Acme Un nuovo framework per il reinforcement learning distribuito
'Acme un framework per il reinforcement learning distribuito'
Nel complesso, gli obiettivi di alto livello di Acme sono i seguenti:
- Consentire la riproducibilità dei nostri metodi e risultati – questo aiuterà a chiarire cosa rende un problema di RL difficile o facile, qualcosa che raramente è evidente.
- Semplificare il modo in cui progettiamo nuovi algoritmi (noi e la comunità in generale) – vogliamo che il prossimo agente di RL sia più facile da scrivere per tutti!
- Migliorare la leggibilità degli agenti di RL – non ci dovrebbero essere sorprese nascoste quando si passa da un articolo a un codice.
Per raggiungere questi obiettivi, il design di Acme colma anche il divario tra esperimenti su larga scala, VoAGI e su piccola scala. Lo abbiamo fatto pensando attentamente al design degli agenti a molti livelli diversi.
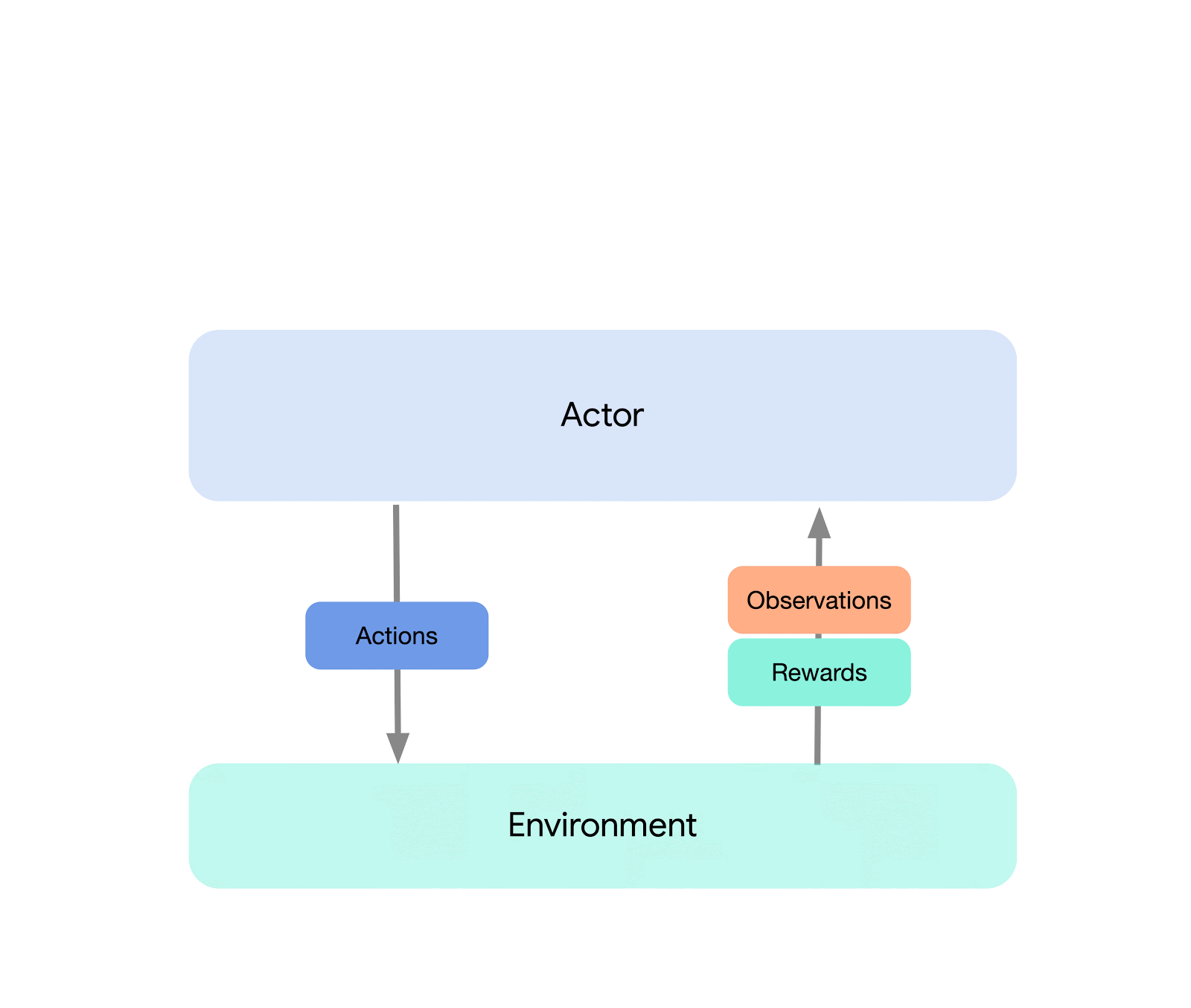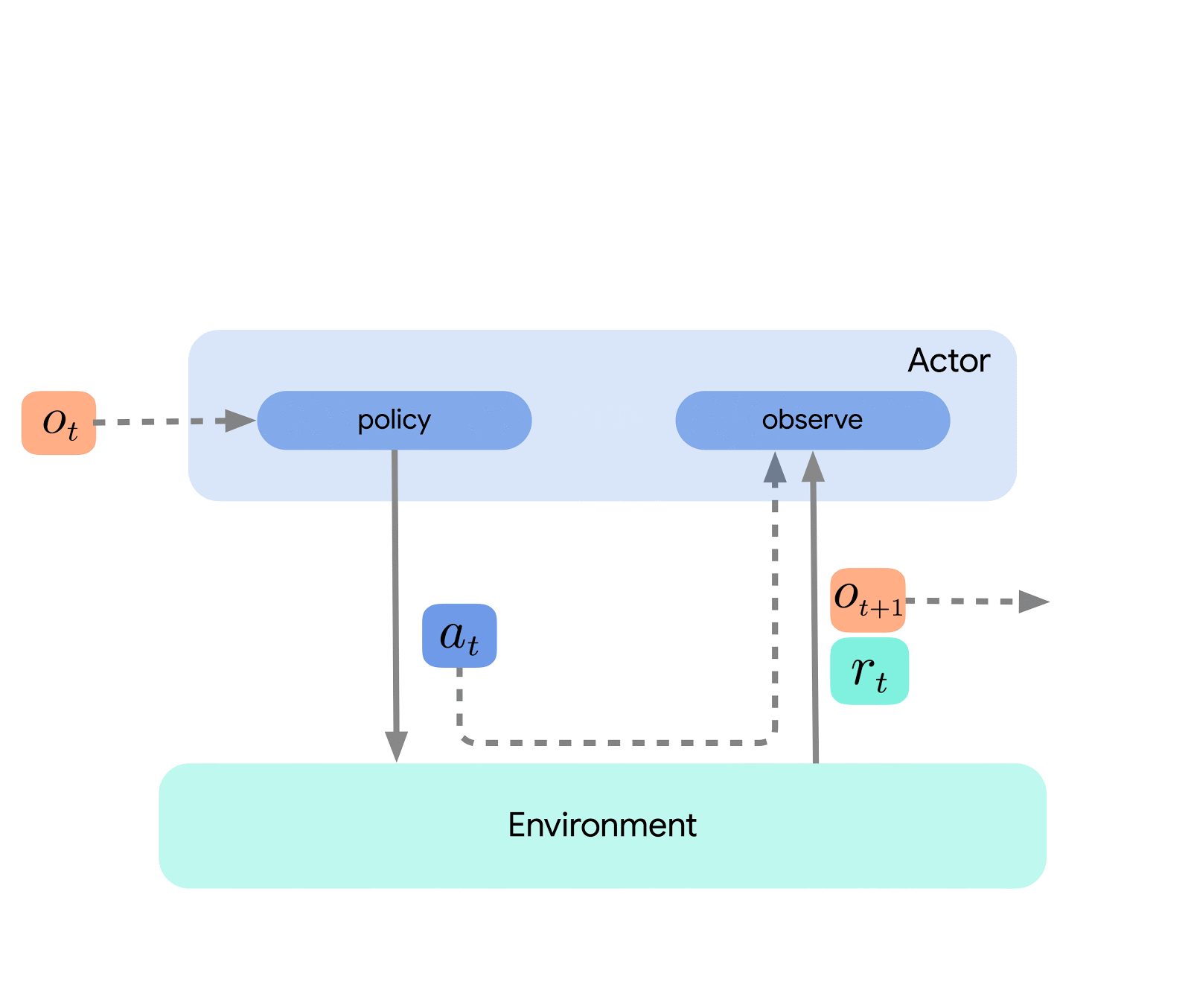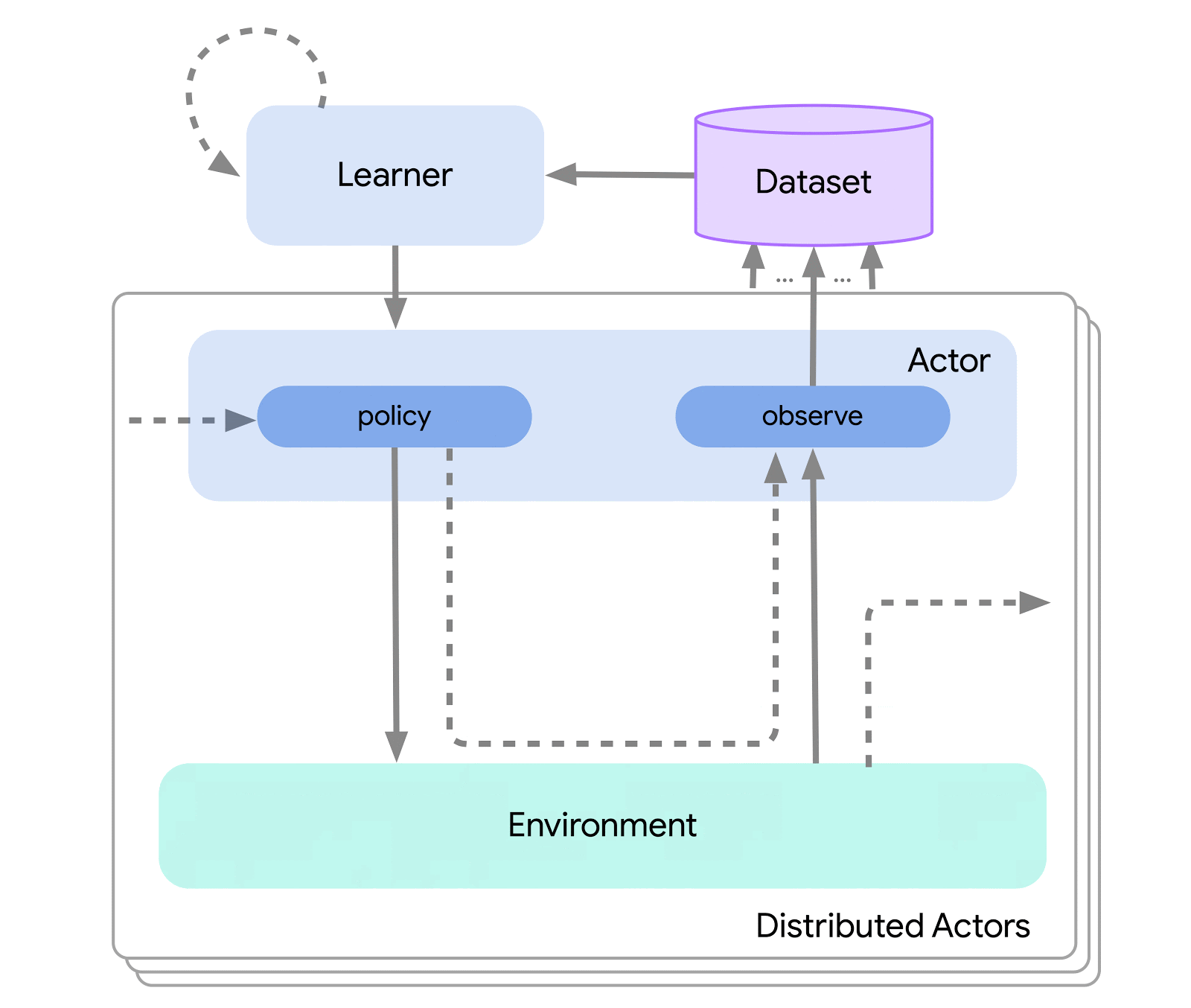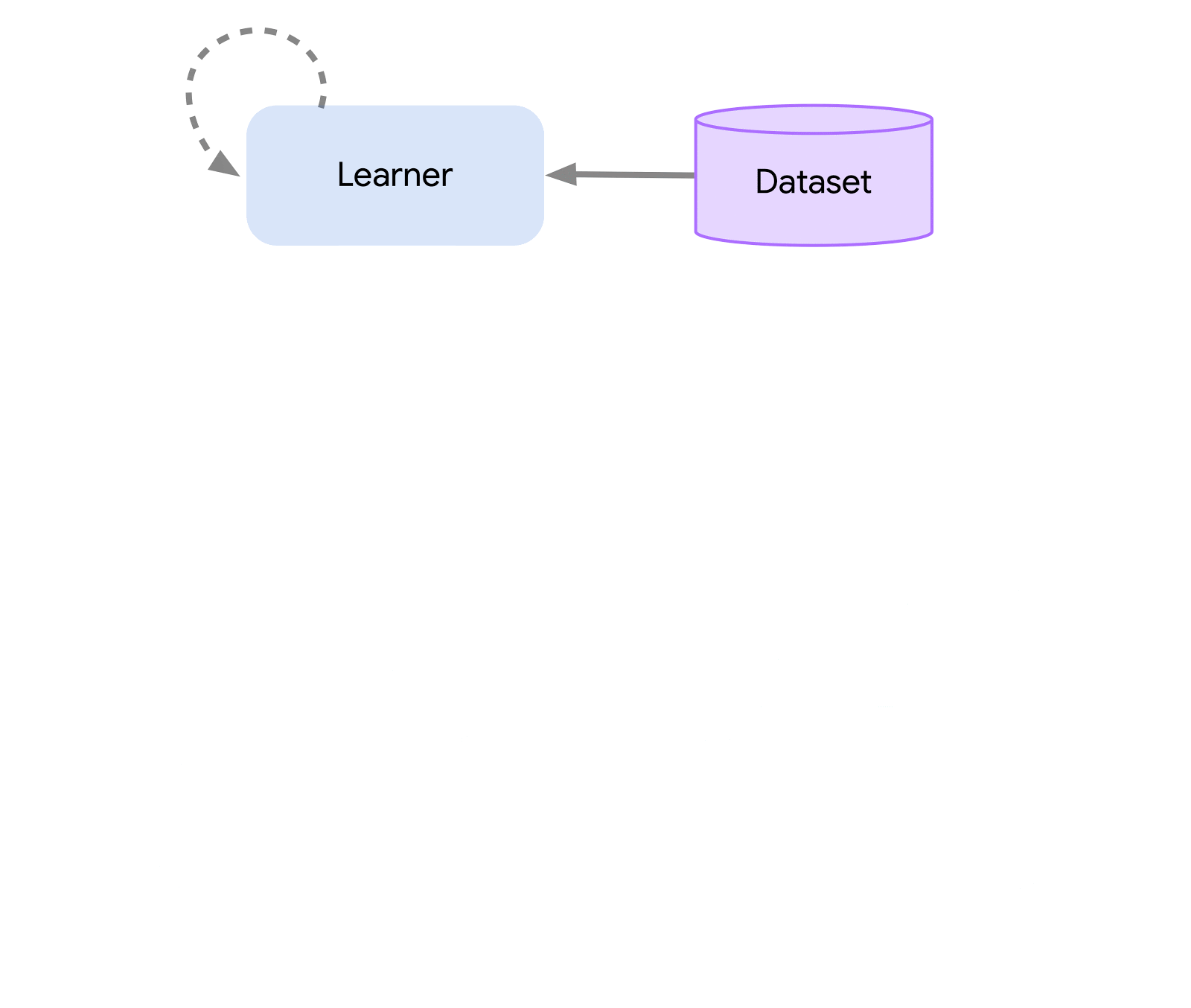
Al livello più alto, possiamo pensare ad Acme come a un’interfaccia di RL classica (trovata in qualsiasi testo introduttivo di RL) che collega un attore (cioè un agente selezionatore di azioni) a un ambiente. Questo attore è una semplice interfaccia che ha metodi per selezionare azioni, fare osservazioni e aggiornarsi. Internamente, gli agenti di apprendimento suddividono ulteriormente il problema in un componente di “agire” e un componente di “apprendimento dai dati”. Superficialmente, ciò ci consente di riutilizzare le porzioni di agire in molti agenti diversi. Tuttavia, ancora più importante, questo fornisce un confine cruciale su cui dividere e parallelizzare il processo di apprendimento. Possiamo persino ridimensionare da qui e attaccare senza problemi l’ambiente di RL batch in cui non esiste alcun ambiente e solo un dataset fisso. Le illustrazioni di questi diversi livelli di complessità sono mostrate di seguito:
- dm_control Software e Compiti per il Controllo Continuo
- Candidatura per ruoli tecnici
- RL Non Collegato Benchmark per l’Apprendimento Rinforzato Offline
Questo design ci consente di creare, testare e debuggare facilmente nuovi agenti in scenari su piccola scala prima di ridimensionarli, il tutto utilizzando lo stesso codice di attuazione e apprendimento. Acme fornisce anche una serie di utility utili, dal checkpointing allo snapshotting, agli aiutanti computazionali a basso livello. Questi strumenti sono spesso gli eroi non riconosciuti di qualsiasi algoritmo di RL, e in Acme cerchiamo di mantenerli semplici e comprensibili.
Per consentire questo design, Acme fa anche uso di Reverb: un nuovo sistema di archiviazione dati efficiente appositamente costruito per i dati di apprendimento automatico (e di apprendimento per rinforzo). Reverb è principalmente utilizzato come sistema per il replay di esperienze negli algoritmi di apprendimento per rinforzo distribuito, ma supporta anche altre rappresentazioni di strutture dati come code FIFO e code di priorità. Ciò ci consente di usarlo senza soluzione di continuità per algoritmi on-policy e off-policy. Acme e Reverb sono stati progettati fin dall’inizio per interagire in modo ottimale, ma Reverb può anche essere utilizzato autonomamente, quindi controllalo!
Oltre alla nostra infrastruttura, stiamo anche rilasciando istanziamenti a singolo processo di diversi agenti che abbiamo costruito utilizzando Acme. Questi coprono un’ampia gamma di controllo continuo (D4PG, MPO, ecc.), apprendimento Q discreto (DQN e R2D2) e altro ancora. Con un numero minimo di modifiche – suddividendo il confine tra attuazione e apprendimento – possiamo eseguire questi stessi agenti in modo distribuito. Il nostro primo rilascio si concentra sugli agenti a singolo processo, poiché sono quelli principalmente utilizzati dagli studenti e dai ricercatori.
Abbiamo anche effettuato un attento benchmarking di questi agenti su diversi ambienti, ovvero il control suite, Atari e bsuite.
Playlist di video che mostrano agenti addestrati utilizzando il framework Acme
Anche se risultati aggiuntivi sono facilmente disponibili nel nostro articolo, mostriamo alcuni grafici che confrontano le prestazioni di un singolo agente (D4PG) misurate sia in termini di passi di attore che di tempo trascorso per un compito di controllo continuo. Grazie al modo in cui limitiamo il tasso di inserimento dei dati nel replay – consulta l’articolo per una discussione più approfondita – possiamo vedere approssimativamente le stesse prestazioni confrontando le ricompense che un agente riceve rispetto al numero di interazioni che ha avuto con l’ambiente (passi dell’attore). Tuttavia, all’aumentare della parallelizzazione dell’agente, vediamo dei guadagni in termini di velocità di apprendimento dell’agente. In domini relativamente piccoli, in cui le osservazioni sono limitate a spazi di feature piccoli, anche un modesto aumento di questa parallelizzazione (4 attori) porta a un agente che impiega meno della metà del tempo per apprendere una politica ottimale:

Ma per domini ancora più complessi in cui le osservazioni sono immagini che sono relativamente costose da generare, vediamo guadagni molto più estesi:

E i guadagni possono essere ancora più grandi per domini come i giochi Atari, dove i dati sono più costosi da raccogliere e i processi di apprendimento richiedono generalmente più tempo. Tuttavia, è importante notare che questi risultati condividono lo stesso codice di agire e apprendere tra l’ambiente distribuito e non distribuito. Quindi è perfettamente fattibile sperimentare con questi agenti e risultati su una scala più piccola – infatti, è qualcosa che facciamo tutto il tempo durante lo sviluppo di agenti innovativi!
Per una descrizione più dettagliata di questa progettazione, insieme ad ulteriori risultati per i nostri agenti di base, consulta il nostro articolo. O, ancora meglio, dai un’occhiata al nostro repository GitHub per vedere come puoi iniziare a utilizzare Acme per semplificare i tuoi agenti!






