Potenzia il tuo Python Asyncio con Aiomultiprocess Una guida completa
Potenzia Python Asyncio con Aiomultiprocess - guida completa.
PYTHON TOOLBOX
Sfrutta la potenza di asyncio e multiprocessing per potenziare le tue applicazioni

In questo articolo, ti condurrò nel mondo di aiomultiprocess, una libreria che combina le potenti capacità di Python asyncio e multiprocessing.
Questo articolo spiegherà attraverso ricchi esempi di codice e migliori pratiche.
Alla fine di questo articolo, comprenderai come sfruttare le potenti funzionalità di aiomultiprocess per migliorare le tue applicazioni Python, proprio come un capo cuoco che guida un team di cuochi per creare un delizioso banchetto.
Introduzione
Immagina che tu voglia invitare i tuoi colleghi per un grande pasto nel weekend. Come lo faresti?
- Come ho convertito un normale RDBMS in un database vettoriale per archiviare gli embedding
- Un ricercatore dell’UCLA ha sviluppato una libreria Python chiamata ClimateLearn per accedere ai dati climatici di ultima generazione e ai modelli di apprendimento automatico in modo standardizzato e semplice.
- Questo modello di linguaggio proteico basato sull’intelligenza artificiale sblocca la modellazione di sequenze a uso generale.
Come uno chef esperto, sicuramente non cucineresti un piatto alla volta; sarebbe troppo lento. Utilizzeresti efficientemente il tuo tempo, lasciando che più compiti avvengano contemporaneamente.
Ad esempio, mentre aspetti che l’acqua bolla, puoi allontanarti per lavare le verdure. In questo modo, puoi gettare le verdure nella pentola quando l’acqua bolle. Questo è il fascino della concorrenza.
Tuttavia, le ricette possono spesso essere crude: devi continuare a mescolare quando fai la zuppa; le verdure devono essere lavate e tagliate; devi anche cuocere il pane, friggere le bistecche e altro ancora.
Quando ci sono molti piatti da preparare, sarai sopraffatto.
Fortunatamente, i tuoi colleghi non resteranno seduti ad aspettare di mangiare. Entreranno in cucina per aiutarti, con ogni persona aggiuntiva che agisce come un processo di lavoro aggiuntivo. Questa è la potente combinazione di multiprocessing e concorrenza.
Lo stesso vale per il codice. Anche con asyncio, la tua applicazione Python ha ancora incontrato dei colli di bottiglia? Stai cercando modi per migliorare ulteriormente le prestazioni del tuo codice concorrente? In tal caso, aiomultiprocess è la risposta che stavi cercando.
Come installare e utilizzo di base
Installazione
Se usi pip, installalo in questo modo:
python -m pip install aiomultiprocessSe usi Anaconda, installalo da conda-forge:
conda install -c conda-forge aiomultiprocessUtilizzo di base
aiomultiprocess consiste in tre classi principali:
Process è la classe base per le altre due classi e viene utilizzata per avviare un processo ed eseguire una funzione coroutine. Di solito non è necessario utilizzare questa classe.
Worker viene utilizzata per avviare un processo, eseguire una funzione coroutine e restituire il risultato. Anche questa classe non la utilizzeremo.
Pool è la classe principale su cui ci concentreremo. Come multiprocessing.Pool, avvia un pool di processi, ma il suo contesto deve essere gestito utilizzando async with. Utilizzeremo i due metodi di Pool: map e apply.
Il metodo map accetta una funzione coroutine e un iterabile. Il Pool itererà sull’iterabile e assegnerà la funzione coroutine per essere eseguita su vari processi. Il risultato del metodo map può essere iterato in modo asincrono utilizzando async for:
import asyncioimport randomimport aiomultiprocessasync def coro_func(value: int) -> int: await asyncio.sleep(random.randint(1, 3)) return value * 2async def main(): results = [] async with aiomultiprocess.Pool() as pool: async for result in pool.map(coro_func, [1, 2, 3]): results.append(result) print(results)if __name__ == "__main__": asyncio.run(main())Il metodo apply accetta una funzione coroutine e la tupla di argomenti richiesti per la funzione. Secondo le regole dello scheduler, il Pool assegnerà la funzione coroutine a un processo appropriato per l’esecuzione.
import asyncioimport randomimport aiomultiprocessasync def coro_func(value: int) -> int: await asyncio.sleep(random.randint(1, 3)) return value * 2async def main(): tasks = [] async with aiomultiprocess.Pool() as pool: tasks.append(pool.apply(coro_func, (1,))) tasks.append(pool.apply(coro_func, (2,))) tasks.append(pool.apply(coro_func, (3,))) results = await asyncio.gather(*tasks) print(results) # Output: [2, 4, 6]if __name__ == "__main__": asyncio.run(main())Principio di implementazione ed esempi pratici
Principio di implementazione di aiomultiprocess.Pool
In un articolo precedente, ho spiegato come distribuire le attività di asyncio su più core CPU.
L’approccio generale consiste nell’avviare un pool di processi nel processo principale utilizzando loop.run_in_executor. Successivamente, viene creato un ciclo di eventi asyncio in ciascun processo nel pool di processi e le funzioni coroutine vengono eseguite nei rispettivi cicli. Lo schema è il seguente:
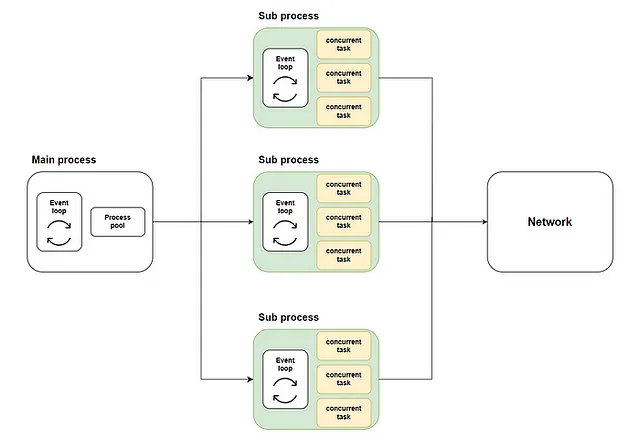
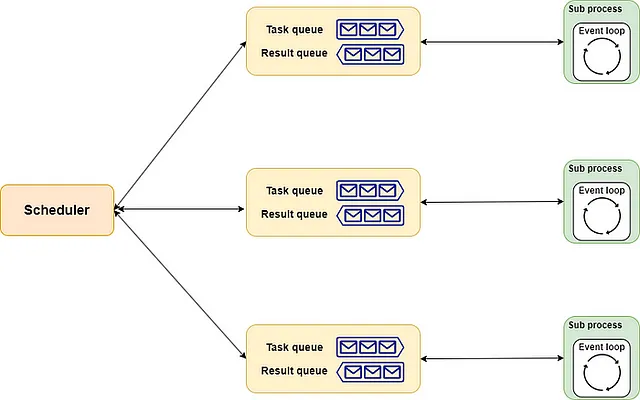
L’implementazione di aiomultiprocess.Pool è simile. Include scheduler, queue e process come suoi tre componenti.
- Lo
schedulerpuò essere considerato come lo chef capo, responsabile della distribuzione delle attività in modo adeguato a ciascun chef. Naturalmente, è possibile assumere (implementare) uno chef capo adatto alle proprie esigenze. - La
queueè simile alla linea di assemblaggio della cucina. Più precisamente, include una linea di ordine e una linea di consegna. Lo chef capo passa il menu attraverso la linea di ordine agli chef e gli chef restituiscono i piatti completati attraverso la linea di consegna. - Il
processè come gli chef nel ristorante. Ciascuno di essi gestisce contemporaneamente diversi piatti secondo l’allocazione. Ogni volta che un piatto è pronto, verrà consegnato secondo l’ordine assegnato.
L’intero schema è mostrato di seguito:
Esempio del mondo reale
In base all’introduzione fornita in precedenza, dovresti ora capire come utilizzare aiomultiprocess. Approfondiamo un esempio del mondo reale per sperimentare la sua potenza.
Prima di tutto, useremo una chiamata remota e un calcolo loop per simulare il processo di recupero e elaborazione dei dati nella vita reale. Questo metodo dimostra che le attività legate all’IO e legate alla CPU sono spesso mescolate insieme e il confine tra di esse non è così netto.
import asyncioimport randomimport timefrom aiohttp import ClientSessionfrom aiomultiprocess import Pooldef cpu_bound(n: int) -> int: result = 0 for i in range(n*100_000): result += 1 return resultasync def invoke_remote(url: str) -> int: await asyncio.sleep(random.uniform(0.2, 0.7)) async with ClientSession() as session: async with session.get(url) as response: status = response.status result = cpu_bound(status) return resultSuccessivamente, utilizziamo l’approccio tradizionale di asyncio per chiamare questa attività 30 volte come base:
async def main(): start = time.monotonic() tasks = [asyncio.create_task(invoke_remote("https://www.example.com")) for _ in range(30)] await asyncio.gather(*tasks) print(f"Tutti i lavori completati in {time.monotonic() - start} secondi")if __name__ == "__main__": asyncio.run(main())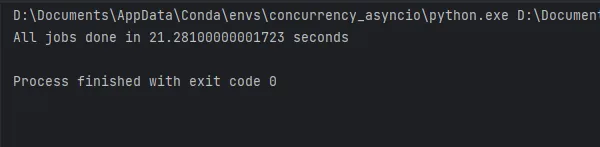
I risultati dell’esecuzione del codice sono mostrati nella figura e richiedono circa 21 secondi. Ora vediamo quanto può migliorare aiomultiprocess.
Utilizzare aiomultiprocess è semplice. Il codice concorrente originale non ha bisogno di essere modificato. È sufficiente regolare il codice nel metodo principale per eseguirlo all’interno del Pool:
async def main(): start = time.monotonic() async with Pool() as pool: tasks = [pool.apply(invoke_remote, ("https://www.example.com",)) for _ in range(30)] await asyncio.gather(*tasks) print(f"Tutti i lavori sono stati completati in {time.monotonic() - start} secondi")if __name__ == "__main__": asyncio.run(main())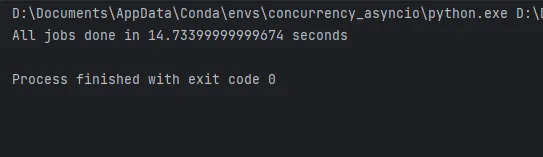
Come puoi vedere, il codice che utilizza aiomultiprocess impiega solo 14 secondi per completare sul mio computer portatile. Il miglioramento delle prestazioni sarebbe ancora maggiore su un computer più potente.
Pratiche consigliate dettagliate
Infine, basandomi sulla mia esperienza, vorrei condividere alcune pratiche consigliate più pratiche.
Usa solo il pool
Anche se aiomultiprocess fornisce anche le classi Process e Worker tra cui scegliere, dovremmo sempre utilizzare la classe Pool per garantire la massima efficienza a causa del notevole consumo di risorse nella creazione dei processi.
Come utilizzare le code
In un articolo precedente, ho spiegato come utilizzare asyncio.Queue per implementare il modello produttore-consumatore per bilanciare risorse e prestazioni. In aiomultiprocess, possiamo utilizzare anche le code. Tuttavia, poiché ci troviamo in un pool di processi, non possiamo utilizzare asyncio.Queue. Allo stesso tempo, non possiamo utilizzare direttamente multiprocessing.Queue nel pool di processi. In questo caso, dovresti utilizzare multiprocessing.Manager().Queue() per creare una coda, con il seguente codice:
import randomimport asynciofrom multiprocessing import Managerfrom multiprocessing.queues import Queuefrom aiomultiprocess import Poolasync def worker(name: str, queue: Queue): while True: item = queue.get() if not item: print(f"worker: {name} ha ricevuto il segnale di fine e smetterà di funzionare.") queue.put(item) break await asyncio.sleep(random.uniform(0.2, 0.7)) print(f"worker: {name} inizia a elaborare il valore {item}", flush=True)async def producer(queue: Queue): for i in range(20): await asyncio.sleep(random.uniform(0.2, 0.7)) queue.put(random.randint(1, 3)) queue.put(None)async def main(): queue: Queue = Manager().Queue() producer_task = asyncio.create_task(producer(queue)) async with Pool() as pool: c_tasks = [pool.apply(worker, args=(f"worker-{i}", queue)) for i in range(5)] await asyncio.gather(*c_tasks) await producer_taskif __name__ == "__main__": asyncio.run(main())Utilizzo di initializer per inizializzare risorse
Supponiamo che tu abbia bisogno di utilizzare una sessione aiohttp o un pool di connessioni al database in un metodo di coroutine, ma non possiamo passare argomenti durante la creazione delle attività nel processo principale perché questi oggetti non possono essere picklati.
Un’alternativa è definire un oggetto globale e un metodo di inizializzazione. In questo metodo di inizializzazione, accedi all’oggetto globale e esegui l’inizializzazione.
Proprio come multiprocessing.Pool, aiomultiprocess.Pool può accettare un metodo di inizializzazione e i relativi parametri di inizializzazione quando viene inizializzato. Questo metodo verrà chiamato per completare l’inizializzazione quando ogni processo viene avviato:
import asyncio
from aiomultiprocess import Pool
import aiohttp
from aiohttp import ClientSession, ClientTimeout
session: ClientSession | None = None
def init_session(timeout: ClientTimeout = None):
global session
session = aiohttp.ClientSession(timeout=timeout)
async def get_status(url: str) -> int:
global session
async with session.get(url) as response:
status_code = response.status
return status_code
async def main():
url = "https://httpbin.org/get"
timeout = ClientTimeout(2)
async with Pool(initializer=init_session, initargs=(timeout,)) as pool:
tasks = [asyncio.create_task(pool.apply(get_status, (url,)))
for i in range(3)]
status = await asyncio.gather(*tasks)
print(status)
if __name__ == "__main__":
asyncio.run(main())Gestione delle eccezioni e riprova
Anche se aiomultiprocess.Pool fornisce il parametro exception_handler per aiutare con la gestione delle eccezioni, se hai bisogno di maggiore flessibilità, devi combinarlo con asyncio.wait. Per l’uso di asyncio.wait, puoi fare riferimento al mio articolo precedente.
Con asyncio.wait, puoi ottenere i task che incontrano eccezioni. Dopo aver estratto il task, puoi apportare alcune modifiche e quindi eseguire nuovamente il task, come mostrato nel codice seguente:
import asyncio
import random
from aiomultiprocess import Pool
async def worker():
await asyncio.sleep(0.2)
result = random.random()
if result > 0.5:
print("solleverà un'eccezione")
raise Exception("qualcosa è andato storto")
return result
async def main():
pending, results = set(), []
async with Pool() as pool:
for i in range(7):
pending.add(asyncio.create_task(pool.apply(worker)))
while len(pending) > 0:
done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_EXCEPTION)
print(f"ora il conteggio di completati, in sospeso è {len(done)}, {len(pending)}")
for result in done:
if result.exception():
pending.add(asyncio.create_task(pool.apply(worker)))
else:
results.append(await result)
print(results)
if __name__ == "__main__":
asyncio.run(main())Utilizzo di Tenacity per le riprove
Ovviamente, abbiamo opzioni più flessibili e potenti per la gestione delle eccezioni e le riprove, come l’utilizzo della libreria Tenacity, che ho spiegato in questo articolo.
Con Tenacity, il codice sopra può essere significativamente semplificato. È sufficiente aggiungere un decoratore al metodo coroutine e il metodo verrà riprovato automaticamente quando viene generata un’eccezione.
import asyncio
from random import random
from aiomultiprocess import Pool
from tenacity import *
@retry()
async def worker(name: str):
await asyncio.sleep(0.3)
result = random()
if result > 0.6:
print(f"{name} solleverà un'eccezione")
raise Exception("qualcosa non va")
return result
async def main():
async with Pool() as pool:
tasks = pool.map(worker, [f"worker-{i}" for i in range(5)])
results = await tasks
print(results)
if __name__ == "__main__":
asyncio.run(main())Utilizzo di tqdm per indicare il progresso
Mi piace tqdm perché può sempre dirmi quanto il codice è stato eseguito quando sto aspettando davanti allo schermo. Questo articolo spiega anche come usarlo.
Dato che aiomultiprocess utilizza l’API di asyncio per attendere il completamento dei task, è anche compatibile con tqdm:
import asyncio
from random import uniform
from aiomultiprocess import Pool
from tqdm.asyncio import tqdm_asyncio
async def worker():
delay = uniform(0.5, 5)
await asyncio.sleep(delay)
return delay * 10
async def main():
async with Pool() as pool:
tasks = [asyncio.create_task(pool.apply(worker)) for _ in range(1000)]
results = await tqdm_asyncio.gather(*tasks)
print(results[:10])
if __name__ == "__main__":
asyncio.run(main())Conclusione
Eseguire il codice asyncio è come un cuoco che cucina un pasto. Anche se puoi migliorare l’efficienza eseguendo diverse attività contemporaneamente, alla fine incontrerai dei colli di bottiglia.
La soluzione più semplice a questo punto è aggiungere più cuochi per aumentare la parallelismo del processo di cottura.
Aiomultiprocess è una potente libreria Python. Consentendo l’esecuzione di attività concorrenti su processi multipli, supera perfettamente i colli di bottiglia di prestazione causati dalla natura single-threaded di asyncio.
L’uso e le migliori pratiche di aiomultiprocess in questo articolo si basano sulla mia esperienza lavorativa. Se sei interessato a qualche aspetto, sentiti libero di commentare e partecipare alla discussione.
Oltre al miglioramento della velocità di esecuzione del codice e delle prestazioni, l’utilizzo di vari strumenti per migliorare l’efficienza del lavoro è anche un miglioramento delle prestazioni:

Peng Qian
Python Toolbox
Visualizza l’elenco di 4 storie 
Unisciti a VoAGI con il mio link di riferimento – Peng Qian
Come membro di VoAGI, una parte della tua quota associativa va agli scrittori che leggi e hai accesso completo ad ogni storia…
qtalen.medium.com