Addestra il tuo primo agente RL basato su Deep Q Learning Una guida passo-passo
Guida all'addestramento del primo agente RL con Deep Q Learning
Introduzione:
Il Reinforcement Learning (RL) è un campo affascinante dell’Intelligenza Artificiale (AI) che permette alle macchine di apprendere e prendere decisioni attraverso l’interazione con il loro ambiente. Addestrare un agente RL comporta un processo di tentativi ed errori in cui l’agente impara dalle sue azioni e dai successivi premi o penalità che riceve. In questo blog, esploreremo i passaggi coinvolti nell’addestramento del tuo primo agente RL, insieme a frammenti di codice per illustrare il processo.
Passo 1: Definire l’Ambiente
Il primo passo nell’addestramento di un agente RL è definire l’ambiente in cui opererà. L’ambiente può essere una simulazione o uno scenario del mondo reale. Fornisce all’agente osservazioni e premi, consentendo di imparare e prendere decisioni. OpenAI Gym è una popolare libreria Python che fornisce una vasta gamma di ambienti predefiniti. Consideriamo l’ambiente classico “CartPole” per questo esempio.
import gymenv = gym.make('CartPole-v1')Passo 2: Comprendere l’Interazione Agente-Ambiente
Nel RL, l’agente interagisce con l’ambiente prendendo azioni basate sulle sue osservazioni. Riceve un feedback sotto forma di premi o penalità, che vengono utilizzati per guidare il processo di apprendimento. L’obiettivo dell’agente è massimizzare i premi cumulativi nel tempo. Per fare ciò, l’agente apprende una policy, ovvero una mappatura dalle osservazioni alle azioni, che lo aiuta a prendere le migliori decisioni.
Passo 3: Scegliere un Algoritmo RL
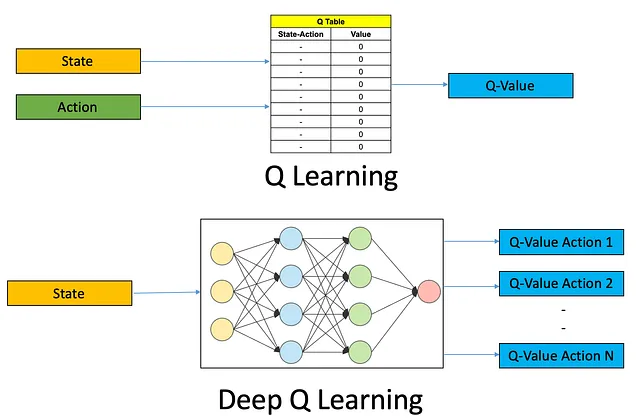
Sono disponibili vari algoritmi RL, ognuno con i propri punti di forza e debolezze. Un algoritmo popolare è il Q-Learning, adatto per spazi di azione discreti. Un altro algoritmo comunemente utilizzato è Deep Q-Networks (DQN), che utilizza reti neurali profonde per gestire ambienti complessi. Per questo esempio, utilizziamo l’algoritmo DQN.
- Introduzione alle statistiche utilizzando il linguaggio di programmazione R
- I migliori progetti di intelligenza artificiale generativa
- I ricercatori di Alibaba presentano la serie Qwen-VL un insieme di modelli visione-linguaggio su larga scala progettati per percepire e comprendere sia il testo che le immagini.

Passo 4: Costruire l’Agente RL
Per costruire un agente RL utilizzando l’algoritmo DQN, dobbiamo definire una rete neurale come approssimatore di funzione. La rete prende in input le osservazioni e restituisce i valori Q per ogni possibile azione. Dobbiamo anche implementare una memoria di riproduzione per memorizzare e campionare esperienze per l’addestramento.
import torchimport torch.nn as nnimport torch.optim as optimclass DQN(nn.Module): def __init__(self, input_dim, output_dim): super(DQN, self).__init__() self.fc1 = nn.Linear(input_dim, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, output_dim) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x# Creare un'istanza dell'agente DQNinput_dim = env.observation_space.shape[0]output_dim = env.action_space.nagent = DQN(input_dim, output_dim) Passo 5: Addestrare l’Agente RL
Ora possiamo addestrare l’agente RL utilizzando l’algoritmo DQN. L’agente interagisce con l’ambiente, osserva lo stato attuale, seleziona un’azione in base alla sua policy, riceve un premio e aggiorna di conseguenza i suoi valori Q. Questo processo viene ripetuto per un numero specificato di episodi o fino a quando l’agente raggiunge un livello di prestazioni soddisfacente.
optimizer = optim.Adam(agent.parameters(), lr=0.001)def train_agent(agent, env, episodes): for episode in range(episodes): state = env.reset() done = False episode_reward = 0 while not done: action = agent.select_action(state) next_state, reward, done, _ = env.step(action) agent.store_experience(state, action, reward, next_state, done) agent
Conclusione:
In questo blog, abbiamo esplorato il processo di addestramento del tuo primo agente di RL (Reinforcement Learning). Abbiamo iniziato definendo l’ambiente utilizzando OpenAI Gym, che fornisce una serie di ambienti predefiniti per compiti di RL. Abbiamo poi discusso dell’interazione agente-ambiente e dell’obiettivo dell’agente di massimizzare le ricompense cumulative.
Successivamente, abbiamo scelto l’algoritmo DQN come nostro algoritmo di RL preferito, che combina reti neurali profonde con Q-learning per gestire ambienti complessi. Abbiamo costruito un agente di RL utilizzando una rete neurale come approssimatore di funzione e implementato una memoria di replay per archiviare e campionare esperienze per l’addestramento.
Infine, abbiamo addestrato l’agente di RL facendolo interagire con l’ambiente, osservare gli stati, selezionare azioni in base alla sua politica, ricevere ricompense e aggiornare i suoi Q-values. Questo processo è stato ripetuto per un numero specificato di episodi, consentendo all’agente di imparare e migliorare le sue capacità decisionali.
L’apprendimento per rinforzo apre un mondo di possibilità per addestrare agenti intelligenti che possono imparare autonomamente e prendere decisioni in ambienti dinamici. Seguendo i passaggi descritti in questo blog, puoi intraprendere il tuo viaggio di addestramento di agenti RL ed esplorare vari algoritmi, ambienti e applicazioni.
Ricorda, l’addestramento RL richiede sperimentazione, ottimizzazione e pazienza. Man mano che ti immergi sempre più nel RL, puoi esplorare tecniche avanzate come il deep RL, i gradienti di politica e i sistemi multi-agenti. Quindi, continua ad imparare, iterare e spingere i limiti di ciò che i tuoi agenti RL possono raggiungere.
Happy training!
LinkedIn: https://www.linkedin.com/in/smit-kumbhani-44b07615a/
Il mio Google Scholar: https://scholar.google.com/citations?hl=en&user=5KPzARoAAAAJ
Blog su “Segmentazione semantica per la rilevazione e segmentazione del pneumotorace” https://medium.com/becoming-human/semantic-segmentation-for-pneumothorax-detection-segmentation-9b93629ba5fa