Clustering Scatenato Comprendere il Clustering K-Means
Comprendere il Clustering K-Means

Mentre analizziamo i dati, la cosa che ci passa per la mente è trovare pattern nascosti ed estrarre informazioni significative. Entriamo nella nuova categoria di apprendimento basato su ML, ovvero l’apprendimento non supervisionato, in cui uno degli algoritmi potenti per risolvere i compiti di clustering è l’algoritmo di clustering K-Means che rivoluziona la comprensione dei dati.
K-Means è diventato un algoritmo utile nelle applicazioni di machine learning e data mining. In questo articolo, approfondiremo i meccanismi di K-Means, la sua implementazione utilizzando Python ed esploreremo i suoi principi, le applicazioni, ecc. Quindi, iniziamo il viaggio per sbloccare i pattern segreti e sfruttare il potenziale dell’algoritmo di clustering K-Means.
- OpenAI fa una anteprima del rilascio del modello GPT in open-source
- Crea un agente di intelligenza artificiale con ChatGPT
- head () e tail () Funzioni spiegate con Esempi e Codici
Cos’è l’algoritmo K-Means?
L’algoritmo K-Means viene utilizzato per risolvere i problemi di clustering che appartengono alla classe dell’apprendimento non supervisionato. Con l’aiuto di questo algoritmo, possiamo raggruppare un certo numero di osservazioni in K cluster.
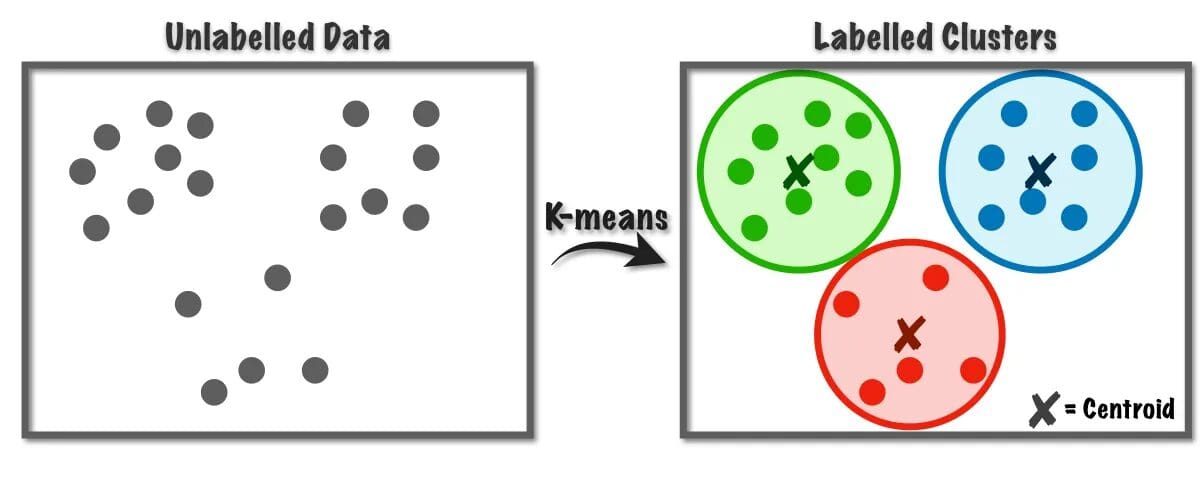
Questo algoritmo utilizza internamente la quantizzazione vettoriale, attraverso la quale possiamo assegnare ogni osservazione nel dataset al cluster con la distanza minima, che è il prototipo dell’algoritmo di clustering. Questo algoritmo di clustering è comunemente usato in data mining e machine learning per la suddivisione dei dati in K cluster basati su metriche di similarità. Pertanto, in questo algoritmo, dobbiamo minimizzare la somma delle distanze quadratiche tra le osservazioni e i loro centroidi corrispondenti, il che porta infine a cluster distinti ed omogenei.
Applicazioni del clustering K-means
Ecco alcune delle applicazioni standard di questo algoritmo. L’algoritmo K-means è una tecnica comunemente utilizzata in casi d’uso industriali per risolvere problemi legati al clustering.
- Segmentazione dei clienti: Il clustering K-means può suddividere i diversi clienti in base ai loro interessi. Può essere applicato in ambito bancario, delle telecomunicazioni, del commercio elettronico, dello sport, della pubblicità, delle vendite, ecc.
- Clustering dei documenti: In questa tecnica, raggruppiamo documenti simili da un insieme di documenti, ottenendo documenti simili nello stesso cluster.
- Motori di raccomandazione: A volte, il clustering K-means può essere utilizzato per creare sistemi di raccomandazione. Ad esempio, si desidera consigliare canzoni ai propri amici. È possibile guardare le canzoni piaciute a quella persona e quindi utilizzare il clustering per trovare canzoni simili e consigliare quelle più simili.
Ci sono molte altre applicazioni che sono sicuro avete già pensato, che potete condividere nella sezione commenti di seguito a questo articolo.
Implementazione del clustering K-Means utilizzando Python
In questa sezione, inizieremo a implementare l’algoritmo K-Means su uno dei dataset utilizzando Python, principalmente utilizzato in progetti di Data Science.
1. Importa le librerie e le dipendenze necessarie
Prima di tutto, importiamo le librerie Python che utilizzeremo per implementare l’algoritmo K-means, tra cui NumPy, Pandas, Seaborn, Matplotlib, ecc.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
2. Carica ed analizza il dataset
In questa fase, caricheremo il dataset degli studenti salvandolo nel dataframe di Pandas. Per scaricare il dataset, puoi fare riferimento al link qui.
Il processo completo del problema è mostrato di seguito:

df = pd.read_csv('student_clustering.csv')
print("La forma dei dati è",df.shape)
df.head()
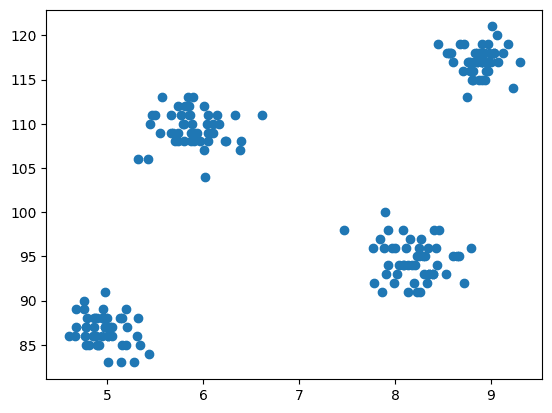
3. Grafico a dispersione del dataset
Adesso viene il passo della modellazione che consiste nella visualizzazione dei dati, quindi utilizziamo matplotlib per disegnare il grafico a dispersione per verificare come funziona l’algoritmo di clustering e creare diversi cluster.
# Grafico a dispersione del dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Output:
4. Importa il K-Means dalla Classe Cluster di Scikit-learn
Ora, poiché dobbiamo implementare il clustering K-Means, importiamo prima la classe di cluster e quindi abbiamo KMeans come modulo di quella classe.
from sklearn.cluster import KMeans
5. Trovare il Valore Ottimale di K utilizzando il Metodo dell’Gomito
In questo passaggio, troveremo il valore ottimale di K, uno degli iperparametri, durante l’implementazione dell’algoritmo. Il valore K indica quanti cluster dobbiamo creare per il nostro dataset. Trovare intuitivamente questo valore non è possibile, quindi per trovare il valore ottimale, creeremo un grafico tra WCSS (somma dei quadrati all’interno del cluster) e diversi valori di K, e dovremo scegliere quel K che ci dà il valore minimo di WCSS.
# crea una lista vuota per memorizzare i residui
wcss = []
for i in range(1,11):
# crea un oggetto della classe K-Means
km = KMeans(n_clusters=i)
# passa il dataframe per adattare l'algoritmo
km.fit_predict(df)
# aggiungi il valore di inerzia alla lista wcss
wcss.append(km.inertia_)
Ora, tracciamo il grafico dell’gomito per trovare il valore ottimale di K.
# Grafico di WCSS vs. K per verificare il valore ottimale di K
plt.plot(range(1,11),wcss)
Output:
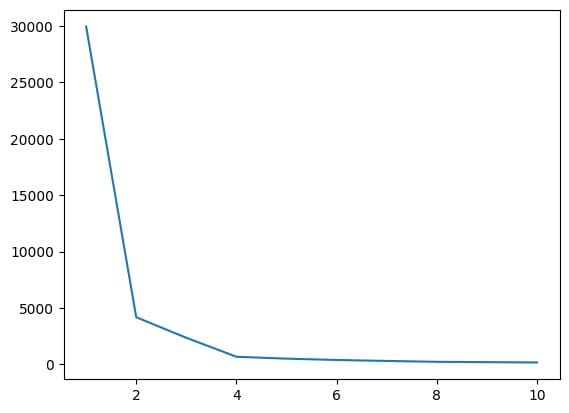
Dal grafico dell’gomito sopra, possiamo vedere che a K=4; c’è un calo del valore di WCSS, il che significa che se usiamo il valore ottimale come 4, in quel caso, il clustering ci darà una buona performance.
6. Adatta l’Algoritmo K-Means con il Valore Ottimale di K
Siamo riusciti a trovare il valore ottimale di K. Ora, facciamo la modellazione in cui creeremo un array X che memorizza l’intero dataset con tutte le caratteristiche. Qui non c’è bisogno di separare il vettore target e le caratteristiche, poiché è un problema non supervisionato. Dopo di che, creeremo un oggetto della classe KMeans con un valore K selezionato e quindi lo adatteremo al dataset fornito. Infine, stampiamo y_means, che indica le medie dei diversi cluster formati.
X = df.iloc[:,:].values # viene utilizzato l'intero dataset per la costruzione del modello
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means
7. Verifica l’Assegnazione del Cluster di ogni Categoria
Verifichiamo a quali punti del dataset appartengono i cluster.
X[y_means == 3,1]
Fino ad ora, per l’inizializzazione dei centroidi, abbiamo utilizzato la strategia K-Means++, ora, inizializziamo i centroidi casuali invece di K-Means++ e confrontiamo i risultati seguendo lo stesso processo.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Verifica quanti valori corrispondono.
sum(y_means == y_means_new)
8. Visualizzazione dei cluster
Per visualizzare ogni cluster, li disegnamo sugli assi e assegniamo colori diversi attraverso i quali possiamo vedere facilmente i 4 cluster formati.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red')
plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green')
plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Output:

9. K-Means su dati 3D
Dato che il dataset precedente ha 2 colonne, abbiamo un problema 2D. Ora, utilizzeremo lo stesso set di passaggi per un problema 3D e cercheremo di analizzare la riproducibilità del codice per dati n-dimensionali.
# Crea un dataset sintetico da sklearn
from sklearn.datasets import make_blobs # crea un dataset sintetico
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
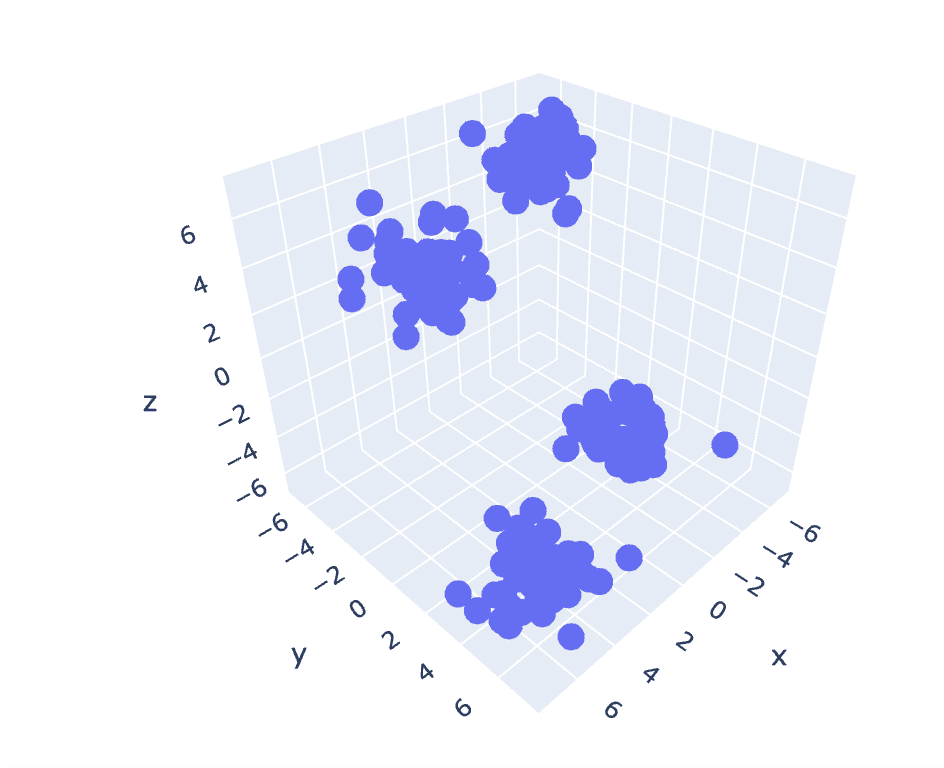
# Grafico a dispersione del dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Output:
wcss = []
for i in range(1,21):
km = KMeans(n_clusters=i)
km.fit_predict(X)
wcss.append(km.inertia_)
plt.plot(range(1,21),wcss)
Output:
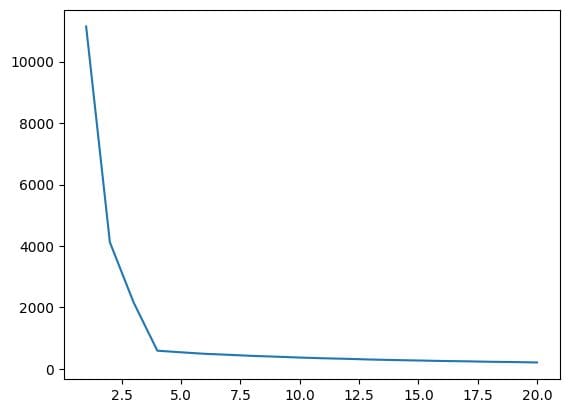 Fig.7 Grafico del gomito | Immagine dell’autore
Fig.7 Grafico del gomito | Immagine dell’autore
# Addestra l'algoritmo K-Means con il valore ottimale di K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analizza i diversi cluster formati
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred
fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Output:
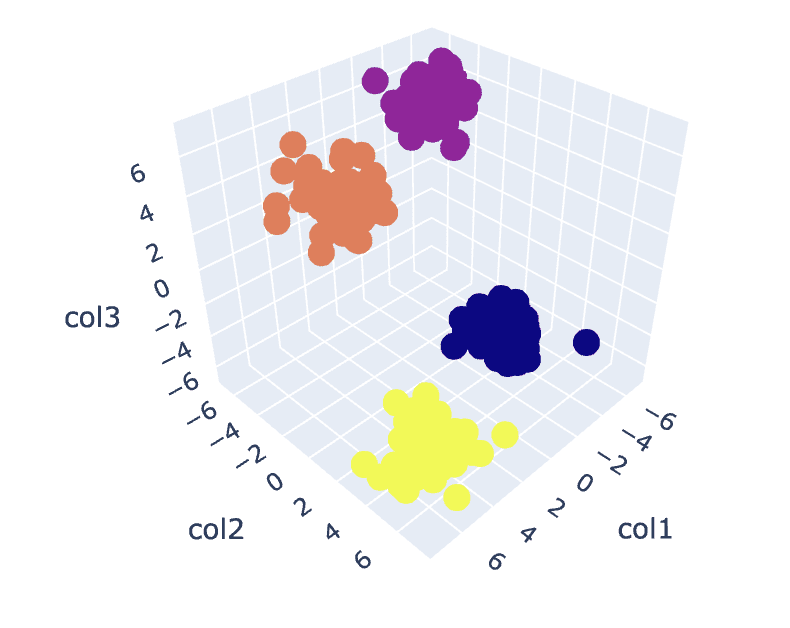 Fig.8 Visualizzazione dei cluster | Immagine dell’autore
Fig.8 Visualizzazione dei cluster | Immagine dell’autore
Puoi trovare il codice completo qui – Colab Notebook
Conclusione
Questo completa la nostra discussione. Abbiamo discusso il funzionamento, l’implementazione e le applicazioni di K-Means. In conclusione, l’implementazione delle attività di clustering è un algoritmo ampiamente utilizzato nella classe di apprendimento non supervisionato che fornisce un approccio semplice e intuitivo per raggruppare le osservazioni di un dataset. Il principale punto di forza di questo algoritmo è quello di dividere le osservazioni in più insiemi in base alle metriche di similarità selezionate con l’aiuto dell’utente che sta implementando l’algoritmo.
Tuttavia, in base alla selezione dei centroidi nel primo passaggio, il nostro algoritmo si comporta in modo differente e converge a ottimi locali o globali. Pertanto, selezionare il numero di cluster per implementare l’algoritmo, preelaborare i dati, gestire gli outlier, ecc., è cruciale per ottenere buoni risultati. Ma se osserviamo l’altro lato di questo algoritmo dietro le limitazioni, K-Means è una tecnica utile per l’analisi esplorativa dei dati e il riconoscimento dei pattern in diversi campi. Aryan Garg è uno studente di Ingegneria Elettrica B.Tech., attualmente all’ultimo anno del suo corso di laurea. Il suo interesse si concentra nel campo dello sviluppo web e dell’apprendimento automatico. Ha coltivato questo interesse ed è desideroso di lavorare ulteriormente in queste direzioni.






