Cosa c’è di nuovo nei diffusori? 🎨
Quali sono le novità nei diffusori? 🎨
Un mese e mezzo fa abbiamo rilasciato diffusers, una libreria che fornisce una serie di strumenti modulari per modelli di diffusione tra diverse modalità. Un paio di settimane dopo, abbiamo aggiunto il supporto per Stable Diffusion, un modello di alta qualità per la conversione di testo in immagine, con una demo gratuita per chiunque voglia provarlo. Oltre a bruciare un sacco di GPU, nelle ultime tre settimane il team ha deciso di aggiungere una o due nuove funzionalità alla libreria che speriamo la community apprezzi! Questo post sul blog fornisce una panoramica generale delle nuove funzionalità nella versione 0.3 di diffusers! Ricordatevi di dare una ⭐ al repository su GitHub.
- Pipeline da immagine a immagine
- Inversione testuale
- Inpainting
- Ottimizzazioni per GPU più piccole
- Esecuzione su Mac
- Esportatore ONNX
- Nuovi documenti
- Community
- Generazione di video con spazio latente SD
- Spiegabilità del modello
- Stable Diffusion giapponese
- Modello ad alta qualità sintonizzato
- Controllo dell’attenzione incrociata con Stable Diffusion
- Semi riutilizzabili
Pipeline da immagine a immagine
Una delle funzionalità più richieste era quella di avere la generazione da immagine a immagine. Questa pipeline permette di inserire un’immagine e una frase di input, e genererà un’immagine basata su di esse!
Vediamo un po’ di codice basato sul notebook ufficiale di Colab.
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Scarica un'immagine iniziale
# ...
init_image = preprocess(init_img)
prompt = "Un paesaggio fantastico, in tendenza su artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]Non hai tempo per il codice? Nessun problema, abbiamo anche creato una demo Space dove puoi provarlo direttamente.
- Come addestrare un Modello Linguistico con Megatron-LM
- Incredibilmente veloce inferenza BLOOM con DeepSpeed e Accelerate
- Newsletter Etica e Società #1
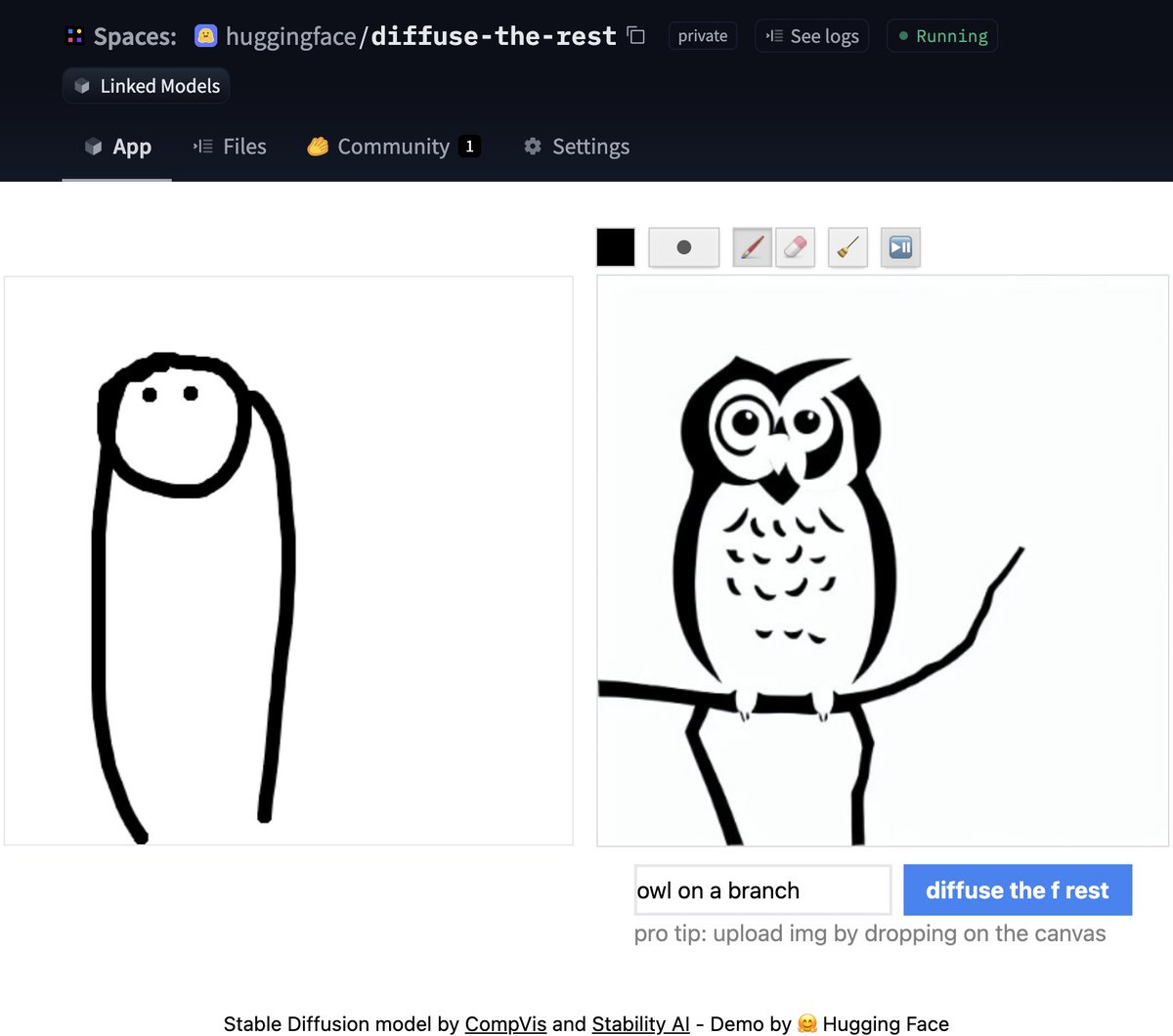
Inversione testuale
L’inversione testuale ti permette di personalizzare un modello Stable Diffusion sulle tue immagini con soli 3-5 campioni. Con questo strumento, puoi addestrare un modello su un concetto e condividerlo con il resto della community!
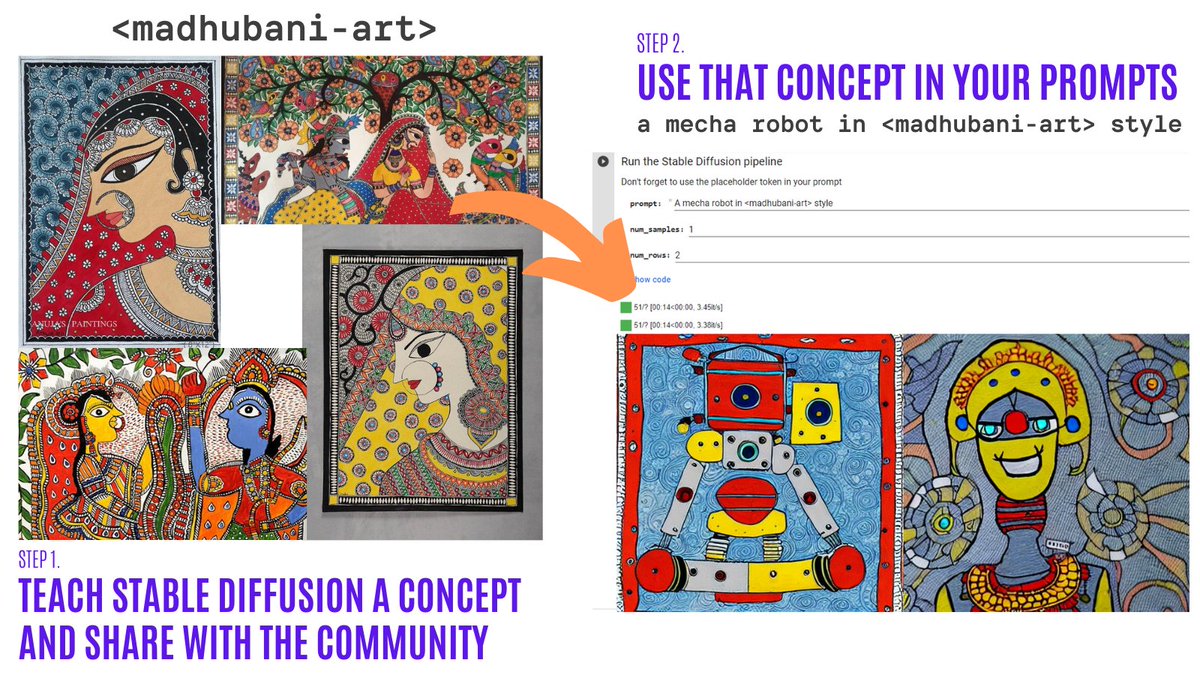
In solo un paio di giorni, la community ha condiviso oltre 200 concetti! Dai un’occhiata!
- Organizzazione dei concetti.
- Navigator Colab: Naviga visualmente e usa oltre 150 concetti creati dalla community.
- Training Colab: Insegna a Stable Diffusion un nuovo concetto e condividilo con il resto della community.
- Inference Colab: Esegui Stable Diffusion con i concetti appresi.
Pipeline di inpainting sperimentale
L’inpainting consente di fornire un’immagine, quindi selezionare un’area nell’immagine (o fornire una maschera) e utilizzare Stable Diffusion per sostituire la maschera. Ecco un esempio:

Puoi provare un notebook minimale di Colab o controllare il codice qui sotto. Una demo sarà disponibile a breve!
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["un gatto seduto su una panchina"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).imagesSi prega di notare che questa è una funzionalità sperimentale, quindi c’è spazio per miglioramenti.
Ottimizzazioni per GPU più piccole
Dopo alcuni miglioramenti, i modelli di diffusione possono richiedere molta meno VRAM. 🔥 Ad esempio, Stable Diffusion richiede solo 3,2 GB! Questo produce gli stessi risultati a scapito del 10% della velocità. Ecco come utilizzare queste ottimizzazioni
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()Questo è super eccitante perché ridurrà ancora di più la barriera nell’utilizzo di questi modelli!
Diffusori in Mac OS
🍎 Esatto! Un’altra funzionalità molto richiesta è stata appena rilasciata! Leggi le istruzioni complete nella documentazione ufficiale (incluse comparazioni delle prestazioni, specifiche e altro).
Utilizzando il dispositivo PyTorch mps, le persone con hardware M1/M2 possono eseguire l’inferenza con Stable Diffusion. 🤯 Questo richiede una configurazione minima per gli utenti, provare!
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "una foto di un astronauta che cavalca un cavallo su Marte"
image = pipe(prompt).images[0]Esportatore e pipeline ONNX sperimentali
La nuova pipeline sperimentale consente agli utenti di eseguire Stable Diffusion su qualsiasi hardware che supporti ONNX. Ecco un esempio di come utilizzarla (nota che viene utilizzata la revisione onnx)
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "una foto di un astronauta che cavalca un cavallo su Marte"
image = pipe(prompt).images[0]In alternativa, è anche possibile convertire direttamente i checkpoint di SD in ONNX tramite lo script di esportazione.
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"Nuova documentazione
Tutte le funzionalità precedenti sono molto interessanti. Come manutentori di librerie open-source, conosciamo l’importanza di documentazioni di alta qualità per renderle il più facile possibile per chiunque provi la libreria.
💅 Per questo motivo, abbiamo fatto uno sprint sulla documentazione e siamo molto entusiasti di fare una prima release della nostra documentazione. Questa è una prima versione, quindi ci sono molte cose che abbiamo intenzione di aggiungere (e i contributi sono sempre benvenuti!).
Alcuni punti salienti della documentazione:
- Tecniche per l’ottimizzazione
- La panoramica della formazione
- Una guida per i contributori
- Documentazione API approfondita per gli scheduler
- Documentazione API approfondita per le pipeline
Comunità
E mentre stavamo facendo tutto ciò, la comunità non è rimasta con le mani in mano! Ecco alcuni punti salienti (anche se non esaustivi) di ciò che è stato fatto
Video di Stable Diffusion
Crea 🔥 video con Stable Diffusion esplorando lo spazio latente e trasformando tra promemoria di testo. Puoi:
- Sognare diverse versioni dello stesso promemoria
- Trasformarti tra promemoria diversi
Lo strumento Video di Stable Diffusion è installabile tramite pip, viene fornito con un notebook Colab e un notebook Gradio ed è molto facile da utilizzare!
Ecco un esempio
from stable_diffusion_videos import walk
video_path = walk(['un gatto', 'un cane'], [42, 1337], num_steps=3, make_video=True)Diffusers Interpret
Diffusers interpret è uno strumento di spiegabilità sviluppato su diffusers. Ha funzionalità interessanti come:
- Visualizza tutte le immagini nel processo di diffusione
- Analizza come ogni token nel promemoria influenza la generazione
- Analizza all’interno di bounding box specificate se si desidera comprendere una parte dell’immagine
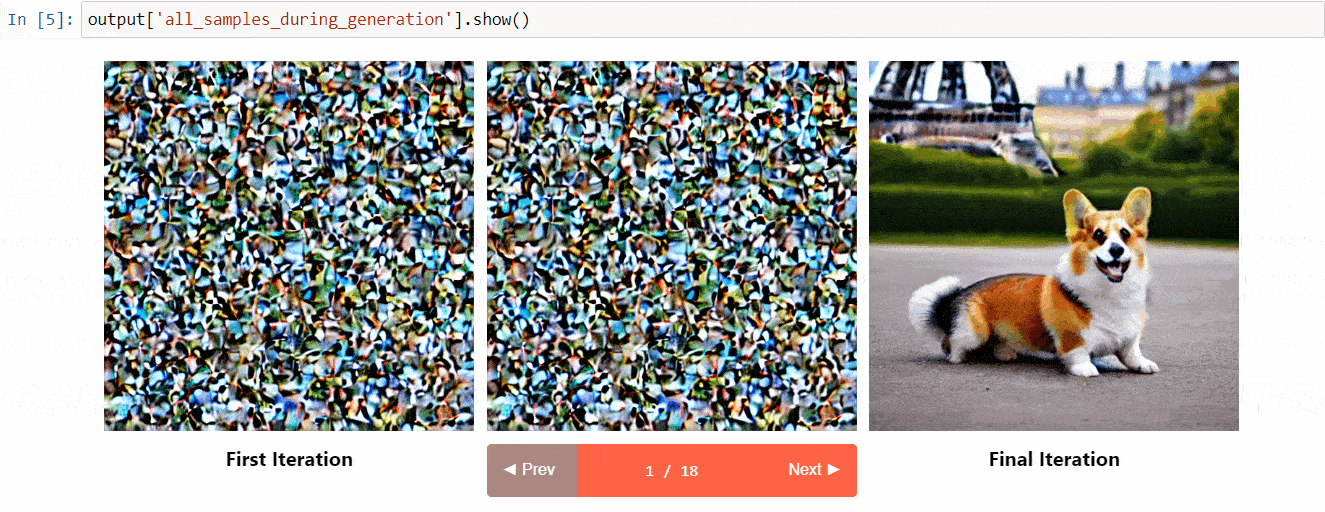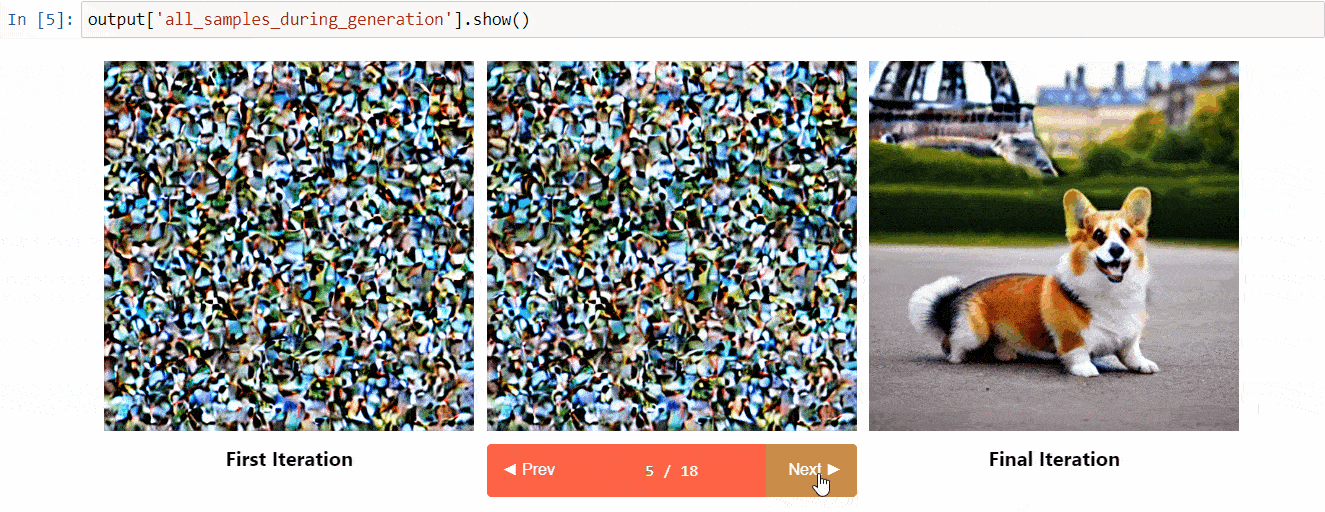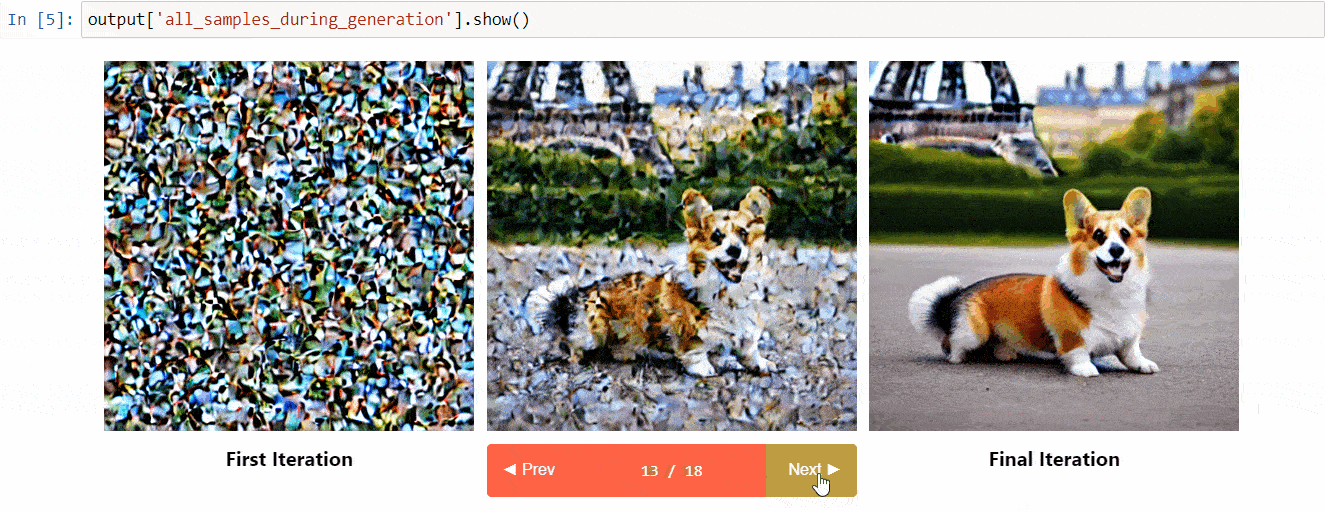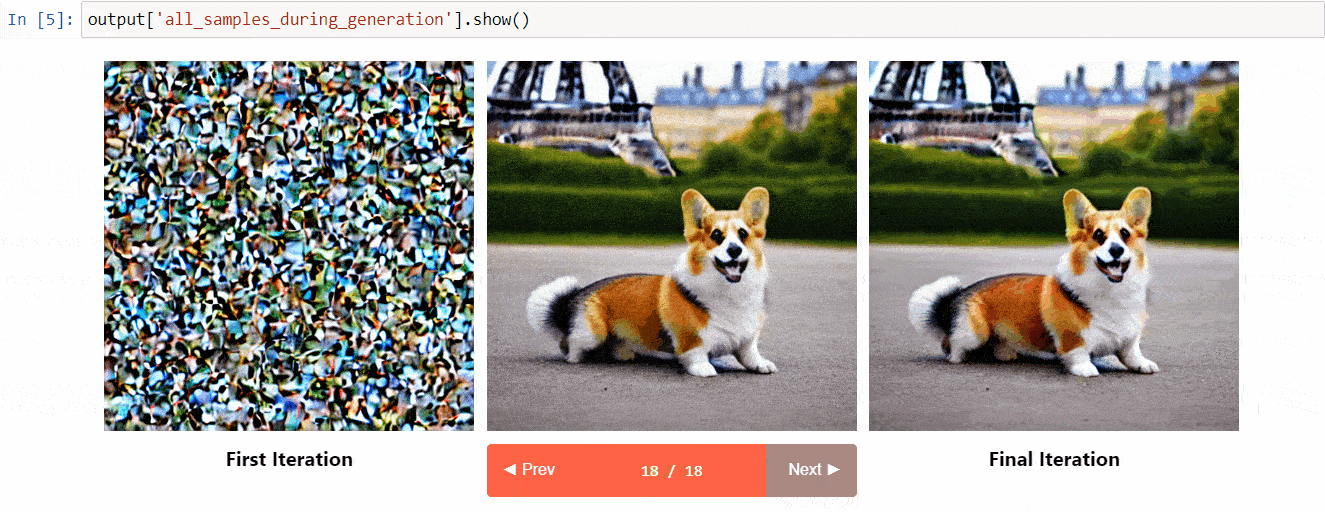 (Immagine dal repository degli strumenti)
(Immagine dal repository degli strumenti)
# passare il pipeline alla classe spiegatore
spiegatore = StableDiffusionPipelineExplainer(pipe)
# generare un'immagine con `spiegatore`
prompt = "Corgi con la Torre Eiffel"
output = spiegatore(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, percentuale_attribuzione)
#[('corgi', 40),
# ('con', 5),
# ('la', 5),
# ('torre', 25),
# ('eiffel', 25)]Diffusione stabile giapponese
Il nome dice tutto! L’obiettivo del JSD era quello di addestrare un modello che catturasse anche informazioni sulla cultura, l’identità e le espressioni uniche. È stato addestrato con 100 milioni di immagini con didascalie giapponesi. Puoi leggere di più su come è stato addestrato il modello nella carta del modello
Diffusione waifu
La diffusione waifu è un modello SD sintonizzato per la generazione di immagini anime di alta qualità.

(Immagine dal repository degli strumenti)
Controllo dell’attenzione incrociata
Il controllo dell’attenzione incrociata consente un controllo preciso delle prompt modificando le mappe di attenzione dei modelli di diffusione. Alcune cose interessanti che puoi fare:
- Sostituire un target nella prompt (ad esempio, sostituire “gatto” con “cane”)
- Ridurre o aumentare l’importanza delle parole nella prompt (ad esempio, se si desidera che venga data meno attenzione a “rocks”)
- Iniettare facilmente stili
E molto altro ancora! Dai un’occhiata al repository.
Semi riutilizzabili
Una delle dimostrazioni più impressionanti di Diffusione stabile è stata la riutilizzazione delle sementi per ottimizzare le immagini. L’idea è utilizzare la semente di un’immagine di interesse per generare una nuova immagine, con una prompt diversa. Questo produce risultati interessanti! Dai un’occhiata al Colab
Grazie per la lettura!
Spero che ti sia piaciuto leggere questo! Ricorda di dare una stella al nostro repository GitHub e unisciti al server Discord di Hugging Face, dove abbiamo una categoria di canali dedicati ai modelli di diffusione. Lì vengono condivise le ultime novità sulla libreria!
Sentiti libero di aprire issue con richieste di funzionalità e segnalazioni di bug! Tutto ciò che è stato realizzato non avrebbe potuto essere fatto senza una community così fantastica.





