Agenti orientati ai documenti Un viaggio con database vettoriali, LLM, Langchain, FastAPI e Docker
Agenti orientati ai documenti un viaggio con database vettoriali, LLM, Langchain, FastAPI e Docker.
Sfruttare ChromaDB, Langchain e ChatGPT: Risposte potenziate e fonti citate da ampi database di documenti
Introduzione
Gli agenti orientati ai documenti stanno iniziando a prendere piede nel panorama aziendale. Le aziende sfruttano sempre più questi strumenti per valorizzare la documentazione interna, potenziando i loro processi aziendali. Un recente rapporto di McKinsey [1] sottolinea questa tendenza, suggerendo che l’IA generativa potrebbe incrementare l’economia globale di 2,6-4,4 trilioni di dollari all’anno e automatizzare fino al 70% delle attività lavorative attuali. Lo studio identifica il servizio clienti, le vendite e il marketing e lo sviluppo software come i principali settori che saranno influenzati dalla trasformazione. La maggior parte del cambiamento deriva dal fatto che le informazioni che alimentano queste aree all’interno di un’azienda possono essere più accessibili sia ai dipendenti che ai clienti attraverso l’utilizzo di soluzioni come gli agenti orientati ai documenti.
Con la tecnologia attuale, ci troviamo ancora di fronte a alcune sfide. Anche se si considerano i nuovi modelli linguistici di grandi dimensioni (LLM) con limiti di 100.000 token, i modelli hanno comunque finestre di contesto limitate. Sebbene 100.000 token possano sembrare un numero elevato, è un numero insignificante se consideriamo la dimensione dei database che alimentano, ad esempio, un reparto di servizio clienti. Un altro problema che spesso sorge è l’inaccuratezza nei risultati del modello. In questo articolo, forniremo una guida passo-passo per la creazione di un agente orientato ai documenti in grado di gestire documenti di qualsiasi dimensione e fornire risposte verificabili.
Utilizziamo un database vettoriale, ChromaDB, per potenziare le capacità di lunghezza del contesto del nostro modello e Langchain per facilitare l’integrazione tra i diversi componenti della nostra architettura. Come nostro LLM, utilizziamo ChatGPT di OpenAI. Poiché desideriamo servire la nostra applicazione, utilizziamo FastAPI per creare endpoint per consentire agli utenti di interagire con il nostro agente. Infine, la nostra applicazione è containerizzata utilizzando Docker, il che ci consente di distribuirla facilmente in qualsiasi tipo di ambiente.
Come sempre, il codice è disponibile sul mio Github.
- Potenzia il tuo Python Asyncio con Aiomultiprocess Una guida completa
- Come ho convertito un normale RDBMS in un database vettoriale per archiviare gli embedding
- Un ricercatore dell’UCLA ha sviluppato una libreria Python chiamata ClimateLearn per accedere ai dati climatici di ultima generazione e ai modelli di apprendimento automatico in modo standardizzato e semplice.
Database vettoriali: il nucleo essenziale delle applicazioni di ricerca semantica
I database vettoriali sono essenziali per sbloccare il potenziale dell’IA generativa. Questi tipi di database sono ottimizzati per gestire embedding vettoriali, ovvero rappresentazioni di dati contenenti informazioni semantiche dettagliate dei dati originali. A differenza dei database scalari tradizionali, che hanno difficoltà con la complessità degli embedding vettoriali, i database vettoriali indicizzano questi embedding, associandoli al loro contenuto di origine e consentendo funzionalità avanzate come il recupero di informazioni semantiche e la memoria a lungo termine nelle applicazioni di intelligenza artificiale.
I database vettoriali non sono gli stessi degli indici vettoriali, come il Facebook AI Similarity Search (FAISS) – che abbiamo già trattato in precedenza in questa serie in un articolo [2]. Consentono l’inserimento, la cancellazione e l’aggiornamento dei dati, archiviano i metadati associati e supportano l’aggiornamento dei dati in tempo reale senza la necessità di una completa riindicizzazione, un processo lungo e computazionalmente oneroso.
Invece di corrispondenze esatte, i database vettoriali utilizzano metriche di similarità per trovare i vettori più vicini a una query. Utilizzano algoritmi di ricerca del vicino più approssimato (ANN) per ottimizzare la ricerca. Alcuni esempi di tali algoritmi sono: Random Projection, Product Quantization o Hierarchical Navigable Small World. Questi algoritmi comprimono il vettore originale, accelerando il processo di interrogazione. Inoltre, le misure di similarità come la similarità del coseno, la distanza euclidea e il prodotto scalare confrontano e identificano i risultati più rilevanti per una query.
La Figura 2 illustra in modo sintetico il processo di ricerca di similarità nei database vettoriali. Partendo dall’ingestione dei documenti grezzi (i), i dati vengono suddivisi in blocchi gestibili (ii) e convertiti in embedding vettoriali (iii). Questi embedding vengono indicizzati per un rapido recupero (iv), e vengono calcolate metriche di similarità tra i vettori dei blocchi e la query dell’utente (v). Il processo si conclude con la produzione dei blocchi di dati più rilevanti (vi), offrendo agli utenti informazioni allineate alla loro query originale.
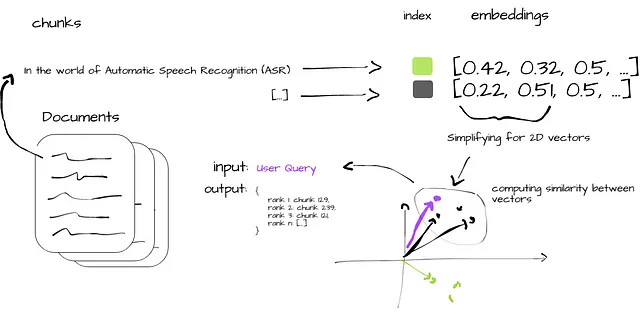
Costruzione di un Agente Orientato ai Documenti
Iniziamo caricando tutti i modelli e i dati necessari all’avvio del server.
Carichiamo i dati da una directory predefinita e li processiamo in blocchi gestibili. Questi blocchi sono progettati in modo da poterli passare al LLM una volta ottenuti i risultati dalla procedura di ricerca di similarità. Questo processo utilizza il DirectoryLoader per caricare i documenti in memoria e il RecursiveCharacterTextSplitter per suddividerli in blocchi gestibili. Vengono suddivisi i documenti a livello di carattere, con una dimensione di blocco predefinita di 1000 caratteri e un sovrapposizione tra blocchi di 20 caratteri. La sovrapposizione tra blocchi garantisce la continuità contestuale tra i blocchi, riducendo al minimo il rischio di perdere contesto significativo ai confini dei blocchi.
def load_docs(directory: str): """ Carica i documenti dalla directory specificata. """ loader = DirectoryLoader(directory) documents = loader.load() return documentsdef split_docs(documents, chunk_size=1000, chunk_overlap=20): """ Suddivide i documenti in blocchi. """ text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) docs = text_splitter.split_documents(documents) return docsSuccessivamente, generiamo rappresentazioni vettoriali da questi blocchi utilizzando il metodo SentenceTransformerEmbeddings e li indicizziamo in ChromaDB, il nostro database vettoriale. Queste rappresentazioni vettoriali vengono memorizzate nel database e fungono da dati cercabili. Il database non risiede in memoria; osserva che lo stiamo persistendo su disco, il che riduce il carico sulla memoria. Successivamente, carichiamo il modello di chat, nello specifico il gpt-3.5-turbo di OpenAI, che funge da nostro LLM.
@app.on_event("startup")async def startup_event(): """ Carica tutti i modelli e i dati necessari una volta che il server è avviato. """ app.directory = '/app/content/' app.documents = load_docs(app.directory) app.docs = split_docs(app.documents) app.embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2") app.persist_directory = "chroma_db" app.vectordb = Chroma.from_documents( documents=app.docs, embedding=app.embeddings, persist_directory=app.persist_directory ) app.vectordb.persist() app.model_name = "gpt-3.5-turbo" app.llm = ChatOpenAI(model_name=app.model_name) app.db = Chroma.from_documents(app.docs, app.embeddings) app.chain = load_qa_chain(app.llm, chain_type="stuff", verbose=True)Infine, l’endpoint “/query/{question}” riceve le query degli utenti. Viene eseguita una ricerca di similarità nel database utilizzando la domanda come input. Se esistono documenti corrispondenti, vengono forniti al LLM e viene generata la risposta. La risposta e le fonti (i documenti originali e i loro metadati) vengono restituiti, garantendo che le informazioni fornite siano facilmente verificabili.
@app.get("/query/{question}")async def query_chain(question: str): """ Esegue una query al modello con una domanda specificata e restituisce la risposta. """ matching_docs_score = app.db.similarity_search_with_score(question) if len(matching_docs_score) == 0: raise HTTPException(status_code=404, detail="Nessun documento corrispondente trovato") matching_docs = [doc for doc, score in matching_docs_score] answer = app.chain.run(input_documents=matching_docs, question=question) # Prepara le fonti sources = [{ "contenuto": doc.page_content, "metadati": doc.metadata, "score": score } for doc, score in matching_docs_score] return {"risposta": answer, "fonti": sources}Abbiamo containerizzato l’applicazione utilizzando Docker, il che garantisce isolamento e coerenza dell’ambiente, indipendentemente dalla piattaforma di distribuzione. Il Dockerfile di seguito descrive la nostra configurazione:
FROM python:3.9-busterWORKDIR /appCOPY . /appRUN pip install - no-cache-dir -r requirements.txtEXPOSE 1010CMD ["uvicorn", "main:app", " - host", "0.0.0.0", " - port", "1010"]L’applicazione viene eseguita in un ambiente Python 3.9 e è necessario installare tutte le dipendenze necessarie da un file requirements.txt:
langchain==0.0.221uvicorn==0.22.0fastapi==0.99.1unstructured==0.7.12sentence-transformers==2.2.2chromadb==0.3.26openai==0.27.8python-dotenv==1.0.0L’applicazione viene quindi servita tramite Uvicorn sulla porta 1010.
Si noti che è necessario configurare le variabili d’ambiente. La nostra applicazione richiede la OPENAI_API_KEY per il modello ChatOpenAI. La pratica migliore per le informazioni sensibili come le chiavi API è memorizzarle come variabili d’ambiente invece di codificarle direttamente nell’applicazione. Utilizziamo il pacchetto python-dotenv per caricare le variabili d’ambiente da un file .env nella root del progetto. In un ambiente di produzione, vorremmo utilizzare un metodo più sicuro, come Docker secrets o un servizio di archivio sicuro.
Esperimento: Comprendere l’efficacia degli agenti orientati ai documenti
Il principale obiettivo dell’esperimento era valutare l’efficacia del nostro agente orientato ai documenti nel fornire risposte complete e accurate alle query degli utenti.
Utilizziamo una serie di articoli VoAGI come base di conoscenza. Questi articoli, che coprono una varietà di argomenti sull’IA e sull’apprendimento automatico, vengono trasformati in vettori e indicizzati nel nostro database a vettori cromatici. Gli articoli selezionati sono:
- “Whisper JAX vs PyTorch: Scoprire la verità sulle prestazioni ASR sulle GPU”
- “Test del modello di linguaggio multilingue massivamente (MMS) che supporta 1162 lingue”
- “Sfruttare il modello Falcon 40B, il LLM open source più potente”
- “Il potere della chiamata di funzione di OpenAI nell’apprendimento del linguaggio: una guida completa”
Gli articoli sono stati suddivisi in parti gestibili, convertiti in embedding vettoriali e indicizzati nel nostro database, costituendo così la base di conoscenza dell’agente.
La query dell’utente è stata eseguita chiamando l’endpoint API della nostra applicazione, implementato con FastAPI e distribuito tramite Docker. La query utilizzata per l’esperimento è stata: “Cos’è Falcon-40b e posso usarlo per uso commerciale?”
curl --location 'http://0.0.0.0:1010/query/Cos'è Falcon-40b e posso usarlo per uso commerciale'In risposta alla nostra query, il LLM ha spiegato cos’è Falcon-40b e ha confermato che può essere utilizzato per scopi commerciali. Le informazioni sono state supportate da quattro diverse parti del testo, tutte tratte dall’articolo: “Sfruttare il modello Falcon 40B, il LLM open source più potente”. Ogni parte del testo è stata aggiunta anche alla risposta, come abbiamo visto in precedenza, in modo che l’utente potesse verificare il testo originale che supporta la risposta del LLM. Le parti del testo sono state valutate anche in base alla loro rilevanza rispetto alla query, fornendo così una prospettiva aggiuntiva sull’importanza di quella sezione per la risposta complessiva dell’agente.
{ "risposta": "Falcon-40B è un modello di linguaggio all'avanguardia sviluppato dal Technology Innovation Institute (TII). È un modello basato su transformer che si comporta bene in diverse attività di comprensione del linguaggio. Il significato di Falcon-40B è che ora è disponibile per un uso commerciale e di ricerca gratuito, come annunciato da TII. Ciò significa che sviluppatori e ricercatori possono accedere e modificare il modello in base alle proprie esigenze specifiche senza dover pagare royalty. Tuttavia, è importante notare che sebbene Falcon-40B sia disponibile per un uso commerciale, è comunque addestrato su dati web e potrebbe contenere pregiudizi e stereotipi presenti online. Pertanto, dovrebbero essere implementate adeguate strategie di mitigazione quando si utilizza Falcon-40B in un ambiente di produzione.", "fonti": [ { "contenuto": "Qui risiede il significato di Falcon-40B. Alla fine della scorsa settimana, il Technology Innovation Institute (TII) ha annunciato che Falcon-40B è ora privo di royalty per un uso commerciale e di ricerca. In questo modo, vengono abbattute le barriere dei modelli proprietari, offrendo a sviluppatori e ricercatori un accesso gratuito a un modello di linguaggio all'avanguardia che possono utilizzare e modificare in base alle loro specifiche esigenze.\n\nInoltre, il modello Falcon-40B è ora il modello con le migliori prestazioni nella classifica OpenLLM, superando modelli come LLaMA, StableLM, RedPajama e MPT. Questa classifica mira a tracciare, classificare e valutare le prestazioni di vari LLM e chatbot, fornendo una metrica chiara e imparziale delle loro capacità. Figura 1: Falcon-40B domina la classifica OpenLLM (fonte dell'immagine)\n\nCome sempre, il codice è disponibile sul mio Github. Come è stato sviluppato Falcon LLM?", "metadati": { "fonte": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt" }, "punteggio": 1.045290231704712 }, { "contenuto": "Il blocco decoder in Falcon-40B presenta un design di attenzione/MLP (Multi-Layer Perceptron) parallelo con normalizzazione a due livelli. Questa struttura offre vantaggi in termini di ridimensionamento del modello e velocità computazionale. La parallelizzazione dei livelli di attenzione e MLP migliora la capacità del modello di elaborare grandi quantità di dati contemporaneamente, riducendo così il tempo di addestramento. Inoltre, l'implementazione della normalizzazione a due livelli aiuta a stabilizzare il processo di apprendimento e a mitigare problemi legati allo spostamento covariante interno, risultando in un modello più robusto e affidabile. Implementazione delle capacità di chat con Falcon-40B-Instruct\n\nStiamo utilizzando Falcon-40B-Instruct, che è la nuova variante di Falcon-40B. È fondamentalmente lo stesso modello, ma ottimizzato su una miscela di Baize. Baize è un modello di chat open source addestrato con LoRA, una versione a basso rango di modelli di linguaggio di grandi dimensioni. Baize utilizza 100.000 dialoghi di ChatGPT che chiacchierano tra loro e anche i dati di Alpaca per migliorare le sue prestazioni.", "metadati": { "fonte": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt" }, "punteggio": 1.319214940071106 }, { "contenuto": "Una delle differenze fondamentali nello sviluppo di Falcon riguardava la qualità dei dati di addestramento. La dimensione dei dati di preaddestramento per Falcon era di quasi cinque trilioni di token raccolti da crawl web pubblici, articoli di ricerca e conversazioni sui social media. Poiché gli LLM sono particolarmente sensibili ai dati su cui vengono addestrati, il team ha costruito un flusso di dati personalizzato per estrarre dati di alta qualità dai dati di preaddestramento utilizzando un'ampia filtrazione e deduplicazione.\n\nIl modello stesso è stato addestrato nel corso di due mesi utilizzando 384 GPU su AWS. Il risultato è un LLM che supera GPT-3, richiedendo solo il 75% del budget di calcolo per l'addestramento e un quinto delle risorse di calcolo al momento dell'infere", "metadati": { "fonte": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt" }, "punteggio": 1.3254718780517578 }, { "contenuto": "Falcon-40B è incentrato sull'inglese, ma include anche funzionalità linguistiche in tedesco, spagnolo, francese, italiano, portoghese, polacco, olandese, rumeno, ceco e svedese. Tuttavia, come qualsiasi modello addestrato sui dati web, può comportare il rischio potenziale di riflettere i pregiudizi e gli stereotipi presenti online. Pertanto, valutare adeguatamente questi rischi e implementare adeguate strategie di mitigazione quando si utilizza Falcon-40B in un ambiente di produzione. Architettura e obiettivo del modello\n\nFalcon-40B, come membro della famiglia dei modelli basati su transformer, segue l'attività di modellazione del linguaggio causale, dove l'obiettivo è prevedere il token successivo in una sequenza di token. La sua architettura si basa fondamentalmente sui principi di progettazione di GPT-3 [1], con alcune importanti modifiche.", "metadati": { "fonte": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt" }, "punteggio": 1.3283030986785889 } ]}Conclusioni
In questo articolo, abbiamo costruito una soluzione per superare le sfide nel gestire documenti di grande scala nei sistemi di intelligenza artificiale, sfruttando database vettoriali e una serie di strumenti open-source. Il nostro approccio utilizza ChromaDB e Langchain con ChatGPT di OpenAI per creare un agente orientato ai documenti in grado.
Il nostro approccio consente all’agente di rispondere a query complesse cercando e elaborando frammenti di testo da database di grande scala, nel nostro caso una serie di articoli VoAGI su vari argomenti di intelligenza artificiale. Oltre alle risposte dell’agente, restituiamo anche i frammenti dei documenti originali utilizzati per supportare le affermazioni del LLM e il loro punteggio relativo alla similarità con la query dell’utente. È una caratteristica importante poiché questi agenti possono fornire informazioni non accurate.
Cronache dei Modelli di Linguaggio di Grande Dimensione: Navigare la Frontiera dell’NLP
Questo articolo fa parte delle “Cronache dei Modelli di Linguaggio di Grande Dimensione: Navigare la Frontiera dell’NLP”, una nuova serie settimanale di articoli che esplorerà come sfruttare il potere dei grandi modelli per vari compiti di NLP. Approfondendo queste tecnologie all’avanguardia, miriamo a fornire agli sviluppatori, ai ricercatori e agli appassionati gli strumenti per sfruttare il potenziale dell’NLP e sbloccare nuove possibilità.
Articoli pubblicati finora:
- Riassumere le ultime uscite di Spotify con ChatGPT
- Padroneggiare la Ricerca Semantica su Ampia Scala: Indicizzare Milioni di Documenti con Tempi di Inferenza Velocissimi utilizzando FAISS e Sentence Transformers
- Sfruttare il Potere dei Dati Audio: Trascrizione Avanzata e Diarizzazione con Whisper, WhisperX e PyAnnotate
- Whisper JAX vs PyTorch: Scoprire la Verità sulle Prestazioni ASR sulle GPU
- Vosk per un Riconoscimento Vocale Imprenditoriale Efficiente: Guida all’Valutazione e all’Implementazione
- Testare il Modello di Parlato Massivamente Multilingue (MMS) che Supporta 1162 Lingue
- Sfruttare il Modello Falcon 40B, il Più Potente Modello Open-Source LLM
- Il Potere delle Chiamate di Funzione di OpenAI nell’Apprendimento del Linguaggio: Guida Completa
Riferimenti
[1] https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier#introduction
[2] Padroneggiare la Ricerca Semantica su Ampia Scala: Indicizzare Milioni di Documenti con Tempi di Inferenza Velocissimi utilizzando FAISS e Sentence Transformers
Rimani in contatto: LinkedIn