Ricercatori dell’Università di Wisconsin-Madison propongono Eventful Transformers un approccio economico al riconoscimento video con una perdita minima di accuratezza.
Ricercatori dell'Università di Wisconsin-Madison propongono Eventful Transformers per il riconoscimento video con perdita minima di accuratezza.


I transformer originariamente pensati per la modellazione del linguaggio sono stati recentemente investigati come possibile architettura per compiti legati alla visione. Con prestazioni all’avanguardia in applicazioni che includono l’identificazione degli oggetti, la classificazione delle immagini e la classificazione dei video, i Vision Transformer hanno dimostrato un’eccellente precisione in una varietà di problemi di riconoscimento visivo. Il costo elevato di elaborazione dei Vision Transformer è uno dei loro principali svantaggi. A volte, i Vision Transformer richiedono un’elaborazione di ordini di grandezza superiore rispetto alle reti convoluzionali standard (CNN), fino a centinaia di GFlops per immagine. La grande quantità di dati coinvolti nell’elaborazione dei video aumenta ulteriormente queste spese. Il potenziale di questa tecnologia altrimenti interessante è ostacolato dai requisiti elevati di elaborazione che impediscono l’utilizzo dei Vision Transformer su dispositivi con poche risorse o che richiedono una bassa latenza.
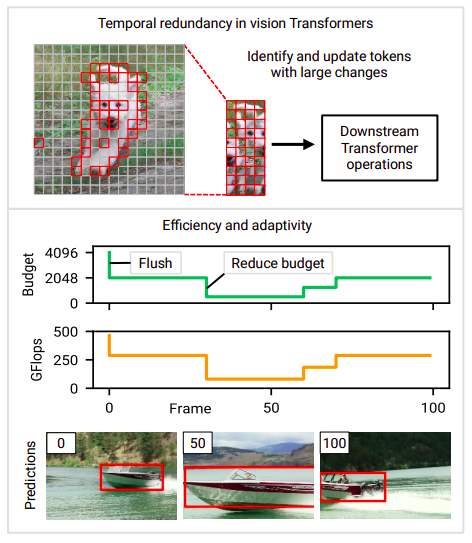
Una delle prime tecniche per sfruttare la ridondanza temporale tra gli input successivi al fine di ridurre il costo dei Vision Transformer quando utilizzati con dati video è presentata in questo lavoro da ricercatori dell’Università del Wisconsin-Madison. Immaginiamo un Vision Transformer che viene applicato a una sequenza video frame per frame o clip per clip. Questo Transformer potrebbe essere un modello semplice frame-wise (come un rilevatore di oggetti) o una fase di transizione in un modello spaziotemporale (come il modello fattorizzato iniziale). Vedono i Transformer come applicati a diversi input (frame o clip) nel tempo, a differenza dell’elaborazione del linguaggio, in cui un input Transformer rappresenta una sequenza completa. I film naturali presentano un elevato grado di ridondanza temporale e poche variazioni tra i frame. Nonostante questo, le reti profonde, come i Transformer, vengono frequentemente calcolate “da zero” su ciascun frame.
Questo metodo è inefficiente poiché scarta eventuali dati potenzialmente utili dalle conclusioni precedenti. La loro principale intuizione è che possono fare un uso migliore delle sequenze ridondanti riciclando i calcoli intermedi dai passaggi temporali precedenti. Inferenza intelligente. Il costo inferenziale per i Vision Transformer (e le reti profonde in generale) è spesso determinato dal design. Tuttavia, le risorse disponibili potrebbero cambiare nel tempo nelle applicazioni del mondo reale (ad esempio, a causa di processi concorrenti o cambiamenti nell’alimentazione elettrica). Di conseguenza, sono necessari modelli che consentano una modifica in tempo reale del costo computazionale. L’adattabilità è uno degli obiettivi principali di progettazione in questo studio e l’approccio è creato per fornire un controllo in tempo reale sul costo di calcolo. Per un’illustrazione di come cambiano il budget calcolato durante un film, vedere Figura 1 (sezione inferiore).
- Guida per principianti al fine-tuning di LLM
- Guida a LLM, Parte 1 BERT
- Le LLM sostituiranno i Knowledge Graph? I ricercatori di Meta propongono ‘Head-to-Tail’ un nuovo benchmark per misurare la conoscenza fattuale dei Large Language Models
Studi precedenti hanno esaminato la ridondanza temporale e l’adattabilità delle CNN. Tuttavia, a causa delle significative differenze architettoniche tra i Transformer e le CNN, questi approcci sono generalmente incompatibili con la visione dei Transformer. I Transformer, in particolare, introducono una nuova primitiva, l’autoattenzione, che si discosta da diverse metodologie basate sulle CNN. Nonostante questo ostacolo, i Vision Transformer offrono una grande possibilità. È difficile trasferire i vantaggi di sparsità nelle CNN, in particolare la sparsità acquisita tenendo conto della ridondanza temporale, in accelerazioni tangibili. Per fare ciò, è necessario imporre vincoli elevati sulla struttura di sparsità o utilizzare kernel di calcolo speciali. Al contrario, è più semplice trasferire la sparsità in tempi di esecuzione più brevi utilizzando operatori convenzionali a causa della natura delle operazioni dei Transformer, che si basano sulla manipolazione di vettori di token. Transformer con eventi.
Al fine di facilitare un’elaborazione adattiva ed efficace, propongono gli Eventful Transformer, un nuovo tipo di Transformer che sfrutta la ridondanza temporale tra gli input. La parola “Eventful” è stata coniata per descrivere i sensori chiamati fotocamere eventi, che creano output sparsi in risposta ai cambiamenti della scena. Gli Eventful Transformer aggiornano selettivamente le rappresentazioni dei token e le mappe di autoattenzione ad ogni passo temporale al fine di tracciare le modifiche a livello di token nel tempo. I moduli di gating sono blocchi in un Eventful Transformer che consentono il controllo in tempo reale della quantità di token aggiornati. Il loro approccio funziona con una varietà di applicazioni di elaborazione video e può essere utilizzato con modelli pre-costruiti (spesso senza ritraining). Le loro ricerche mostrano che gli Eventful Transformer, creati a partire dai modelli all’avanguardia attuali, riducono notevolmente i costi di calcolo pur mantenendo in gran parte la precisione del modello originale.
Il loro codice sorgente, che contiene moduli PyTorch per creare Eventful Transformers, è reso disponibile al pubblico. Limitazioni La pagina del progetto di Wisionlab si trova su wisionlab.com/project/eventful-transformers. Sulla CPU e sulla GPU, mostrano miglioramenti nel tempo di parete. Il loro approccio, basato su operatori standard di PyTorch, forse non è il migliore dal punto di vista tecnico. Sono certi che i rapporti di miglioramento delle prestazioni potrebbero essere ulteriormente aumentati con ulteriori lavori per ridurre gli oneri (come la costruzione di un kernel CUDA fuso per la loro logica di gating). Inoltre, il loro approccio comporta certi inevitabili oneri di memoria. Non sorprende il fatto che mantenere certi tensori in memoria sia necessario per riutilizzare i calcoli dai passaggi temporali precedenti.
Controlla il Paper. Tutto il merito di questa ricerca va ai ricercatori di questo progetto. Inoltre, non dimenticare di unirti alla nostra subreddit di ML con oltre 29k membri, alla community di Facebook con oltre 40k membri, al canale Discord e alla newsletter via email, dove condividiamo le ultime notizie sulla ricerca di intelligenza artificiale, progetti interessanti di intelligenza artificiale e altro ancora.
Se ti piace il nostro lavoro, amerai la nostra newsletter.
L’articolo Ricercatori dell’Università di Wisconsin–Madison propongono Eventful Transformers: un approccio conveniente al riconoscimento video con una perdita minima di precisione è apparso per primo su MarkTechPost.