Piattaforme di dati sintetici sbloccare il potere dell’IA generativa per i dati strutturati.
Piattaforme di dati sintetici per l'IA generativa sui dati strutturati.

Creare un modello di machine learning o deep learning è così facile.. Oggi ci sono diversi strumenti e piattaforme disponibili non solo per automatizzare l’intero processo di creazione di un modello, ma anche per aiutarti a selezionare il miglior modello per un determinato set di dati.
Una delle cose essenziali necessarie per risolvere un problema creando un modello è un dataset che contiene tutti gli attributi necessari per descrivere il problema che stai cercando di risolvere.. Quindi, supponiamo di esaminare un dataset che descrive la storia del diabete dei pazienti. Ci saranno colonne specifiche che sono gli attributi significativi come età, sesso, livello di glucosio, ecc. che svolgono un ruolo essenziale nella previsione se una persona ha il diabete o meno. Per costruire un modello di previsione del diabete, possiamo trovare più dataset disponibili pubblicamente. Tuttavia, potremmo incontrare difficoltà nel risolvere problemi in cui i dati non sono immediatamente disponibili o altamente sbilanciati.
- L’IA di Deblur di Google Rendi nitide le tue immagini
- Google Deblur AI Rendi nitide le tue immagini
- GPT-4 ha perso questa battaglia 449 a 28
Cos’è il dato sintetico?
I dati sintetici generati da algoritmi di deep learning sono spesso utilizzati come sostituti dei dati originali quando l’accesso ai dati è limitato dalla conformità alla privacy o quando i dati originali devono essere aumentati per adattarsi a scopi specifici. I dati sintetici mimano i dati reali ricreando le proprietà statistiche. Una volta addestrato sui dati reali, il generatore di dati sintetici può creare qualsiasi quantità di dati che somigliano da vicino ai modelli, alle distribuzioni e alle dipendenze dei dati reali. Questo non solo aiuta a generare dati simili, ma aiuta anche a introdurre determinati vincoli ai dati, come nuove distribuzioni. Esploriamo alcuni casi d’uso in cui i dati sintetici possono svolgere un ruolo importante.
- Generazione di dati confidenziali: I dati nel settore bancario, assicurativo, sanitario e persino delle telecomunicazioni possono essere estremamente sensibili. Toccare questi dati di solito richiede autorizzazioni speciali per ogni progetto. La generazione di dati sintetici può sbloccare questi asset di dati e essere utilizzata per creare funzionalità, comprendere il comportamento degli utenti, testare modelli ed esplorare nuove idee.
- Riequilibrare i dati: I dati altamente sbilanciati possono essere riequilibrati in modo efficace e facile utilizzando generatori di dati sintetici. Funziona meglio dell’upsampling ingenuo e nei casi di grande sbilanciamento, come i modelli di frode, può superare metodi più sofisticati, come SMOTE.
- Imputazione dei punti dati mancanti: I valori nulli sono una parte fastidiosa della vita quando si lavora con i dati. Riempiendo questi spazi vuoti con punti dati sintetici significativi, la lettura dei campioni può diventare un esercizio più informativo.
Come vengono generati i dati sintetici?
I modelli generativi di intelligenza artificiale sono fondamentali nella produzione di dati sintetici poiché sono esplicitamente addestrati sul dataset originale e possono replicarne le caratteristiche e gli attributi statistici. Modelli di intelligenza artificiale generativa, come le reti generative avversarie (GAN) o gli autoencoder variazionali (VAE), comprendono i dati sottostanti e producono istanze sintetiche realistiche e rappresentative. Esistono numerosi generatori di dati sintetici open-source e closed source, alcuni migliori di altri. Quando si valuta le prestazioni dei generatori di dati sintetici, è importante considerare due aspetti: l’accuratezza e la privacy. L’accuratezza deve essere elevata senza che i dati sintetici si adattino troppo ai dati originali e i valori estremi presenti nei dati originali devono essere gestiti in modo tale da non compromettere la privacy dei soggetti dei dati. Alcuni generatori di dati sintetici offrono controlli automatizzati sulla privacy e sull’accuratezza: è una buona idea iniziare con questi. Il generatore di dati sintetici di MOSTLY AI offre questo servizio gratuitamente: chiunque può creare un account con solo un indirizzo email.
Vantaggi dei dati sintetici
I dati sintetici non sono dati personali per definizione. Pertanto, sono esenti dal GDPR e da leggi sulla privacy simili, consentendo ai data scientist di esplorare liberamente le versioni sintetiche dei dataset. I dati sintetici sono anche uno dei migliori strumenti per anonimizzare i dati comportamentali senza distruggere modelli e correlazioni. Queste due qualità lo rendono particolarmente utile in tutte le situazioni in cui vengono utilizzati dati personali, dalle semplici analisi all’addestramento di modelli di machine learning sofisticati.
Tuttavia, la privacy non è l’unico caso d’uso. La generazione di dati sintetici può essere utilizzata anche nei seguenti casi d’uso:
- Aumento dei dati: questo aiuta nel processo di miglioramento delle prestazioni del modello attraverso la diversificazione dei dati di addestramento.
- Imputazione dei dati: riempire i punti dati mancanti con dati sintetici significativi.
- Condivisione dei dati: sicuro da condividere anche al di fuori delle mura delle organizzazioni. Pensate a collaborazioni di ricerca o alla dimostrazione di prodotti con dati realistici.
- Riequilibratura: affronta i problemi dello sbilanciamento delle classi.
- Downsampling: creazione di versioni più piccole di dataset massicci che appaiono e significano la stessa cosa dell’originale. Utile per le prime esplorazioni dei dati, riducendo i costi e i tempi computazionali.
I tool più popolari per la generazione di dati sintetici
Per generare dati sintetici possiamo utilizzare diversi strumenti disponibili sul mercato. Esaminiamo alcuni di questi strumenti e capiamo come funzionano.
- MOSTLY AI: MOSTLY AI è il leader pioniere nella creazione di dati sintetici strutturati. Consente a chiunque di generare dati sintetici di alta qualità, simili a quelli produttivi, per analisi, sviluppo di intelligenza artificiale/apprendimento automatico ed esplorazione dei dati. I team di dati possono usarlo per creare, modificare e condividere set di dati in modo da superare le sfide etiche e pratiche dell’utilizzo di dati reali, anonimizzati o fittizi.
- SDV: La libreria Python open-source più popolare per la generazione di dati sintetici. Non è lo strumento più sofisticato, ma fa il lavoro per casi d’uso più semplici quando l’alta precisione non è un requisito rigido.
- YData: Se desideri provare la generazione di dati sintetici su Azure o sul marketplace AWS, il generatore di YData è disponibile su entrambe le piattaforme, offrendo un modo conforme al GDPR per generare dati per modelli di intelligenza artificiale e apprendimento automatico.
Per una lista completa di strumenti e aziende per la generazione di dati sintetici, ecco una lista selezionata con tipi di dati sintetici.
Ora che abbiamo discusso i pro e i contro dell’utilizzo di questi strumenti e librerie descritte sopra per la generazione di dati sintetici, vediamo come possiamo utilizzare Mostly AI, che è uno dei migliori strumenti disponibili sul mercato ed è facile da usare.
MOSTLY AI è una piattaforma di creazione di dati sintetici che aiuta le aziende a produrre dati sintetici di alta qualità, protetti in termini di privacy, per una serie di casi d’uso come l’apprendimento automatico, l’analisi avanzata, il testing del software e la condivisione dei dati. Genera dati sintetici utilizzando un algoritmo proprietario basato sull’intelligenza artificiale che apprende gli aspetti statistici dei dati originali, come correlazioni, distribuzioni e proprietà. Ciò consente a MOSTLY AI di produrre dati sintetici che sono statisticamente rappresentativi dei dati effettivi, garantendo al contempo la privacy dei soggetti dei dati.
I dati sintetici di MOSTLY AI non sono solo privati, ma sono anche semplici da usare e possono essere creati in pochi minuti. La piattaforma ha un’interfaccia facile da usare alimentata dall’intelligenza artificiale generativa che consente alle organizzazioni di inserire dati esistenti, scegliere il formato di output appropriato e produrre dati sintetici in pochi secondi. I dati sintetici sono uno strumento utile per le organizzazioni che hanno bisogno di preservare la privacy dei loro dati pur utilizzandoli per una serie di obiettivi. La tecnologia è semplice da usare e crea rapidamente dati sintetici di alta qualità e statisticamente rappresentativi.
I dati sintetici di MOSTLY AI sono offerti in diversi formati, tra cui CSV, JSON e XML. Possono essere utilizzati con vari programmi software, tra cui SAS, R e Python. Inoltre, MOSTLY AI fornisce diversi strumenti e servizi, come un generatore di dati, un esploratore di dati e una piattaforma di condivisione dei dati, per aiutare le organizzazioni nell’uso dei dati sintetici.
Esploriamo come utilizzare la piattaforma MOSTLY AI. Possiamo iniziare visitando il link di seguito e creando un account.
MOSTLY AI: Piattaforma di generazione di dati sintetici e Knowledge Hub – MOSTLY AI
Una volta creato l’account, possiamo vedere la homepage in cui possiamo scegliere tra diverse opzioni legate alla generazione di dati.
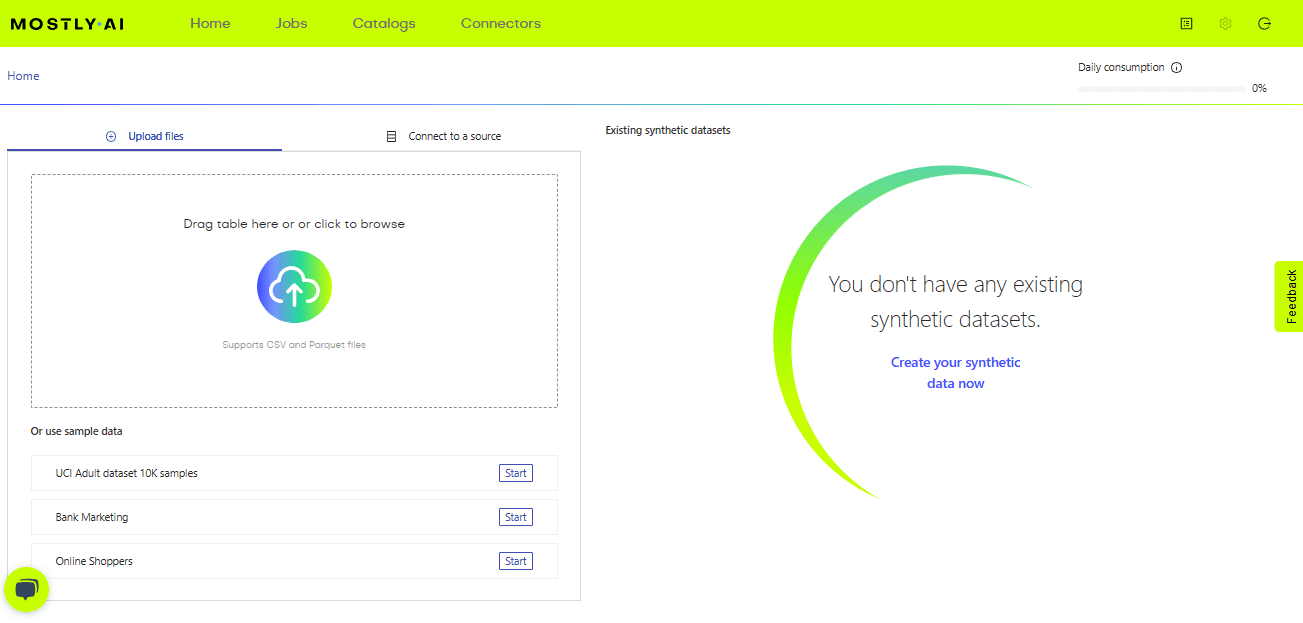
Come puoi vedere nell’immagine sopra, sulla homepage possiamo caricare il dataset originale per il quale vogliamo generare dati sintetici o semplicemente provare a utilizzare i dati di esempio. Possiamo caricare dati in base alle nostre esigenze.
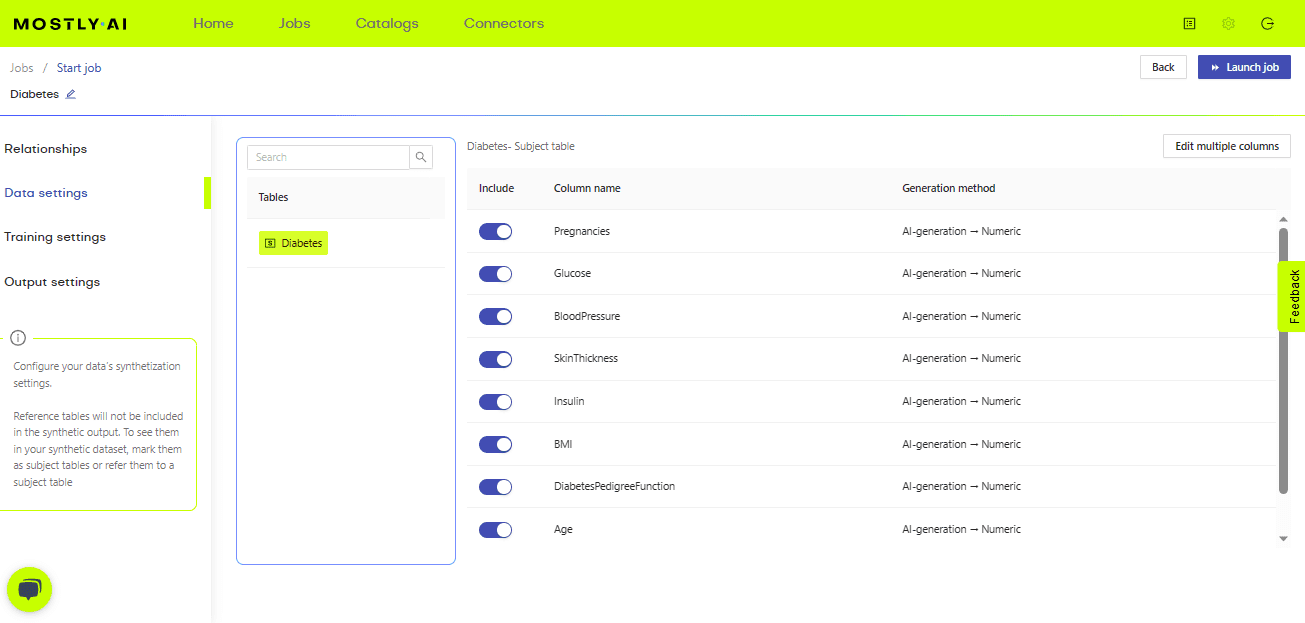
Come puoi vedere nell’immagine sopra, una volta caricati i dati possiamo apportare modifiche in termini di quali colonne vogliamo generare e impostare diverse impostazioni relative ai dati, all’addestramento e all’output.
Una volta impostate tutte queste proprietà secondo le nostre esigenze, dobbiamo fare clic sul pulsante “Avvia lavoro” per generare i dati e verranno generati in tempo reale. Su MOSTLY AI, possiamo generare gratuitamente 100.000 righe di dati al giorno.
Questo è come puoi utilizzare MOSTLY AI per generare dati sintetici impostando le proprietà dei dati come richiesto e in tempo reale. Ci possono essere molteplici casi d’uso in base al problema che stai cercando di risolvere. Prova questa piattaforma con i set di dati e facci sapere quanto utile pensi che sia, nella sezione di risposta. Himanshu Sharma è un laureato magistrale in Data Science Applicata presso l’Istituto di Product Leadership. Un professionista motivato con esperienza nel lavoro con il linguaggio di programmazione Python/Analisi dei dati. Cerco di fare la mia parte nel campo della Data Science. Product Management. Un blogger attivo con competenze nella stesura di contenuti tecnici in Data Science, premiato come Miglior Scrittore nel campo dell’IA da VoAGI.




