggiungere un significato leggibile dall’uomo e dalla macchina ai messaggi di commit. È un modo per formattare i messaggi di commit in modo coerente, che facilita la determinazione del tipo di modifica apportata. Le commit convenzionali sono comunemente utilizzate in combinazione con la versione semantica, poiché i messaggi di commit possono essere utilizzati per determinare automaticamente il numero di versione di un rilascio. Insieme, la versione semantica e le commit convenzionali forniscono un modo chiaro e coerente per tracciare e comunicare le modifiche apportate in ogni rilascio di un progetto software.
Strategia di branching di Git
Ci sono molte strategie di branching diverse per Git. Molte persone si orientano verso GitFlow (o varianti), Three Flow o Trunk based Flows. Alcuni adottano strategie intermedie tra queste, come questa. Io uso la molto semplice strategia di branching di GitHub Flow, in cui tutte le correzioni di bug e le nuove funzionalità hanno il loro proprio branch separato e, una volta completati, ogni branch viene unito a main e distribuito. Semplice, piacevole e facile.
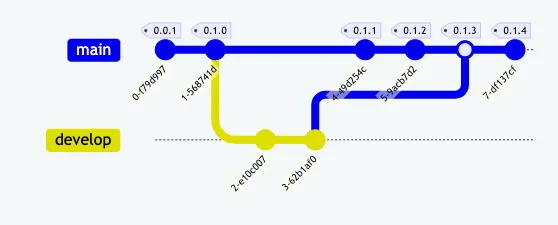
Qualunque sia la tua strategia, alla fine si unisce una pull request e (probabilmente) si crea una release.
Cos’è una release?
In breve, una release è l’impacchettamento del codice di una versione (ad esempio in formato zip) e il suo invio in produzione (qualunque cosa ciò significhi per te).
La gestione delle release può essere complicata. Pertanto, è necessario seguire un modo conciso (anche per gli altri) che definisca cosa significa una release e cosa cambia tra una release e la successiva. Se non si tiene traccia delle modifiche tra le release, è probabile che non si comprenda cosa è stato modificato in ciascuna release e non si possano identificare eventuali problemi che potrebbero essere stati introdotti con il nuovo codice. Senza un registro delle modifiche, può essere difficile capire come il software si è evoluto nel tempo. Può anche rendere difficile annullare le modifiche se necessario.
Versioning semantico
Il versioning semantico è solo uno schema di numerazione e una pratica standard nell’industria dello sviluppo software. Indica il livello di cambiamenti tra questa versione e quella precedente. Ci sono tre parti in un numero di versione semantica, come ad esempio 1.8.42, che seguono il seguente schema:
- MAJOR.MINOR.PATCH
Ognuna di esse rappresenta un diverso grado di cambiamento. Una versione PATCH indica correzioni di bug o modifiche triviali (ad esempio da 1.0.0 a 1.0.1). Una versione MINOR indica l’aggiunta/rimozione di funzionalità o modifiche compatibili all’indietro delle funzionalità (ad esempio da 1.0.0 a 1.1.0). Una versione MAJOR indica l’aggiunta/rimozione di funzionalità e potenzialmente modifiche non compatibili all’indietro come cambiamenti rilevanti (ad esempio da 1.0.0 a 2.0.0).
Ti consiglio una presentazione di Mike Miles, se vuoi un’introduzione visiva alle release con versioning semantico. È un riassunto di ciò che sono le release e come il versioning semantico con i tag di git ci consente di creare release.
Riguardo ai tag di git: ci sono tag leggeri e annotati in git. Un tag leggero è solo un puntatore a un commit specifico, mentre un tag annotato è un oggetto completo in git.
Creare una release manualmente
Creiamo prima manualmente una release e poi automatizziamola.
Se ricordi, il file __init__.py della nostra example_app contiene anche la versione
# src/example_app/__init__.py__version__ = "0.1.0"così come il file pyproject.toml
# pyproject.toml[tool.poetry]name = "example_app"version = "0.1.0"...Quindi, la prima cosa che dobbiamo fare è creare un tag git annotato v0.1.0 e aggiungerlo all’ultimo commit in main:
> git tag -a v0.1.0 -m "versione v0.1.0"Si noti che se non viene specificato un hash del commit alla fine del comando, git utilizzerà il commit corrente su cui ci si trova.
Possiamo ottenere un elenco dei tag con:
> git tagv0.1.0e se vogliamo eliminarlo di nuovo:
> git tag -d v0.1.0Tag 'v0.1.0' eliminatoe ottenere ulteriori informazioni sul tag con:
> git show v0.1.0tag v0.1.0Tagger: Johannes Schmidt <[email protected]>Date: Sat Jan 7 12:55:15 2023 +0100versione v0.1.0commit efc9a445cd42ce2f7ddfbe75ffaed1a5bc8e0f11 (HEAD -> main, tag: v0.1.0, origin/main, origin/HEAD)Autore: Johannes Schmidt <[email protected]>Data: Mon Jan 2 11:20:25 2023 +0100...Possiamo pushare la nuova tag creata all’origine con
> git push origin v0.1.0Enumerating objects: 1, done.Counting objects: 100% (1/1), done.Writing objects: 100% (1/1), 171 bytes | 171.00 KiB/s, done.Total 1 (delta 0), reused 0 (delta 0), pack-reused 0To github.com:johschmidt42/python-project-johannes.git * [new tag] v0.1.0 -> v0.1.0così che questa git tag è ora disponibile su GitHub:
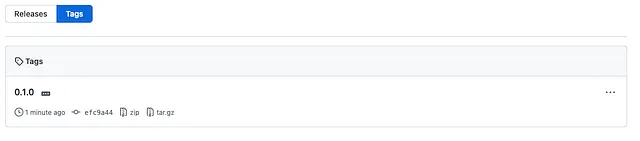
Creiamo manualmente una nuova release su GitHub con questa git tag:
Clicchiamo su Create a new release , selezioniamo la nostra tag esistente (che è già legata a un commit) e generiamo automaticamente le note di rilascio cliccando sul pulsante Generate release notes prima di pubblicare definitivamente il rilascio con il pulsante Publish release.
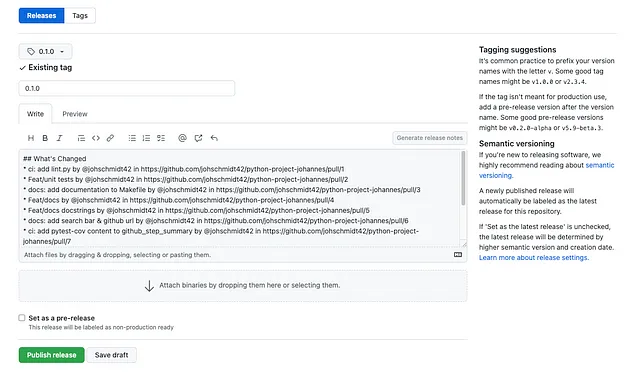
GitHub creerà automaticamente un tar e un zip (assets) per il codice sorgente, ma non compilerà l’applicazione! Il risultato sarà simile a questo:
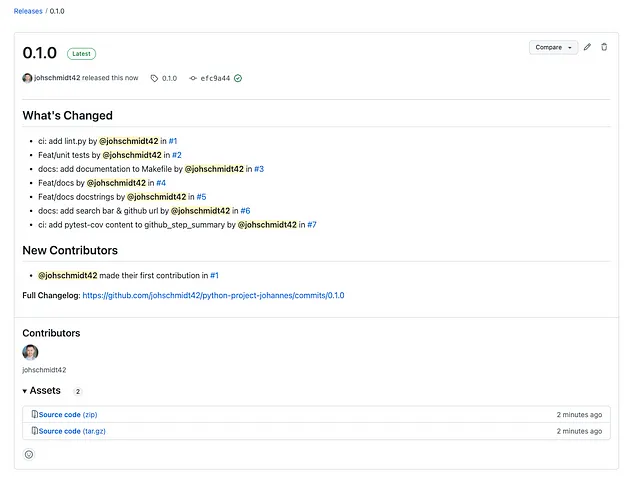
Per riassumere, i passaggi per un rilascio sono:
- creare un nuovo branch dal tuo branch predefinito (ad esempio un branch di funzionalità o di correzione)
- apportare modifiche e aumentare la versione (ad esempio nel file pyproject.toml e __init__.py)
- committare la funzionalità/fix al branch predefinito (probabilmente tramite una Pull Request)
- aggiungere una git tag annotata (versione semantica) al commit
- pubblicare il rilascio su GitHub con alcune informazioni aggiuntive
Creare un rilascio in modo automatico
Come programmatori, non ci piace ripeterci. Quindi ci sono molti strumenti che rendono questi passaggi estremamente facili per noi. Qui, presenterò Semantic Releases, un tool specificamente per i progetti Python.
È uno strumento che imposta automaticamente un numero di versione nel tuo repository, etichetta il codice con il numero di versione e crea un rilascio! E tutto ciò viene fatto utilizzando i contenuti di messaggi di stile Conventional Commit.
Conventional Commits
Qual è la connessione tra la versione semantica e i conventional-commit ?
Certaini tipi di commit possono essere utilizzati per determinare automaticamente un incremento della versione semantica!
- Un commit
fixè un PATCH. - Un commit
featè un MINOR. - Un commit con
BREAKING CHANGEo!è un MAJOR.
Altri tipi, ad esempio build , chore , ci , docs , style , refactor , perf , test generalmente non aumentano la versione.
Scopri la sezione bonus alla fine per scoprire come imporre i conventional commits nel tuo progetto!
Rilasci semantici automatici (localmente)
Possiamo aggiungere la libreria con:
> poetry add --group semver python-semantic-releaseAndiamo attraverso le impostazioni di configurazione che ci permettono di generare automaticamente i log delle modifiche e i rilasci. Nel pyproject.toml , possiamo aggiungere semantic_release come strumento:
# pyproject.toml...[tool.semantic_release]branch = "main"version_variable = "src/example_app/__init__.py:__version__"version_toml = "pyproject.toml:tool.poetry.version"version_source = "tag"commit_version_number = true # richiesto per version_source = "tag"tag_commit = trueupload_to_pypi = falseupload_to_release = falsehvcs = "github" # supportato anche gitlabbranch: specifica il ramo su cui basare il rilascio, in questo caso il ramo “main”.version_variable: specifica il percorso del file e il nome della variabile del numero di versione nel codice sorgente. In questo caso, il numero di versione è memorizzato nella variabile__version__nel filesrc/example_app/__init__.py.version_toml: specifica il percorso del file e il nome della variabile del numero di versione nel filepyproject.toml. In questo caso, il numero di versione è memorizzato nella variabiletool.poetry.versiondel filepyproject.toml.version_source: specifica la fonte del numero di versione. In questo caso, il numero di versione viene ottenuto dal tag (anziché dal commit).commit_version_number: Questo parametro è richiesto quandoversion_source = "tag". Specifica se il numero di versione deve essere committato nel repository o meno. In questo caso, è impostato su true, il che significa che il numero di versione verrà committato.tag_commit: Specifica se deve essere creato un nuovo tag per il commit del rilascio. In questo caso, è impostato su true, il che significa che verrà creato un nuovo tag.upload_to_pypi: Specifica se il pacchetto deve essere caricato nel repository dei pacchetti PyPI. In questo caso, è impostato su false, il che significa che il pacchetto non verrà caricato su PyPI.upload_to_release: Specifica se il pacchetto deve essere caricato nella pagina dei rilasci di GitHub. In questo caso, è impostato su false, il che significa che il pacchetto non verrà caricato su GitHub releases.hvcs: Specifica il sistema di controllo delle versioni dell’hosting del progetto. In questo caso, è impostato su “github”, il che significa che il progetto è ospitato su GitHub. È supportato anche “gitlab”.
Possiamo aggiornare i file in cui abbiamo definito la versione del progetto/modulo. Per questo utilizziamo la variabile version_variable per i file normali e version_toml per i file .toml. Il version_source definisce la fonte della verità per la versione. Poiché la versione in questi due file è strettamente legata ai tag annotati di git, ad esempio creiamo automaticamente un tag di git con ogni rilascio (il flag tag_commit è impostato su true), possiamo utilizzare la fonte tag invece del valore predefinito commit che cerca l’ultima versione nei messaggi di commit. Per poter aggiornare i file e committare le modifiche, è necessario impostare il flag commit_version_number su true. Poiché non vogliamo caricare nulla nell’indice Python PyPi, il flag upload_to_pypi è impostato su false. E per ora non vogliamo caricare nulla nei nostri rilasci. L’hvcs è impostato su github (predefinito), altri valori possibili sono: gitlab.
Possiamo testare tutto ciò in locale eseguendo alcuni comandi, che aggiungerò direttamente al nostro Makefile:
# Makefile...##@ Rilasciultima-versione: ## restituisce l'ultima versione @semantic-release print-version --currentprossima-versione: ## restituisce la prossima versione @semantic-release print-version --nextchangelog-corrente: ## restituisce il changelog corrente @semantic-release changelog --releasedchangelog-successivo: ## restituisce il changelog successivo @semantic-release changelog --unreleasedpubblica-niente: ## comando di pubblicazione (modalità no-operation) @semantic-release publish --noopCon il comando ultima-versione otteniamo la versione dall’ultimo tag di git nell’albero di git:
> make ultima-versione0.1.0Se aggiungiamo alcuni commit in stile commit convenzionale, ad esempio feat: nuova caratteristica cool o fix: bug fastidioso, quindi il comando prossima-versione calcolerà l’aumento della versione per quello:
> make next-version0.2.0Al momento, non abbiamo un file CHANGELOG nel nostro progetto, quindi quando eseguiamo:
> make current-changelogl’output sarà vuoto. Ma basandoci sui commit, possiamo creare il prossimo changelog con:
> make next-changelog### Nuova funzionalità* Aggiungi release ([#8](https://github.com/johschmidt42/python-project-johannes/issues/8)) ([`5343f46`](https://github.com/johschmidt42/python-project-johannes/commit/5343f46d9879cc8af273a315698dd307a4bafb4d))* Docstrings ([#5](https://github.com/johschmidt42/python-project-johannes/issues/5)) ([`fb2fa04`](https://github.com/johschmidt42/python-project-johannes/commit/fb2fa0446d1614052c133824150354d1f05a52e9))* Aggiungi applicazione in app.py ([`3f07683`](https://github.com/johschmidt42/python-project-johannes/commit/3f07683e787b708c31235c9c5357fb45b4b9f02d))### Documentazione* Aggiungi barra di ricerca e URL di GitHub ([#6](https://github.com/johschmidt42/python-project-johannes/issues/6)) ([`3df7c48`](https://github.com/johschmidt42/python-project-johannes/commit/3df7c483eca91f2954e80321a7034ae3edb2074b))* Aggiungi pagine badge.yml a README.py ([`b76651c`](https://github.com/johschmidt42/python-project-johannes/commit/b76651c5ecb5ab2571bca1663ffc338febd55b25))* Aggiungi documentazione a Makefile ([#3](https://github.com/johschmidt42/python-project-johannes/issues/3)) ([`2294ee1`](https://github.com/johschmidt42/python-project-johannes/commit/2294ee105b238410bcfd7b9530e065e5e0381d7a))Se facciamo push di nuovi commit (direttamente su main o tramite una PR) ora possiamo pubblicare una nuova release con:
> semantic-release publishIl comando di pubblicazione eseguirà una serie di operazioni:
- Aggiornare o creare il file changelog.
- Eseguire semantic-release version .
- Eseguire il push delle modifiche a git.
- Eseguire build_command e caricare il file di distribuzione nel tuo repository.
- Eseguire semantic-release changelog e inviare al tuo provider VCS.
- Allegare i file creati da build_command alle release di GitHub.
Ogni passaggio può ovviamente essere configurato o disattivato!
CI/CD
Creiamo una pipeline CI con GitHub Actions che esegue il comando di pubblicazione di semantic-release ad ogni commit sul ramo principale.
Anche se la struttura generale rimane la stessa di lint.yml , test.yml o pages.yml , ci sono alcune modifiche che devono essere menzionate. Nello step Checkout repository , aggiungiamo un nuovo token che viene utilizzato per fare il checkout del ramo. Questo perché il valore predefinito GITHUB_TOKEN non ha le autorizzazioni necessarie per operare su rami protetti. Pertanto, dobbiamo utilizzare un segreto ( GH_TOKEN ) che contiene un Token di Accesso Personale con autorizzazioni. Successivamente mostrerò come generare il Token di Accesso Personale. Definiamo anche fetch-depth: 0 per scaricare tutta la cronologia per tutti i rami e i tag.
with: ref: ${{ github.head_ref }} token: ${{ secrets.GH_TOKEN }} fetch-depth: 0Installiamo solo le dipendenze necessarie per lo strumento semantic-release con:
- name: Installa requisiti run: poetry install --only semverNell’ultimo passaggio, cambiamo alcune configurazioni git ed eseguiamo il comando di pubblicazione di semantic-release:
- name: Python Semantic Release env: GH_TOKEN: ${{ secrets.GH_TOKEN }} run: | set -o pipefail # Imposta i dettagli git git config --global user.name "github-actions" git config --global user.email "[email protected]" # Esegui semantic-release poetry run semantic-release publish -v DEBUG -D commit_author="github-actions <[email protected]>"Cambiando la configurazione di Git, l’utente che effettua il commit sarà “github-actions”. Eseguiamo il comando di pubblicazione con i log DEBUG (stdout) e impostiamo esplicitamente commit_author su “github-actions”. In alternativa a questo comando, potremmo utilizzare direttamente l’azione GitHub di semantic-release, ma i passaggi di configurazione dell’esecuzione del comando di pubblicazione sono molto pochi e l’azione utilizza un container docker che deve essere scaricato ogni volta. Per questo motivo preferisco creare un passaggio di esecuzione semplice.
Poiché il comando di pubblicazione effettuerà un commit, potresti preoccuparti di finire in un loop infinito di workflow in attesa di essere attivati. Ma non preoccuparti, il commit risultante non attiverà un altro workflow di GitHub Actions. Questo è dovuto alle limitazioni imposte da GitHub.
Crea un Token di Accesso Personale (PAT)
I token di accesso personali sono un’alternativa all’utilizzo delle password per l’autenticazione su GitHub Enterprise Server quando si utilizza l’API di GitHub o la linea di comando. I token di accesso personali sono destinati ad accedere alle risorse di GitHub per conto proprio. Per accedere alle risorse per conto di un’organizzazione o per integrazioni a lunga durata, è consigliabile utilizzare un’app di GitHub. Per ulteriori informazioni, consulta “Informazioni sulle app”.
In altre parole: possiamo creare un Token di Accesso Personale e fare in modo che le azioni di GitHub memorizzino e utilizzino quel segreto per eseguire determinate operazioni per nostro conto. Tieni presente che se il PAT viene compromesso, potrebbe essere utilizzato per compiere azioni dannose nei tuoi repository di GitHub. Pertanto, è consigliabile utilizzare le app di GitHub OAuth e le app di GitHub nelle organizzazioni. A scopo di questo tutorial, utilizzeremo un PAT per consentire al pipeline di GitHub actions di operare per nostro conto.
Possiamo creare un nuovo token di accesso accedendo alla sezione Impostazioni del tuo utente GitHub e seguendo le istruzioni riassunte in “Creazione di un Token di Accesso Personale”. Questo ci darà una finestra che apparirà come questa:
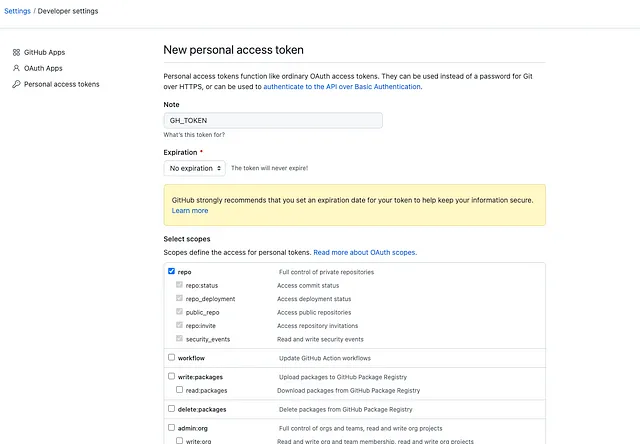
Selezionando le autorizzazioni, definiamo i permessi che avrà il token. Nel nostro caso, abbiamo bisogno di accesso in push ai repository, motivo per cui il nuovo PAT GH_TOKEN dovrebbe avere l’autorizzazione di repo. Questo autorizzerà le push su rami protetti, a patto che non sia impostato Include gli amministratori nelle impostazioni del ramo protetto.
Tornando alla panoramica del repository, nel menu Impostazioni, possiamo aggiungere una variabile di ambiente o una variabile del repository nella sezione Segreti:
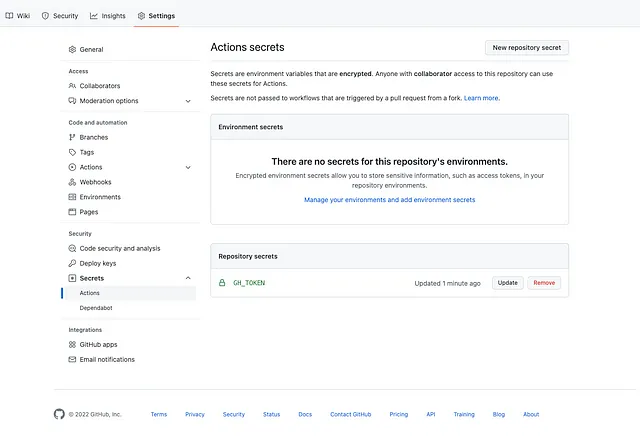
I segreti del repository sono specifici per un singolo repository (e tutti gli ambienti utilizzati al suo interno), mentre i segreti dell’ambiente sono specifici per un ambiente. Il runner di GitHub può essere configurato per eseguire in un ambiente specifico, il che gli consente di accedere ai segreti dell’ambiente. Questo ha senso se si pensa a diverse fasi (ad esempio DEV vs PROD), ma per questo tutorial va bene un segreto del repository.
Flusso di GitHub Actions
Ora che abbiamo alcuni pipeline (linting, testing, rilascio, documentazione), dovremmo pensare al flusso di azioni con un commit su main! Ci sono alcune cose di cui dobbiamo essere consapevoli, alcune delle quali specifiche per GitHub.
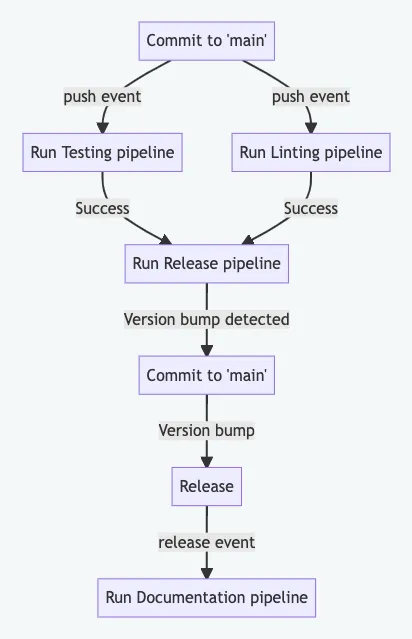
Idealemente, vogliamo che un commit su main crei un evento di push che attivi i workflow di Testing e Linting. Se questi sono completati con successo, eseguiamo il workflow di rilascio che è responsabile per individuare se dovrebbe esserci un incremento di versione basato sui commit convenzionali. Se è così, il workflow di rilascio effettuerà direttamente una push su main, incrementando le versioni, aggiungendo un tag git e creando un rilascio. Un rilascio pubblicato dovrebbe quindi, ad esempio, aggiornare la documentazione eseguendo il workflow di documentazione.
Problemi e considerazioni
- Se hai letto attentamente l’ultimo paragrafo o hai guardato il diagramma di flusso sopra, potresti aver notato che ci sono due commit su main. Uno iniziale (ovvero da una PR) e un secondo per il rilascio. Poiché il nostro lint.yml e test.yml reagiscono agli eventi di push sul ramo principale, verranno eseguiti due volte! Dovremmo evitare di eseguirlo due volte per risparmiare risorse. Per ottenere questo, possiamo aggiungere la stringa
[skip ci]al messaggio di commit della versione. Un messaggio di commit personalizzato può essere definito nel file pyproject.toml per lo strumento semantic_release.
# pyproject.toml...[tool.semantic_release]...commit_message = "{version} [skip ci]" # salta l'attivazione delle pipeline di CI per i commit di versione...2. Attualmente, la pagina del flusso di lavoro pages.yml viene eseguita su un evento di push su main. Aggiornare la documentazione potrebbe essere qualcosa che vogliamo fare solo se c’è un nuovo rilascio (potremmo fare riferimento alla versione nella documentazione). Possiamo cambiare il trigger nel file pages.yml di conseguenza:
# pages.ymlname: Documentazioneon: release: types: [pubblicato]La creazione della documentazione richiederà ora un rilascio pubblicato.
3. Il flusso di lavoro Release dovrebbe dipendere dal successo del flusso di lavoro Linting & Testing. Attualmente non abbiamo definito le dipendenze nei nostri file di flusso di lavoro. Potremmo avere questi flussi di lavoro che dipendono dal completamento dei flussi di lavoro definiti in un ramo specifico con l’evento workflow_run. Tuttavia, se specifichiamo più flussi di lavoro per l’evento workflow_run:
on: workflow_run: workflows: [Testing, Linting] types: - completato branches: - mainsolo uno dei flussi di lavoro deve essere completato! Questo non è quello che vogliamo. Ci aspettiamo che tutti i flussi di lavoro debbano essere completati (e riusciti). Solo allora il flusso di lavoro di rilascio dovrebbe essere eseguito. Questo è in contrasto con quello che otteniamo quando definiamo le dipendenze tra job in un singolo flusso di lavoro. Leggi di più su questa incongruenza e mancanza qui.
Come alternativa, potremmo utilizzare un’esecuzione sequenziale delle pipeline:
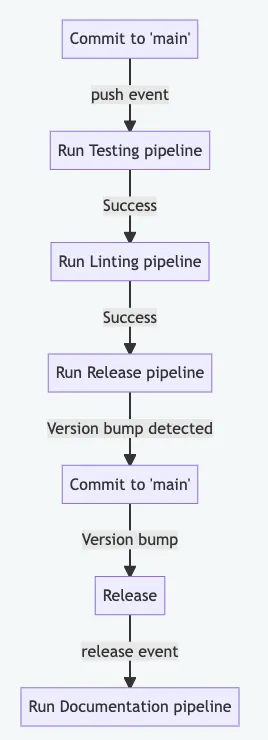
Il grande svantaggio di questa idea è che a) non consente l’esecuzione in parallelo e b) non saremo in grado di vedere il grafico delle dipendenze su GitHub.
Soluzione
Attualmente, l’unico modo che vedo per affrontare i problemi sopra menzionati è orchestrare i flussi di lavoro in un flusso di lavoro di orchestratore.
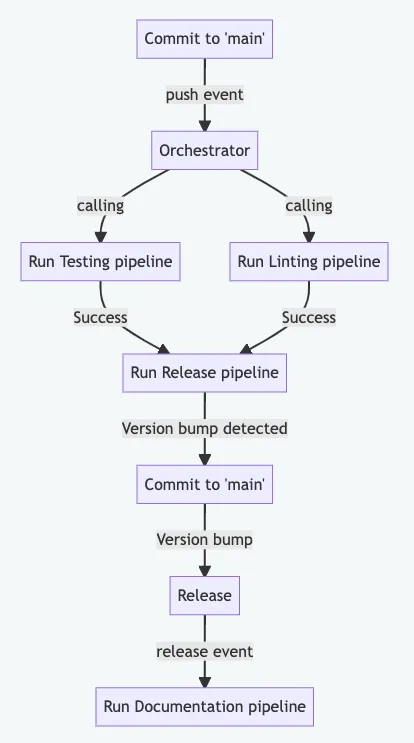
Creiamo questo file di flusso di lavoro:
L’orchestratore viene attivato quando facciamo push sul ramo main.
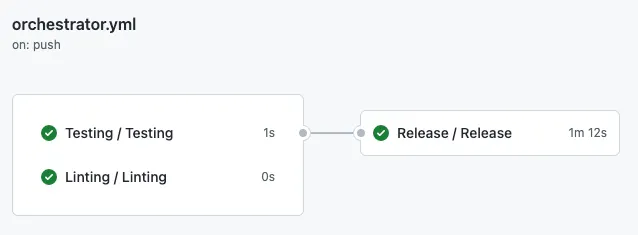
Solo se entrambi i flussi di lavoro: Testing & Linting riescono, viene chiamato il flusso di lavoro di rilascio. Questo è definito con la parola chiave needs. Se vogliamo avere un controllo più granulare sulle esecuzioni dei job (flussi di lavoro), considera anche l’utilizzo della parola chiave if. Ma sii consapevole del comportamento confusionario come spiegato in questo articolo.
Per rendere i nostri flussi di lavoro lint.yml, test.yml & release.yml richiamabili da un altro flusso di lavoro, è necessario aggiornare i trigger:
# lint.yml---name: Lintingon: pull_request: branches: - main workflow_call:jobs:...
# test.yml---name: Testingon: pull_request: branches: - main workflow_call:jobs:...
# release.yml---name: Releaseon: workflow_call:jobs:...Ora il nuovo flusso di lavoro (Release) dovrebbe essere eseguito solo se i flussi di lavoro per il controllo della qualità, in questo caso il linting e il testing, hanno successo.
Badge
Per creare un badge, questa volta userò la piattaforma shields.io.
È un sito web che genera badge per progetti, che mostrano informazioni come la versione, lo stato di build e la copertura del codice. Offre una vasta gamma di modelli e consente la personalizzazione dell’aspetto e la creazione di badge personalizzati. I badge vengono aggiornati automaticamente, fornendo informazioni in tempo reale sul progetto.
Per un badge di rilascio, ho selezionato GitHub release (ultima SemVer):
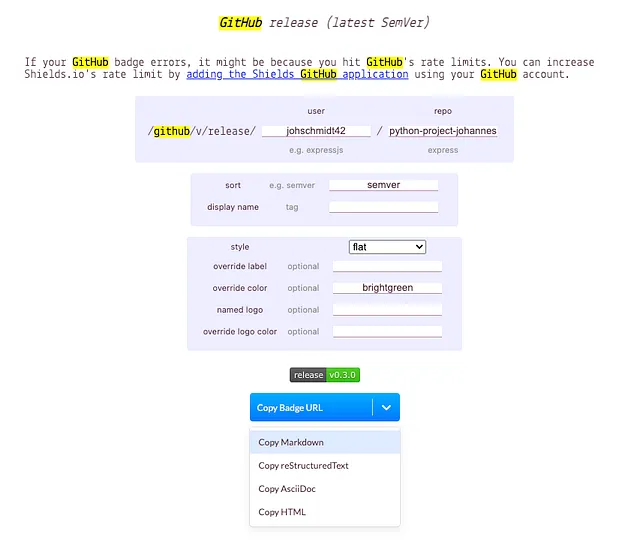
Il markdown del badge può essere copiato e aggiunto al README.md:
La nostra pagina iniziale di GitHub ora appare così ❤ (ho fatto un po’ di pulizia e fornito una descrizione):
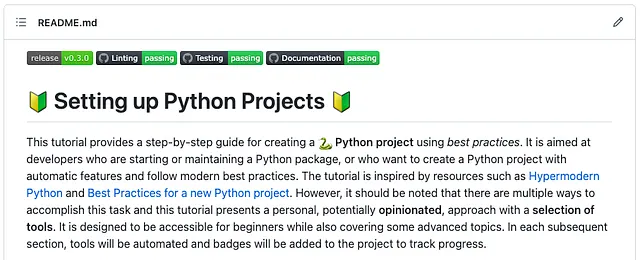
Congratulazioni! Hai completato la parte principale di questo tutorial! Hai imparato i passaggi essenziali per gestire i rilasci del software. Abbiamo iniziato creando manualmente un rilascio, e poi abbiamo sfruttato il potere dei Conventional Commits per automatizzare il nostro processo di rilascio attraverso una pipeline CI, che si occupa della versioning per nostro conto. Per concludere, abbiamo aggiunto un badge nel nostro file README.md, fornendo una visualizzazione chiara e concisa dell’ultima versione del nostro progetto per i nostri utenti. Con queste tecniche a disposizione, sarai in grado di gestire in modo efficiente ed efficace i tuoi rilasci software.
La prossima parte sarà l’ultima parte, che tratta: Containerisation!
Unisciti a VoAGI con il mio link di riferimento – Johannes Schmidt
Leggi ogni storia di Johannes Schmidt (e migliaia di altri scrittori su VoAGI). La tua quota di iscrizione direttamente…
johschmidt42.medium.com
Bonus
Assicurati i Conventional Commits
Abbiamo visto che i commit in un formato definito possono aiutarci con la versioning. In un progetto collaborativo, probabilmente vogliamo imporre questo formato per tutti i commit nel branch predefinito. Due strumenti popolari possono aiutare gli sviluppatori a seguire il formato dei commit convenzionali:
- commitizen
- commitlint
Tuttavia, alcuni sviluppatori ritengono che questi strumenti siano un po’ restrittivi e preferiscono evitarli*. Quindi probabilmente è una cattiva idea sperare che ci siano sempre commit convenzionali. Pertanto, ha senso imporre regole, come il formato dei commit convenzionali, sul lato server!
*Lo stesso vale per i pre-commit hooks, motivo per cui li ho esclusi in questa serie.
Purtroppo, attualmente non è possibile (maggio 2023) bloccare i commit basati su regole su GitHub poiché la funzionalità per questo è ancora aperta. Ma possiamo cercare di avvicinarci il più possibile tramite regole di protezione del branch e un flusso di lavoro CI. Ecco quindi le cose che richiediamo per una tale strategia nel nostro repository:
- I commit nel branch predefinito protetto (ad es. main) dovrebbero essere limitati ai commit delle pull request (PR).
- Dovrebbero essere consentiti solo commit compressi*
- Il messaggio di commit predefinito presentato durante la fusione di una pull request con compressione dovrebbe essere il titolo della pull request
Se l’unico modo per effettuare commit nel branch predefinito protetto (ad es. main) è tramite una pull request (solo commit compressi), possiamo utilizzare una GitHub Action, come amannn/action-semantic-pull-request, che garantisce che il titolo della pull request corrisponda allo spec delle Conventional Commits. Quindi, quando squash and merge il branch della PR (supponendo che tutte le pipeline richieste abbiano successo), il messaggio di commit suggerito è il titolo della PR che è stato precedentemente controllato dall’esecuzione dell’azione di GitHub.
*La strategia di squash and merge è un metodo popolare per unire le modifiche del codice da un branch di feature nel branch principale, che prevede la riduzione di più commit in un singolo commit. Ciò crea una cronologia git lineare e coerente, in cui ogni commit rappresenta una modifica specifica. Tuttavia, questo metodo ha i suoi svantaggi, poiché scarta la cronologia granulare dei commit, che può essere preziosa per comprendere il processo di sviluppo. Sebbene sia possibile utilizzare il rebase merging per conservare queste informazioni, può introdurre complessità nel flusso di lavoro. In questo senso, la strategia di squash and merge è preferita per la sua semplicità.
Flusso di lavoro
Creiamo il flusso di lavoro di GitHub Actions per questa strategia:
L’evento di trigger pull_request_target è spiegato qui . Utilizzo i tipi suggeriti opened , edited , synchronize . Il GITHUB_TOKEN viene passato come env all’azione. Quindi, ogni volta che viene modificato il titolo in una PR, viene attivato il flusso di lavoro. Avrà successo solo se il titolo della PR è nel formato di commit convenzionale.
Si prega di notare che
è necessario avere questa configurazione nel ramo principale affinché l’azione possa essere eseguita (ad esempio, non verrà eseguita all’interno di una PR che aggiunge l’azione inizialmente). Inoltre, se si modifica la configurazione in una PR, le modifiche non verranno riflesse per la PR corrente, ma solo per quelle successive dopo che le modifiche sono state apportate nel ramo principale.
Quindi dobbiamo avere questo flusso di lavoro nel nostro ramo predefinito main prima di poterlo vedere in azione.
Regole di protezione del ramo
Successivamente, nella sezione Impostazioni del repository di GitHub, possiamo creare una regola di protezione del ramo per il ramo principale:

Ora un commit richiede una PR con controlli di stato superati (flusso di lavoro richiesto) prima della fusione*.
Un flusso di lavoro richiesto viene attivato dagli eventi della pull request e appare come un controllo di stato richiesto, che blocca la possibilità di eseguire la fusione della pull request fino a quando il flusso di lavoro richiesto ha successo.

I proprietari dell’organizzazione hanno la possibilità di imporre flussi di lavoro specifici all’interno della loro organizzazione, ad esempio richiedere un controllo di stato sulle pull request. Purtroppo, questa funzionalità è disponibile solo per le organizzazioni e non può essere attivata per gli account individuali, quindi non è possibile bloccare la fusione.
*Si prega di notare che le regole non saranno applicate su un repository privato fino a quando non viene spostato in un account di GitHub Team o Enterprise!
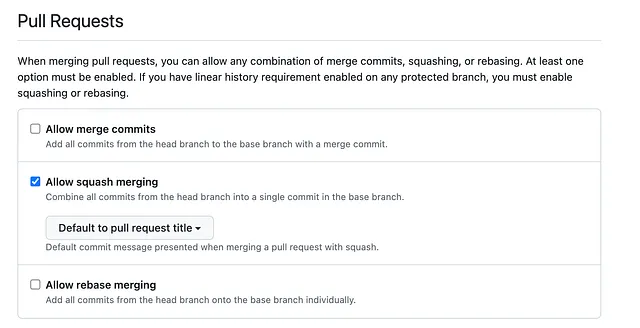
Strategia di squash & merge
Infine, possiamo configurare le opzioni della PR per utilizzare il titolo della PR come messaggio di commit predefinito quando selezioniamo il pulsante squash and merge:
In questo modo, vedremo una finestra come questa:
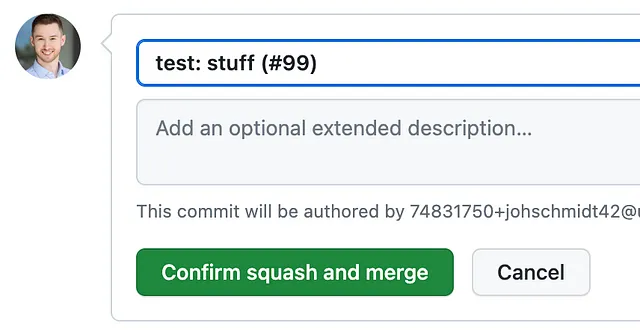
Si prega di notare che uno sviluppatore potrebbe modificare il nome del titolo durante la fusione, il che eluderebbe la strategia!
Anche se non possiamo garantire completamente commit convenzionali su GitHub ancora, dovremmo cercare di avvicinarci il più possibile.