Utilizzando i Pipelines di Scikit-Learn per Automatizzare l’Addestramento dei Modelli di Machine Learning e le Predizioni
Automatizzazione con Pipelines di Scikit-Learn per Modelli di Machine Learning e Predizioni
In questo articolo cercherò di spiegare la teoria e l’utilizzo della classe Scikit-Learn’s pipelines utilizzando un esempio di codifica di cross-validation e di taratura di iperparametri.
Le pipeline di Scikit-Learn vengono utilizzate per concatenare più operazioni nel ciclo di vita del machine learning (principalmente pre-elaborazione dei dati, creazione del modello e previsione sui dati di test). Ci aiutano riducendo molti codici manuali per la cross-validation e la taratura degli iperparametri.
Prima di approfondire le pipeline di Scikit-Learn, cerchiamo di capire prima i vantaggi nell’utilizzo di queste pipeline.
Comodità ed encapsulamento
Dopo aver incorporato le pipeline di Scikit-Learn nel tuo codice, devi solo chiamare i metodi fit e predict sui tuoi dati per adattare l’intero array di operazioni di pre-elaborazione e addestramento del modello. Inoltre, le pipeline di Scikit-Learn ci semplificano la vita facilitando l’esperimento con diversi algoritmi di apprendimento automatico.
- Da molti a pochi affrontare i dati ad alta dimensionalità con la riduzione della dimensionalità nell’apprendimento automatico
- Trovare il giusto equilibrio comprendere l’underfitting e l’overfitting nei modelli di apprendimento automatico
- Sii sicuro dei tuoi modelli di Machine Learning con l’aiuto della Cross-Validation
Selezione congiunta dei parametri
Puoi cercare in griglia su tutti i parametri degli stimatori nella pipeline contemporaneamente.
Sicurezza
Le pipeline di Scikit-Learn evitano la perdita di statistiche dai dati di test al modello addestrato nella cross-validation. Questo viene fatto facendo in modo che i dati utilizzati per l’addestramento dei trasformatori e dei predittori siano gli stessi.
Utilizzeremo il dataset Kaggle Spaceship Titanic per dimostrare l’utilizzo delle pipeline di Scikit-Learn. In questo articolo, inizierò dalla fase di pre-elaborazione del ciclo di vita del progetto di data science. Se vuoi vedere l’analisi esplorativa dei dati, dai un’occhiata al mio altro articolo.
Una guida pratica all’analisi esplorativa dei dati (EDA) utilizzando Python
In questo articolo spiegherò una delle parti più importanti del ciclo di vita di un progetto di data science, ovvero…
VoAGI.com
I dati per questo problema richiedono la seguente pre-elaborazione:
- imputazione dei valori mancanti
- codifica dei dati categorici
- ridimensionamento dei dati numerici
- rimozione degli outlier
- trasformazione log-normale (opzionale)
Scikit-Learn ha trasformatori incorporati per la maggior parte delle operazioni di pre-elaborazione di base come la codifica dei dati categorici, l’imputazione dei valori mancanti, il ridimensionamento e molto altro. Ma a volte, è necessario eseguire determinate operazioni sui dati per le quali non abbiamo un trasformatore Scikit-Learn incorporato. In questi casi, creiamo trasformatori personalizzati in base alle nostre esigenze.
Scikit-Learn non ha un trasformatore incorporato per la rimozione degli outlier e la trasformazione log-normale. Quindi, ne creeremo uno noi stessi. Poiché lo scopo di questo articolo è sapere come utilizzare le pipeline di Scikit-Learn, qui non spiegherò come creare un trasformatore personalizzato. Ma comunque, puoi dare un’occhiata al mio altro articolo che parla solo dei trasformatori personalizzati.
Un approccio semplice alla creazione di trasformatori personalizzati utilizzando le classi di Scikit-Learn
In questo articolo spiegherò come creare un trasformatore secondo le nostre esigenze di elaborazione utilizzando Scikit-Learn…
VoAGI.com
Creazione di un trasformatore personalizzato per la rimozione degli outlier
## creazione di un trasformatore personalizzato per gestire gli outlier dai dati from sklearn.base import BaseEstimator, TransformerMixinclass Outlier_Remover(BaseEstimator, TransformerMixin): def __init__(self,list_of_feature_names = num_feat): self.list_of_feature_names = list_of_feature_names def fit(self, X, y=None): return self def transform(self, X, y=None): quantiles = X[num_feat].quantile(np.arange(0,1,0.25)).T quantiles = quantiles.rename(columns={0.25:'Q1', 0.50: 'Q2', 0.75:'Q3'}) quantiles['IQR'] = quantiles['Q3'] - quantiles['Q1'] quantiles['Lower_Limit'] = quantiles['Q1'] - 1.5*quantiles['IQR'] quantiles['Upper_Limit'] = quantiles['Q3'] + 1.5*quantiles['IQR'] for feature in num_feat: X[feature] = np.where((X[feature] < quantiles.loc[feature,'Lower_Limit']) | (X[feature] > quantiles.loc[feature,'Upper_Limit']) & (X[feature] is not np.nan), X[feature].median(), X[feature]) return XQui, num_feat è una lista di nomi di caratteristiche numeriche nei dati.
Creazione di un trasformatore personalizzato per la distribuzione log-normale
## creazione di un trasformatore personalizzato che verrà utilizzato per eseguire la trasformazione logaritmica sui valori delle caratteristicheclass Log_Transformer(BaseEstimator, TransformerMixin): def __init__(self): pass def fit(self, X, y=None): return self def transform(self, X, y=None): for feature in num_feat: X[feature] = np.where(X[feature]==0,np.log(X[feature]+0.0002),np.log(X[feature])) return XCreazione di un flusso di lavoro per la preparazione delle caratteristiche numeriche
Scikit-Learn ha una classe Pipeline per creare un flusso di lavoro.
Il nostro flusso di lavoro numerico conterrà tre passaggi. Sono:
- Rimozione degli outlier utilizzando il trasformatore creato in precedenza
- Trasformatore per rimuovere i valori mancanti: qui utilizzeremo il trasformatore SimpleImputer di Scikit-Learn per eseguire questa operazione.
- Trasformatore per ridimensionare le caratteristiche numeriche: qui utilizzeremo il trasformatore StandardScaler di scikit-learn.
L’oggetto Pipeline di Scikit-Learn prende in input una lista di tuple. Ciascuna di queste tuple sarà dedicata a uno dei processi e avrà due argomenti per ciascun processo. Il primo argomento è il nome del passaggio e il secondo è l’oggetto trasformatore o stimatore.
Pipeline ([
(nome_processo1, oggetto_processo1),
(nome_processo2, oggetto_processo2),
e così via…
])
## creazione di un flusso di lavoro per la preparazione delle caratteristiche numeriche usando la classe Pipeline di sklearnfrom sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalernum_pipe = Pipeline(steps=[ ('rimozione_outlier',Outlier_Remover()), ('trasformazione_log',Log_Transformer()), ('sostituzione_valori_mancanti_num',SimpleImputer(strategy='median', missing_values=np.nan)), ('ridimensionamento',MinMaxScaler())]Come puoi vedere nel blocco di codice sopra, rimozione_outlier, sostituzione_valori_mancanti_num, trasformazione_log e ridimensionamento sono i nomi dei trasformatori. Accanto a ciascuno di questi nomi, viene menzionato il rispettivo oggetto trasformatore.
Creazione di un flusso di lavoro per la preparazione delle caratteristiche categoriche
Come nel caso delle caratteristiche numeriche, creeremo anche un flusso di lavoro per le caratteristiche categoriche. Le caratteristiche categoriche richiedono i seguenti passaggi nella preparazione:
- Rimozione delle caratteristiche inutili
- Sostituzione dei valori mancanti con il valore più frequente della caratteristica
- Codifica dei valori della caratteristica in interi
- Sostituzione dei valori mancanti con il valore più frequente della caratteristica
## creazione di un flusso di lavoro per la preparazione delle caratteristiche categoriche usando la classe Pipeline di sklearnfrom sklearn.preprocessing import OrdinalEncoderfrom sklearn.impute import SimpleImputercat_pipe = Pipeline(steps=[ ('rimozione_caratteristiche_inutili',Remove_Useless_Features()), ('sostituzione_valori_mancanti_cat', SimpleImputer(strategy='most_frequent', missing_values=np.nan)), ('codifica', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=np.nan)), ('sostituzione_valori_mancanti_cat2', SimpleImputer(strategy='most_frequent', missing_values=np.nan)) # questo passaggio serve per assicurarsi di riempire i valori mancanti creati nel passaggio di codifica])Qui, stiamo eseguendo nuovamente l’imputazione dei valori mancanti dopo la codifica dei valori delle caratteristiche. Questo perché il nostro codificatore è progettato in modo tale che codificherà qualsiasi nuova categoria che incontra come un valore nullo (questo caso potrebbe verificarsi nei dati di test se non nei dati di addestramento).
Unire i flussi di lavoro per la preparazione delle caratteristiche numeriche e categoriche
Nelle fasi precedenti, abbiamo creato flussi di lavoro per le caratteristiche numeriche e categoriche dei dati. Quindi, adesso combineremo quei due flussi di lavoro creati in precedenza per creare un unico flusso di lavoro in grado di preparare tutte le caratteristiche in una volta.
Scikit-Learn ha una classe integrata per questo. La classe ColumnTransformer di Scikit-Learn viene utilizzata per questo compito. Scikit-Learn ColumnTransformer prende in input la lista di tuple come argomento principale. Ciascuna tupla ha tre tipi di informazioni al loro interno. Il primo è il nome del processo, il secondo è l’oggetto necessario per quella operazione e il terzo è la lista dei nomi delle caratteristiche su cui è necessario eseguire questo processo.
## combinazione dei flussi di lavoro (numerico e categorico) utilizzando la classe ColumnTransformer di sklearnfrom sklearn.compose import ColumnTransformerpreprocess_pipe = ColumnTransformer([ ('preparazione_numerica',num_pipe, num_feat_rilevanti), ('preparazione_categorica', cat_pipe, cat_feat_rilevanti)], remainder='drop')Qui, cat_preprocessing e num_preprocessing sono i nomi di due processi. cat_pipe e num_pipe sono gli oggetti che abbiamo creato negli ultimi due passaggi. cat_feat e num_feat sono le liste dei nomi delle caratteristiche su cui cat_pipe e num_pipe verranno applicati.
ColumnTransformer ([
(nome_processo1, oggetto_processo1, nomi_caratteristiche1),
(nome_processo2, oggetto_processo2, nomi_caratteristiche2),
E così via…
])
Si noti che ColumnTransformer ha un secondo argomento chiamato remainder. Qui il valore ‘drop’ del remainder rimuoverà tutte le caratteristiche dei dati che non sono presenti nella lista num_feat o nella lista cat_feat. Qui, se utilizziamo il valore ‘pass’ per l’argomento remainder, allora in questo caso, tutte le caratteristiche che non sono nella lista num_feat o nella lista cat_feat vengono ignorate nel passaggio di preprocessing ma non vengono rimosse dai dati.
Ora che abbiamo creato l’intero flusso di preprocessing, creiamo alcuni modelli di machine learning.
Creazione di alcuni modelli di machine learning
## modello 1: Support Vector Regressionfrom sklearn.svm import SVRsvr = SVR()## modello 2: Nearest Neighbors Regressionfrom sklearn.neighbors import KNeighborsRegressorknr = KNeighborsRegressor()## modello 3: Decision Tree Regressionfrom sklearn.tree import DecisionTreeRegressordtr = DecisionTreeRegressor(max_depth=4,random_state=123)## modello 4: Random Forest Regressionfrom sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor()## modello 5: Xgboost Regressorfrom xgboost import XGBRegressorxgbr = XGBRegressor(seed=24324)## modello 6: AdaBoost Regressorfrom sklearn.ensemble import AdaBoostRegressorabr = AdaBoostRegressor(random_state=123)## modello 7: Gradient Boosting Regressorfrom sklearn.ensemble import GradientBoostingRegressorgbr = GradientBoostingRegressor()## modello 8: voting regressor del modello 1, modello 2 e modello 4from sklearn.ensemble import VotingRegressorvr = VotingRegressor(estimators = [('svr', svr), ('knr', knr), ('rfr', rfr)])## modello 9: light gbm regressorfrom lightgbm import LGBMRegressorlgbmr = LGBMRegressor()## modello 10: catboost regressorfrom catboost import CatBoostRegressorcbr = CatBoostRegressor(verbose=False)Ora abbiamo i nostri modelli con noi. Il passo successivo sarà combinare l’intero flusso di preprocessing con ciascuno dei modelli di machine learning creati in precedenza. Per combinare il flusso di preprocessing e i modelli, useremo nuovamente la classe Scikit-Learn Pipeline.
## pipeline del support vector regressorsvr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('svr_model',svr)])## pipeline del nearest neighbors regressorknr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('knr_model',knr)])## pipeline del decision tree regressordtr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('dtr_model',dtr)])## pipeline del random forest regressorrfr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('rfr_model',rfr)])## pipeline del xgboost regressorxgbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('xgbr_model',xgbr)])## pipeline del adaboost regressorabr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('abr_model', abr)])## pipeline del gradient boosting regressorgbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('gbr_model', gbr)])## pipeline del voting regressor del modello 1, modello 2 e modello 4vr_pipe = Pipeline(steps=[ ('preprocess_pipe', preprocess_pipe), ('vr_model', vr)])## pipeline del light gbm regressorlgbmr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('lgbmr_model',lgbmr)])## pipeline del catboost regressorcbr_pipe = Pipeline(steps=[ ('preprocess_pipe',preprocess_pipe), ('cbr_model',cbr)])Questo conclude la creazione delle pipeline. Le pipeline che abbiamo creato nei blocchi di codice precedenti sono ora in grado di eseguire il preprocessing e la costruzione del modello con una singola chiamata al metodo fit. Per saperne di più sull’uso corretto dei metodi fit e fit_transform, consulta il mio altro articolo:
Differenza tra i metodi fit, transform, fit_transform e predict di scikit-learn e quando usarli…
Questo articolo ti insegnerà la differenza fondamentale tra i metodi fit e fit_transform di scikit-learn e quando usarli…
VoAGI.com
Inoltre, possiamo utilizzare queste pipeline anche per la cross-validazione e l’ottimizzazione degli iperparametri. Vediamo anche degli esempi.
Eseguire una cross-validazione sui dati utilizzando le pipeline
## Trovare il miglior modello utilizzando la cross-validazione from sklearn.model_selection import KFoldfrom sklearn.model_selection import cross_val_scorepipelines = [svr_pipe, knr_pipe, dtr_pipe, rfr_pipe, xgbr_pipe, abr_pipe, gbr_pipe, vr_pipe, lgbmr_pipe, cbr_pipe]models = ['SupportVectorRegressor', 'KneighborsRegressor', 'DecisionTreeRegressor', 'RandomForestRegressor', 'XgboostRegressor', 'AdaboostRegressor', 'GradientBoostRegressor', 'VotingRegressor', 'LGBMRegressor', 'CatBoostRegressor']cv = KFold(n_splits=10)for index, pipeline in enumerate(pipelines): mean = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').mean(),3) std = np.round(cross_val_score(estimator=pipeline, X=X, y=y,cv=cv,scoring='r2').std(),3) print(f"Il punteggio di cross-validazione per il modello {models[index]} è {mean} +/- {std}.")
Si noti che qui abbiamo utilizzato le pipeline come un estimatore finale nel metodo cross_val_score. Poiché abbiamo incorporato la preelaborazione e la creazione del modello nella nostra pipeline finale, non dobbiamo eseguire alcuna elaborazione noi stessi.
Ora, vediamo un esempio di ottimizzazione degli iperparametri utilizzando le pipeline di Scikit-Learn per gli algoritmi che restituiscono il punteggio r2 più alto.
Eseguire l’ottimizzazione degli iperparametri utilizzando le pipeline di Scikit-Learn
Creiamo un dizionario di iperparametri per ciascuno dei modelli di apprendimento automatico creati in precedenza.
Qui, eseguiremo l’ottimizzazione degli iperparametri solo sui modelli di apprendimento automatico ad alte prestazioni in base alla cross-validazione.
## iperparametri da testare per il regressore random forestrfr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3), 'bootstrap': [True, False]}## iperparametri da testare per il regressore gradient boostgbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(3,10,1), 'max_features': np.arange(9,28,3)}## iperparametri da testare per il regressore xgboostxgbr_params = { 'n_estimators': np.arange(100,600,100), 'max_depth': np.arange(2,10,1), 'learning_rate': np.arange(0.1,1.1,0.1)}## iperparametri da testare per LGBMRegressorlgbmr_params = { 'boosting_type': ['gbdt', 'dart'], 'num_leaves': [2,3,4], 'max_depth': np.arange(3,10,1), 'learning_rate': np.arange(0.1,1.1,0.1), 'n_estimators': np.arange(100,600,100)}## iperparametri da testare per il regressore catboostcbr_params = { 'learning_rate': np.arange(0.1,1.1,0.1), 'max_depth': np.arange(3,10,1), 'n_estimators': np.arange(100,600,100)}Ora, eseguiamo l’ottimizzazione degli iperparametri.
from sklearn.model_selection import RandomizedSearchCVtune_models = [rfr, xgbr, gbr, lgbmr, cbr]tune_model_names = ['Random Forest Regressor', 'XGBoost Regressor', 'Gradient Boost Regressor', 'LGBM Regressor', 'Catboost Regressor']tuning_params = [rfr_params, xgbr_params, gbr_params, lgbmr_params, cbr_params]for index, model in enumerate(tune_models): grid = RandomizedSearchCV(model, tuning_params[index], cv=5, scoring='r2',random_state=2434) grid.fit(preprocess_pipe.fit_transform(X),y) print(f"Il punteggio migliore per il modello {tune_model_names[index]} dopo l'ottimizzazione degli iperparametri è {grid.best_score_}.") print(f"I parametri che danno questo miglior punteggio sono {grid.best_params_}.\n")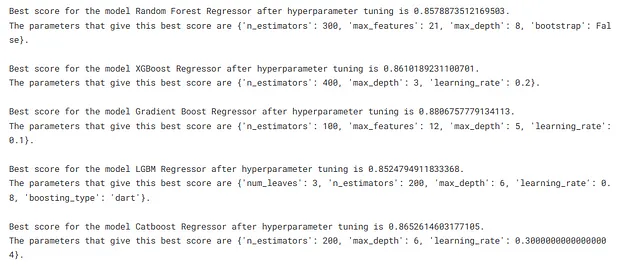
Abbiamo ottenuto il parametro che fornisce alte prestazioni per il nostro modello. Ora impostiamo quei parametri per il nostro modello e addestriamo le pipeline.
rfr.set_params(bootstrap=False,max_depth=8,max_features=21,n_estimators=300,random_state=234)xgbr.set_params(learning_rate=0.2, max_depth=3, n_estimators=400)gbr.set_params(n_estimators=100, max_features=12, max_depth=5, learning_rate=0.1, random_state=23432)lgbmr.set_params(boosting_type='dart', learning_rate=0.8, max_depth=6, n_estimators=200, num_leaves=3, random_state=3423)cbr.set_params(learning_rate=0.3, max_depth=6, n_estimators=200, random_seed=2344)Addestramento e salvataggio delle pipeline
Addestreremo i dati su tutte le pipeline create sopra e salveremo ognuna di esse. Per l’addestramento, sarà sufficiente fornire il nome della pipeline e i dati, tutte le fasi incluse nell’elaborazione e nell’addestramento verranno eseguite automaticamente grazie alle pipeline.
import os, picklefor index,pipeline in enumerate(pipelines): model = pipeline.fit(X,y) with open(os.path.join('main_dir',str(models[index])+'.pkl'), 'wb') as f: pickle.dump(model,f)Ora l’ultimo passaggio è semplicemente caricare i nuovi dati e effettuare una previsione utilizzando la pipeline addestrata ad alte prestazioni.
Le pipeline di Scikit-Learn sono molto utili per trovare il modello con le migliori prestazioni, consentendoci di sperimentare contemporaneamente diversi algoritmi di apprendimento automatico. Inoltre, come avete visto sopra, diventa molto facile eseguire la cross-validazione e l’ottimizzazione degli iperparametri su molti modelli di apprendimento automatico contemporaneamente. In sostanza, queste pipeline rendono la nostra vita molto più comoda, risparmiandoci un sacco di tempo necessario per sperimentare con molti algoritmi uno per uno.
Spero che abbiate acquisito una base di conoscenze sulle pipeline di Scikit-Learn e sul loro utilizzo. Il codice in questo articolo è tratto dal mio profilo Kaggle. Date un’occhiata all’intero codice:
Predizione dei prezzi delle case – pipeline di Scikit-Learn
Esplora ed esegui codice di apprendimento automatico con i quaderni Kaggle | Utilizzando i dati di House Prices – Advanced Regression…
www.kaggle.com
Risorse utili
Documentazione di Scikit-Learn
Libro intitolato “Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow”
(2025) scikit-learn tips — YouTube
Conclusione
Spero che vi sia piaciuto questo articolo. Seguitemi su VoAGI per leggere altri articoli simili.
Connettiti con me su
Sito web
Scrivimi a [email protected]




