Come aggiungere conoscenze specifiche di dominio a un LLM basato sui tuoi dati
Aggiungi conoscenze specifiche del dominio al tuo LLM basato sui dati.
Trasforma il tuo LLM in un esperto del settore
Introduzione
Negli ultimi mesi, i Large Language Models (LLMs) hanno profondamente cambiato il modo in cui lavoriamo e interagiamo con la tecnologia, dimostrando di essere strumenti utili in vari settori, come assistenti di scrittura, generatori di codice e persino collaboratori creativi. La loro capacità di comprendere il contesto, generare testo simile a quello umano e svolgere una vasta gamma di compiti legati al linguaggio li ha portati in primo piano nella ricerca sull’intelligenza artificiale.
Anche se i LLM eccellono nella generazione di testo generico, spesso faticano quando si confrontano con settori altamente specializzati che richiedono conoscenze precise e una comprensione sfumata. Quando vengono utilizzati per compiti specifici di un determinato settore, questi modelli possono presentare limitazioni o, in alcuni casi, persino produrre risposte errate o allucinatorie. Ciò sottolinea la necessità di incorporare conoscenze di dominio nei LLM, consentendo loro di navigare meglio il gergo complesso e specifico dell’industria, mostrare una comprensione più sfumata del contesto e limitare il rischio di produrre informazioni false.
In questo articolo, esploreremo una delle diverse strategie e tecniche per infondere conoscenze di dominio nei LLM, consentendo loro di dare il massimo all’interno di contesti professionali specifici, aggiungendo frammenti di documentazione in un LLM come contesto quando si inietta la query.
Questo metodo funziona con qualsiasi tipo di documentazione e utilizza solo tecnologie sicure e open source che verranno eseguite localmente sul tuo computer, senza la necessità di accedere a Internet. Grazie a questo, ho potuto utilizzarlo su dati personali e riservati a cui non volevo che siti web di terze parti accedessero.
- Previsioni locali vs globali ciò che devi sapere
- Attaccare i modelli di linguaggio di grandi dimensioni LLMOps e sicurezza
- 3 Domande Perfezionare la percezione e la mappatura dei robot
Principio
Ecco una panoramica di come funziona:
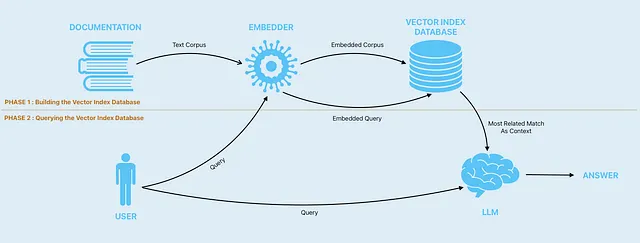
Il primo passo consiste nel prendere la nostra documentazione e costruire un database di indici vettoriali basato sulla nostra documentazione. I database vettoriali sono un tipo di database progettato per memorizzare e interrogare vettori ad alta dimensione in modo efficiente. Questi database consentono una rapida ricerca di similarità semantica, consentendo agli utenti di trovare vettori che…






