Come le soluzioni GenAI rivoluzionano l’automazione aziendale Svelare le applicazioni LLM per gli executive
Come GenAI rivoluziona l'automazione aziendale con le applicazioni LLM per gli executive
Come le aziende possono applicare il potere degli LLM per automatizzare i flussi di lavoro e ottenere efficienze di costi
Introduzione
In una recente collaborazione con dirigenti aziendali di un’azienda biotech, ci siamo addentrati nel mondo dell’IA generativa, in particolare dei modelli di linguaggio di grandi dimensioni (LLM), per esplorare come potessero essere utilizzati per accelerare le indagini sulla qualità. Le indagini sulla qualità vengono avviate quando vengono identificate deviazioni nella produzione o nei test dei prodotti. A causa dei potenziali rischi per la salute dei pazienti e delle normative vigenti, il lotto viene messo in attesa e, a seconda dell’impatto, potrebbe persino essere sospesa la produzione. Accelerare le indagini per eseguire un’analisi delle cause e attuare un piano di azioni correttive e preventive il più velocemente possibile è fondamentale. Il nostro obiettivo era accelerare questo processo utilizzando GenAI, ove possibile.
Nel momento in cui abbiamo iniziato a pensare al prodotto minimo viable (MVP), ci siamo trovati di fronte a diverse opzioni riguardo a come GenAI potesse automatizzare diverse fasi del processo per migliorare i tempi di ciclo e sbloccare i lotti il più rapidamente possibile. I dirigenti erano esperti nel loro campo e avevano seguito corsi di formazione su GenAI. Tuttavia, era necessario approfondire le capacità degli LLM e i vari modelli di soluzioni di GenAI per determinare quale fase del processo di indagine sulla qualità privilegiare per l’MVP, bilanciando la fattibilità delle soluzioni a breve termine con il miglioramento atteso dei tempi di ciclo.
Mentre nel nostro caso la discussione si è concentrata su un processo specifico, lo stesso modello di soluzione viene utilizzato in vari settori e funzioni per estrarre efficientemente i costi e accelerare i risultati. Quindi, come possono le soluzioni di GenAI aiutare in un tale processo?
Le capacità uniche degli LLM
Prima del recente aumento della popolarità di GenAI, le soluzioni di automazione nel mondo aziendale si rivolgevano principalmente a compiti di routine basati su regole o si basavano sull’automazione dei processi robotici (RPA). Le applicazioni di machine learning si concentravano principalmente sull’analisi, ad esempio utilizzando modelli di regressione per prevedere risultati come i volumi di vendita. Tuttavia, gli ultimi LLM si distinguono per le loro notevoli proprietà:
- Classificazione con il Perceptron di Rosenblatt
- Argomenti per classe utilizzando BERTopic
- Novità al Summit Ai X Business e Innovazione
- Comprensione del contenuto: gli LLM sono in grado di “capire” il significato del testo
- Addestramento in tempo reale: gli LLM sono in grado di svolgere nuovi compiti che non facevano parte del loro addestramento originale (noto come apprendimento zero-shot), guidati da istruzioni in linguaggio naturale e, eventualmente, da alcuni esempi (apprendimento few-shot)
- Ragionamento: gli LLM sono in grado di “pensare” e “ragionare” su potenziali azioni in una certa misura (sebbene con alcune limitazioni e rischi)
Nel machine learning “convenzionale”, il processo di costruzione e utilizzo di un modello coinvolgeva principalmente la raccolta di dati, la definizione di un “target” manualmente e l’addestramento del modello per prevedere il “target” dato altre proprietà. Quindi, i modelli potevano svolgere un solo compito specifico o rispondere a un solo tipo di domanda. Al contrario, è possibile chiedere a un LLM pre-addestrato di valutare una recensione del cliente su aspetti specifici importanti per la tua attività che né l’LLM ha mai visto prima né sono menzionati esplicitamente nella recensione.
La meccanica delle soluzioni basate su LLM
Le molte soluzioni di LLM nell’industria si concentrano sulla progettazione e l’invio di istruzioni dettagliate per far sì che gli LLM svolgano compiti specifici (questo è noto come prompt-engineering). Un modo efficace per amplificare l’impatto degli LLM è consentire loro di accedere alle informazioni proprietarie di un’azienda in modo automatico. La Generazione con Recupero Integrato (RAG) è emersa come uno dei modelli di soluzione più comuni per raggiungere questo obiettivo.
Panoramica – Una vista a 10.000 piedi
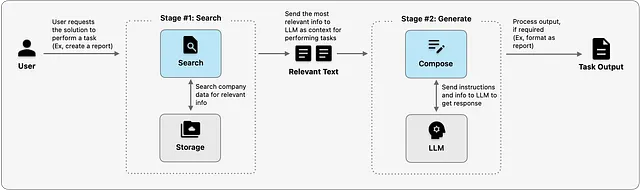
In termini semplici, la soluzione ha due fasi:
- Ricerca: Recuperare i dati aziendali rilevanti per la richiesta dell’utente. Ad esempio, se la richiesta è quella di scrivere un report in un formato o stile specifico, viene recuperato il testo di un report precedente e inviato all’LLM come esempio
- Generazione: Comporre istruzioni ed esempi (o qualsiasi altra informazione rilevante) recuperati nella fase precedente in un prompt di testo e inviarlo all’LLM per generare l’output desiderato. Nel caso del report, il prompt potrebbe essere,
Si prega di compilare le seguenti informazioni in un report, utilizzando il formato e lo stile dell’esempio fornito. Ecco il contenuto: [contenuto del report …]. Ecco l’esempio: [Titolo del report precedente Sezione 1 … Sezione 2 … Conclusioni]
Il workflow RAG – Vista a 1000 piedi
Andiamo un po’ più in profondità sia nella fase di ricerca che nella fase di generazione del modello di soluzione.
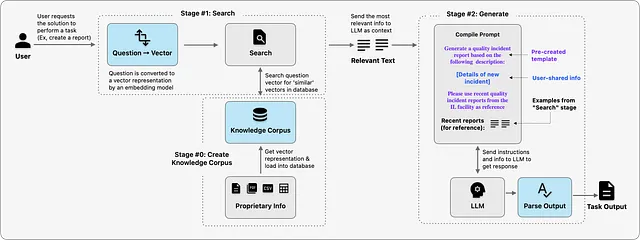
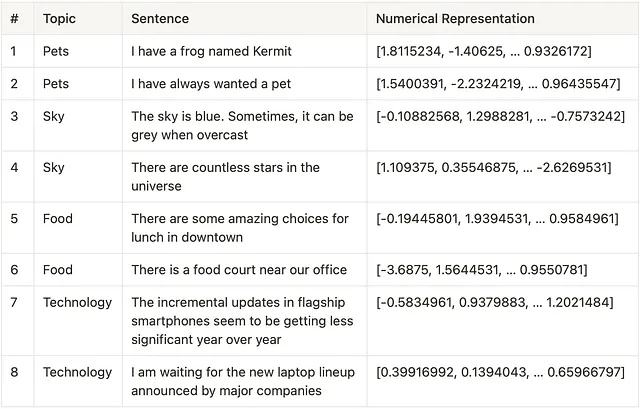
1. Word Embeddings – la base per la “comprensione” del linguaggio: Per facilitare la comprensione del linguaggio naturale, il testo viene elaborato attraverso algoritmi o attraverso LLM per ottenere una rappresentazione numerica (nota come embedding vettoriale) che cattura il significato e il contesto dei dati. La lunghezza è determinata dal modello utilizzato per creare questa rappresentazione: alcuni modelli come word2vec hanno lunghezze vettoriali fino a 300, mentre GPT-3 utilizza vettori di lunghezza fino a 12.288. Ad esempio,
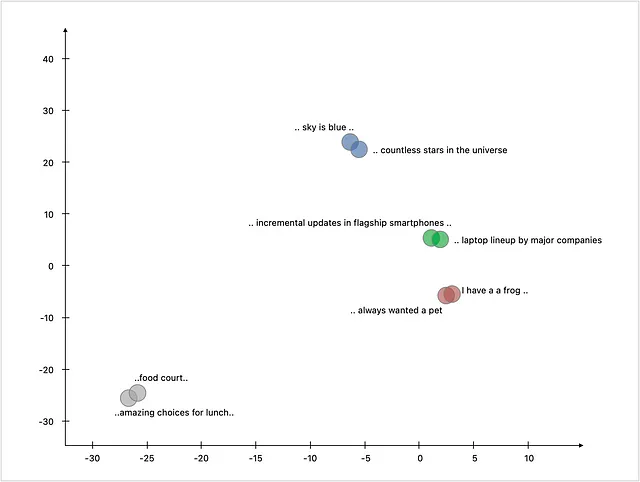
Ecco come queste rappresentazioni numeriche si mappano su uno spazio bidimensionale. È interessante notare che le frasi su argomenti simili sono mappate vicine l’una all’altra.
2. Creazione del Corpus di Conoscenza: La componente di ricerca della soluzione prende una domanda in entrata ed esegue una ricerca semantica per trovare i pezzi di informazione più simili disponibili nel corpus di conoscenza. Quindi, come viene creato questo corpus di conoscenza? I file che devono far parte del corpus di conoscenza vengono elaborati da un modello di embedding, che crea rappresentazioni numeriche. Queste rappresentazioni numeriche vengono caricate in un database specializzato, generalmente un database vettoriale appositamente progettato per archiviare questo tipo di informazioni in modo efficiente e recuperarle rapidamente quando necessario.
3. Ricerca di Informazioni Simili nel Corpus di Conoscenza (cioè Recupero): Quando un utente invia una domanda o un compito alla soluzione, la soluzione utilizza un modello di embedding per convertire il testo della domanda in una rappresentazione numerica. Questo vettore di domanda viene confrontato con il corpus di conoscenza per trovare i pezzi di informazione più simili. Possono essere restituiti uno o più risultati di ricerca, che possono essere passati alla fase successiva per generare una risposta o un output.
4. Generazione dell’Output Utilizzando LLM (cioè Generazione): Ora che la soluzione è riuscita a trovare pezzi di informazione rilevanti che possono aiutare LLM a generare un output significativo, l’intero pacchetto, noto come “prompt”, può essere inviato a LLM. Questo prompt include uno o più set standard di istruzioni che guidano LLM, la domanda effettiva dell’utente e infine i pezzi di informazione recuperati nella fase di ricerca. L’output risultante da LLM può essere elaborato, se necessario (ad esempio, caricare gli output in un formato specifico in un documento di Word), prima di essere restituito all’utente.
Uno Sguardo più Approfondito ai Componenti della Soluzione
Andiamo un passo più in profondità nei componenti della soluzione

1. Creare un Corpus di Conoscenza: Caricare documenti rilevanti in un Corpus di Conoscenza ha delle sfumature e coinvolge diverse considerazioni.
- Caricamento dei Documenti: Diversi documenti rilevanti (pdf, word, fonti online, ecc.) potrebbero dover essere importati in un repository di dati. A seconda del caso d’uso, solo alcune porzioni selezionate di alcuni documenti potrebbero essere rilevanti. Ad esempio, in una soluzione progettata per gli analisti finanziari per interrogare i rapporti 10-K dell’azienda, sezioni come la pagina del titolo, la tabella dei contenuti, le informazioni di conformità standardizzate e alcuni allegati potrebbero non essere rilevanti per l’analisi finanziaria. Pertanto, queste sezioni possono essere omesse dalla banca di conoscenza. È fondamentale evitare informazioni ridondanti nella banca di conoscenza per garantire risposte diverse e di alta qualità dal modello LLM.
- Divisione dei Documenti: Una volta identificate le sezioni dei documenti rilevanti da includere nella banca di conoscenza, il passo successivo è determinare come dividere queste informazioni e caricarle nel database vettoriale. La scelta può variare a seconda del caso d’uso. Un approccio efficace è suddividere per paragrafi con un certo sovrapposizione. Ciò comporta l’impostazione di un limite di parole (o ‘token’, le unità utilizzate dai modelli LLM per l’elaborazione del testo) per mantenere un intero paragrafo. Se un paragrafo supera questo limite, dovrebbe essere diviso in più record per il database vettoriale. Tipicamente, viene mantenuto un certo sovrapposizione di parole per preservare il contesto. Ad esempio, utilizzando un limite di 1.000 parole per vettore con un sovrapposizione di 40 parole.
- Metadati Aggiuntivi: Migliorare le informazioni nella banca di conoscenza comporta l’aggiunta di metadati significativi a ciascun record. Esempi di metadati di base includono il titolo originale del documento da cui sono state estratte le informazioni e la gerarchia delle sezioni. I metadati aggiuntivi possono migliorare ulteriormente la qualità della ricerca e del recupero. Ad esempio, i dati del bilancio estratti da un rapporto 10-K potrebbero essere contrassegnati con metadati come:
Titolo Originale del Documento: Company XYZ 10-KAnno: 2022Sezione: Stati Finanziari e Dati Integrativi | Bilancio
- Archiviazione: Ci sono varie opzioni disponibili per archiviare le informazioni. Si può utilizzare una soluzione di database vettoriale come chroma o Faiss su Postgres / MySQL. Tuttavia, possono essere utilizzati anche database SQL, database NoSQL o Document store, database Graph. Inoltre, ci sono possibilità di archiviazione in memoria per ridurre la latenza, così come la scalabilità orizzontale per migliorare la scalabilità, la disponibilità, il bilanciamento del carico, ecc.
2. Ricerca di Informazioni Simili dal Corpus di Conoscenza (Recupero): Per casi d’uso semplici, un approccio di recupero basato sulla ricerca di vettori simili nella banca di conoscenza, come discusso nella sezione precedente, dovrebbe essere sufficiente. Un approccio comune a due fasi bilancia la velocità di ricerca con l’accuratezza:
- Recupero Denso: Inizialmente, viene effettuata una scansione rapida del vasto corpus di conoscenza utilizzando ricerche approssimative del vicino più prossimo per una query di ricerca. Ciò fornisce decine o centinaia di risultati per una valutazione ulteriore.
- Reranking: Tra i candidati recuperati, è possibile utilizzare algoritmi più intensivi dal punto di vista computazionale per discernere tra risultati più o meno rilevanti. È possibile calcolare ulteriori punteggi di rilevanza sia effettuando un secondo passaggio sui candidati recuperati dalla fase di Recupero Denso, sia utilizzando ulteriori caratteristiche come il numero di link che puntano a ciascun risultato di ricerca (indicando autorevolezza o autorità tematica), punteggi TF-IDF o chiedendo direttamente a un LLM di rivedere tutti i candidati e classificarli per rilevanza.
Per funzionalità avanzate, come migliorare la qualità dei risultati di ricerca selezionando informazioni diverse, applicare filtri basati su prompt di utenti in linguaggio semplice, ecc., potrebbe essere necessario un approccio più sofisticato. Ad esempio, in una query finanziaria in cui un utente chiede: “Qual è stato il profitto netto per Company XYZ nel 2020?”, la soluzione deve filtrare i documenti per Company XYZ e l’anno 2020. Una possibile soluzione prevede l’utilizzo di un LLM per suddividere la richiesta in un componente di filtraggio che riduce gli obiettivi di ricerca semantica filtrando sull’anno 2020 utilizzando i metadati. Successivamente, viene eseguita una ricerca semantica per individuare “profitto netto per Company XYZ” all’interno della banca di conoscenza.
3. Generare Output utilizzando LLM (Generazione): L’ultimo passo del processo consiste nella generazione dell’output utilizzando un LLM
- Approccio Diretto: L’approccio diretto consiste nel passare tutte le informazioni recuperate dalla Fase di Ricerca al LLM, insieme alla richiesta umana e alle istruzioni. Tuttavia, c’è un limite su quante informazioni possono essere passate a un LLM. Ad esempio, il modello base Azure OpenAI GPT-4 ha una dimensione di contesto di 1024 token, equivalente approssimativamente a 2 pagine di testo. A seconda del caso d’uso, potrebbero essere necessarie soluzioni alternative per superare questo limite.
- Catenelle: Per superare il limite di dimensione del contesto, un approccio consiste nel fornire successivamente pezzi di informazione al modello di linguaggio e istruirlo a costruire e perfezionare la sua risposta con ogni iterazione. Il framework LangChain offre metodi come “refine”, “map_reduce” e “map_rerank” per facilitare la generazione di diverse parti di risposte utilizzando un modello di linguaggio e infine combinarle utilizzando un’altra chiamata LLM.
Conclusion
In un’era di generazione dati sempre crescente, sfruttare il potere di GenAI, il nostro assistente consapevole del contesto e addestrabile, non è mai stato così impattante. Questo modello di soluzione, come descritto nell’articolo, affronta in modo fluido la sfida dell’automazione del trattamento dei dati e della liberazione delle risorse umane per compiti più complessi. Con la crescente commoditizzazione dei Large Language Models (LLMs) e la standardizzazione dei componenti di soluzione, è prevedibile che tali soluzioni diventeranno presto onnipresenti.
Domande frequenti (FAQ)
- Il contenuto generato diventerà parte della memoria del LLM e influenzerà l’output futuro? Ad esempio, gli output errati generati da utenti meno esperti influenzeranno la qualità dell’output degli altri utenti?No. In questo approccio di soluzione, il LLM non ha “memoria” di ciò che genera, ogni richiesta parte da zero. A meno che il LLM non venga raffinato (ulteriormente addestrato) o l’output generato venga anche aggiunto alla base di conoscenza, gli output futuri non saranno influenzati.
- Il LLM sta imparando e migliorando con l’uso?Non automaticamente. Il modello di soluzione RAG non è un sistema di apprendimento per rinforzo. Tuttavia, la soluzione può essere progettata in modo che gli utenti possano fornire feedback sulla qualità dell’output, che può poi essere utilizzato per raffinare il modello. Aggiornamenti alla base di conoscenza o l’utilizzo di LLM aggiornati possono anche migliorare la qualità dell’output della soluzione.
- Le rappresentazioni vettoriali verranno salvate nel data warehouse di origine?In generale, no. Sebbene i vettori dei frammenti di documento possano tecnicamente essere memorizzati nel data warehouse di origine, lo scopo del data warehouse di origine e del vector db (o di un database SQL specificamente utilizzato per memorizzare i vettori per la soluzione) sono diversi. Aggiungere vettori al database di origine potrebbe creare dipendenze operative e costi aggiuntivi, che potrebbero non essere necessari né portare a vantaggi.
- Come verrà aggiornata la soluzione con nuovi dati?Il flusso di caricamento dei dati (individuazione dei documenti da caricare, elaborazione, frammentazione, vettorizzazione, caricamento nel vector db) dovrà essere eseguito sui nuovi dati man mano che diventano disponibili. Questo può essere un processo batch periodico. La frequenza degli aggiornamenti può essere adattata al caso d’uso.
- Come possiamo garantire che le informazioni sensibili nei documenti memorizzati nella base di conoscenza non siano accessibili al pubblico o ai fornitori di LLM?Le aziende possono utilizzare il servizio Azure OpenAI come soluzione single-tenant con un’istanza privata degli LLM di OpenAI. Ciò può garantire la privacy e la sicurezza dei dati. Un’altra soluzione è distribuire LLM di Hugging Face nell’infrastruttura privata dell’azienda in modo che nessun dato lasci il perimetro di sicurezza dell’azienda (a differenza dell’utilizzo di un LLM ospitato pubblicamente).
Risorse consigliate
Esplora queste risorse per approfondire la comprensione dei LLM e delle loro applicazioni:
- Generative AI Definito: Come funziona, vantaggi e pericoli (techrepublic.com)
- Cosa dovrebbero sapere i leader aziendali sull’utilizzo di LLM come ChatGPT (forbes.com)
Per una visione più approfondita del modello di soluzione RAG:
- Rispondere alle domande utilizzando la generazione con recupero con modelli di base in Amazon SageMaker JumpStart | AWS Machine Learning Blog
- Corso di Deeplearning.ai: Large Language Models con Semantic Search
- Corso di Deeplearning.ai: LangChain: Chatta con i tuoi dati






