Parla con i tuoi documenti come PDF, txt e persino pagine web
Parla con i tuoi documenti e pagine web come PDF e txt
Guida completa alla creazione di un sito web e all’intelligenza che ti consente di fare domande ai documenti come PDF, TXT e persino pagine web utilizzando LLM.
Tabella dei contenuti
· Introduzione· Come funziona· Passaggi (parte 1) 👣· Interruzione: Ripassiamo (parte 1) 🌪️· Passaggi (parte 2) 👣· Interruzione: Ripassiamo (parte 2) 🌪️· App Web· Per quelli impazienti (codice)· Conclusioni· Riferimenti
Introduzione
Tutti noi dobbiamo leggere documenti eterni per ottenere due frasi contenenti il valore/informazione di cui abbiamo bisogno.
Hai mai desiderato di poter estrarre informazioni interessanti da un documento senza perdersi in un mare di parole?
Non cercare oltre! Benvenuto nel progetto “Parlare con i documenti utilizzando LLM”. È come recuperare tesori da file PDF, TXT o pagine web senza affaticare il cervello. E non preoccuparti, non hai bisogno di una laurea in magia tecnologica per divertirti. Abbiamo creato un’interfaccia user-friendly con Streamlit, quindi anche i tuoi amici non esperti di tecnologia, come gli assistenti di marketing, possono partecipare.
- Chat con documenti aziendali’ utilizzando Azure OpenAI
- Palla di cristallo della gestione dei dati del 2024 Top 4 tendenze emergenti
- I Migliori Corsi Gratuiti di Intelligenza Artificiale per Salvaguardare il Tuo Futuro Professionale
In questo articolo approfondiremo la teoria e il codice che sta dietro all’intelligenza dell’applicazione, facendo luce su come funzionano le applicazioni web. Per darti una panoramica veloce delle tecnologie che utilizzeremo, dai un’occhiata all’immagine seguente che mostra le quattro principali strumenti in azione.

E naturalmente, puoi trovare il codice nel mio repository GitHub, o se vuoi testare direttamente il codice, puoi andare alla sezione “Per i più impazienti (codice)”.
Come funziona
Diamo un’occhiata dietro al velo di “Parlare con i documenti utilizzando LLM”. Questo progetto è come un interessante duo: un lettore intelligente (back-end) e un sito web user-friendly (front-end).
- Lettore intelligente: Il cervello dell’IA legge e comprende i documenti come un amico super intelligente, gestendo in modo eccellente i PDF, i TXT e i contenuti web.
- Sito web user-friendly: Interfaccia web user-friendly per configurare e interagire con il modello. È composto da due pagine principali, ognuna con uno scopo specifico: Step 1️⃣ Creare il database e Step 2️⃣ Richiedere documenti.
La struttura del nostro progetto è simile a questa:
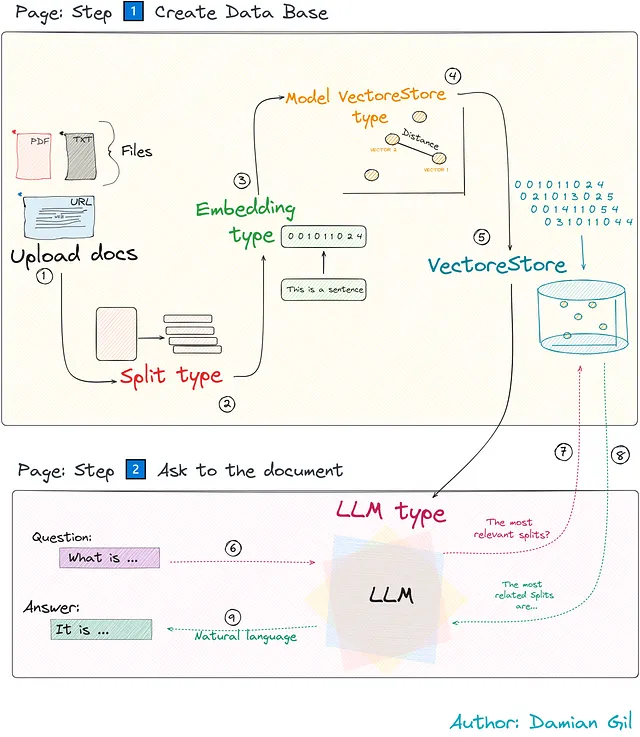
Anche se potrebbe sembrare complicato, semplificheremo ogni passaggio essenziale per renderlo funzionale. Concentrandoci sul funzionamento dell’intelligenza, scopriremo come funziona. Questi passaggi sono supportati dalla classe TalkDocument di Python e dimostreremo ogni passaggio con il codice corrispondente per dargli vita.
Passaggi (parte 1) 👣
Preparati ad esplorare ogni passo del percorso mentre scopriamo cosa rende magica la tecnologia dietro le quinte! 🚀🔍🎩
1- Importa documenti
Questo passaggio è ovvio, giusto? Qui decidi quale tipo di materiale fornire. Che si tratti di PDF, testo semplice, URL web o persino formato stringa grezza, è tutto nel menu.
# All'interno della funzione __init__, ho commentato le variabili# che al momento non ci interessano.def __init__(self, HF_API_TOKEN, data_source_path=None, data_text=None, OPENAI_KEY=None) -> None: # Puoi inserire il percorso del file. self.data_source_path = data_source_path # Puoi inserire direttamente il file in formato stringa self.data_text = data_text self.document = None # self.document_splited = None # self.embedding_model = None # self.embedding_type = None # self.OPENAI_KEY = OPENAI_KEY # self.HF_API_TOKEN = HF_API_TOKEN # self.db = None # self.llm = None # self.chain = None # self.repo_id = Nonedef get_document(self, data_source_type="TXT"):# DS_TYPE_LIST= ["WEB", "PDF", "TXT"] data_source_type = data_source_type if data_source_type.upper() in DS_TYPE_LIST else DS_TYPE_LIST[0] if data_source_type == "TXT": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.TextLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "PDF": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.PyPDFLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "WEB": loader = dl.WebBaseLoader(self.data_source_path) self.document = loader.load() return self.documentA seconda del tipo di file che carichi, il documento verrà letto da metodi diversi. Un miglioramento interessante potrebbe consistere nell’aggiunta del rilevamento automatico del formato.
2- Tipo di divisione
Ora, potresti chiederti perché esiste il termine “tipo”? Bene, nell’app puoi scegliere il metodo di divisione. Ma prima di approfondire questo argomento, spieghiamo cosa significa la divisione del documento.
Pensa a questo modo: proprio come gli esseri umani hanno bisogno di capitoli, paragrafi e frasi per strutturare le informazioni (immagina di leggere un libro con un paragrafo infinito – sì!), anche le macchine hanno bisogno di una struttura. Dobbiamo suddividere il documento in più parti più piccole per comprenderlo meglio. Questo parsing può essere fatto per carattere o per token.
# SPLIT_TYPE_LIST = ["CARATTERE", "TOKEN"]def get_split(self, split_type="carattere", chunk_size=200, chunk_overlap=10): split_type = split_type.upper() if split_type.upper() in SPLIT_TYPE_LIST else SPLIT_TYPE_LIST[0] if self.document: if split_type == "CARATTERE": text_splitter = ts.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) elif split_type == "TOKEN": text_splitter = ts.TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) # Se inserisci una stringa come documento, eseguiremo uno split_text. if self.data_text: try: self.document_splited = text_splitter.split_text(text=self.document) except Exception as error: print( error) # Se carichi un documento, effettueremo uno split_documents. elif self.data_source_path: try: self.document_splited = text_splitter.split_documents(documents=self.document) except Exception as error: print( error) return self.document_splited3- Tipo di incorporamento
Noi umani possiamo comprendere facilmente parole e immagini, ma le macchine hanno bisogno di un po’ più di guida. Questo diventa evidente quando:
- Stiamo cercando di convertire variabili categoriche in un set di dati in numeri
- Gestione delle immagini nelle reti neurali. Ad esempio, prima che un’immagine venga inserita in un modello di rete neurale, subisce trasformazioni per diventare un tensore numerico.
Come possiamo vedere, i modelli matematici hanno il linguaggio dei numeri. Questo fenomeno è anche osservato nel campo del NLP, dove viene promosso il concetto di word embedding.
In sostanza, ciò che facciamo in questo passaggio è convertire le divisioni della fase precedente (chunk del documento) in vettori numerici.
Questa conversione o codifica viene effettuata utilizzando algoritmi specializzati. È importante notare che questo processo converte le frasi in vettori digitali e che questa codifica non è casuale; segue un metodo strutturato.
Questo codice è molto semplice: istanziamo l’oggetto responsabile dell’integrazione. È importante notare che in questo punto stiamo solo creando un oggetto di integrazione. Nei passaggi successivi effettueremo la conversione effettiva.
def get_embedding(self, embedding_type="HF", OPENAI_KEY=None): if not self.embedding_model: embedding_type = embedding_type.upper() if embedding_type.upper() in EMBEDDING_TYPE_LIST else EMBEDDING_TYPE_LIST[0] # Se scegliamo di utilizzare il modello Hugging Face per l'embedding if embedding_type == "HF": self.embedding_model = embeddings.HuggingFaceEmbeddings() # Se optiamo per il modello OpenAI per l'embedding elif embedding_type == "OPENAI": self.OPENAI_KEY = self.OPENAI_KEY if self.OPENAI_KEY else OPENAI_KEY if self.OPENAI_KEY: self.embedding_model = embeddings.OpenAIEmbeddings(openai_api_key=OPENAI_KEY) else: print("È necessario inserire una OPENAI API KEY") # L'oggetto self.embedding_type = embedding_type return self.embedding_modelInterruzione: Ripassiamo (parte 1) 🌪️
Per comprendere i primi tre passaggi, consideriamo l’esempio seguente:
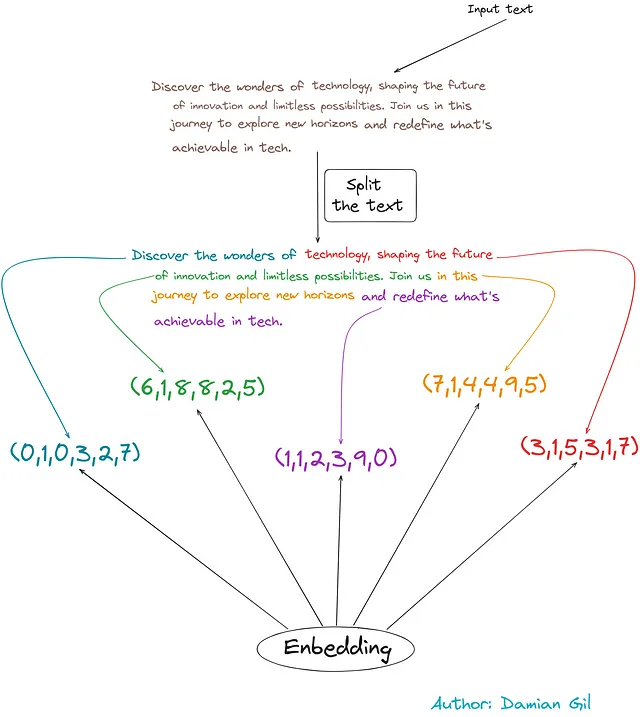
Iniziamo con un testo di input.
- Facciamo una distribuzione basata sul numero di caratteri (circa 50 caratteri in questo esempio).
- Facciamo integrazioni, trasformando frammenti di testo in vettori digitali.
Fantastico! 🚀 Ora iniziamo il viaggio emozionante attraverso i livelli rimanenti. Allacciate le cinture perché stiamo per sbloccare una vera magia tecnologica! 🔥🔓
Passaggi (parte 2) 👣
Continueremo a vedere i passaggi da seguire.
4- Tipo di Archivio Vettoriale del Modello
Ora che abbiamo trasformato il nostro testo in codice (embedded), abbiamo bisogno di un luogo in cui conservarlo. Qui entra in gioco il concetto di “archivio vettoriale”. È come una biblioteca intelligente di questi codici, che rende facile trovare e recuperare codici simili quando si pone una domanda.
Pensateci come a uno spazio di archiviazione ordinato che vi permette di tornare rapidamente a ciò di cui avete bisogno!
La creazione di questo tipo di database è gestita da algoritmi specializzati progettati per questo scopo, come FAISS (Facebook AI Similarity Search). Ci sono anche altre opzioni, e attualmente questa classe supporta CHROMA e SVM.
Questo passaggio e il passaggio successivo condividono del codice. In questo passaggio, si sceglie il tipo di archivio vettoriale che si desidera creare, mentre il passaggio successivo è dove avviene la creazione effettiva.
5. Creazione del Modello VectoreStore
Questo tipo di database gestisce due aspetti principali:
- Archiviazione vettoriale: Conserva i vettori generati dall’integrazione.
- Calcolo della similarità: Calcola la similarità tra i vettori.
Ma cos’è esattamente la similarità tra questi vettori e perché è importante?
Bene, ricordate che ho menzionato che l’integrazione non è casuale? È progettata in modo che parole o frasi con significati simili abbiano vettori simili. In questo modo possiamo calcolare la distanza tra i vettori (come utilizzare la distanza euclidea) e questo ci fornisce una misura della loro “similitudine”.
Per visualizzare questo con un esempio, immaginiamo di avere tre frasi.
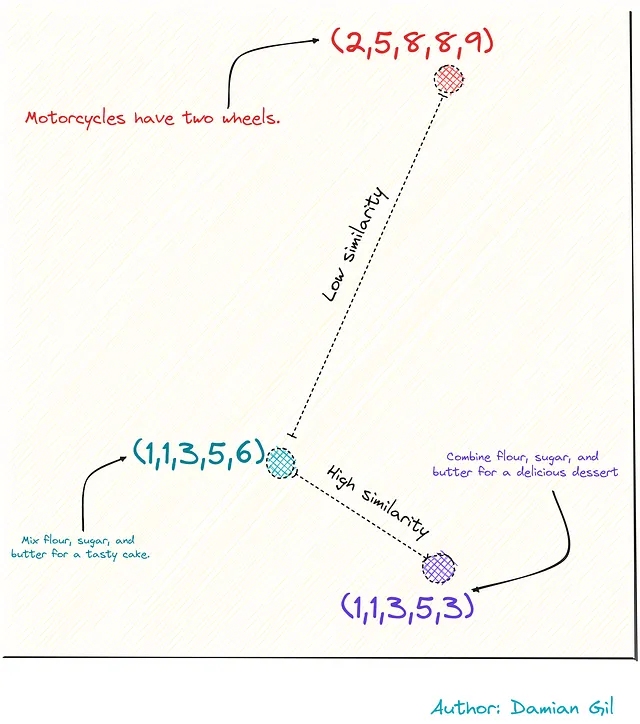
Due sono legate alle ricette, mentre la terza è legata alle motociclette. Rappresentandole come vettori (grazie all’integrazione), possiamo calcolare la distanza tra questi punti o frasi. Questa distanza serve come misura della loro similarità.
In termini di codice, diamo uno sguardo ai requisiti richiesti:
- Il testo diviso
- Il tipo di embedding
- Il modello di archiviazione dei vettori
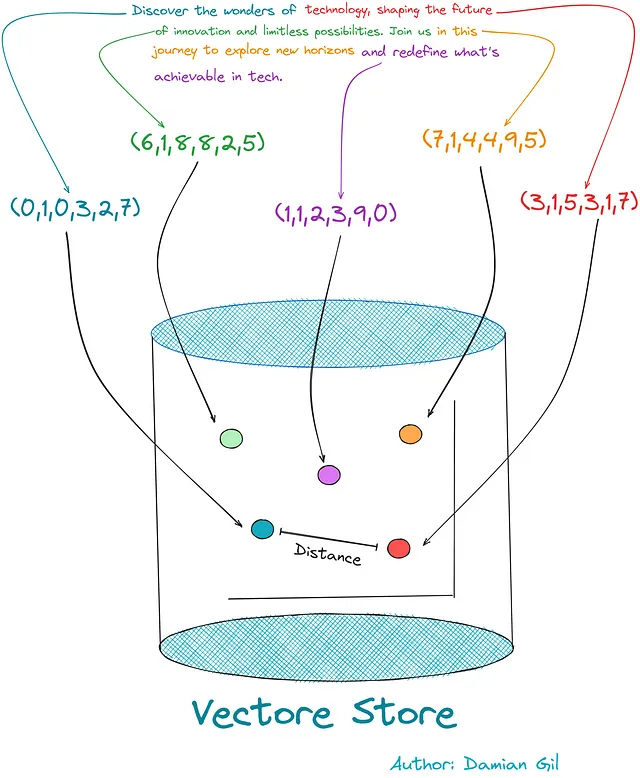
# VECTORSTORE_TYPE_LIST = ["FAISS", "CHROMA", "SVM"]def get_storage(self, vectorstore_type = "FAISS", embedding_type="HF", OPENAI_KEY=None): self.embedding_type = self.embedding_type if self.embedding_type else embedding_type vectorstore_type = vectorstore_type.upper() if vectorstore_type.upper() in VECTORSTORE_TYPE_LIST else VECTORSTORE_TYPE_LIST[0] # Qui effettuiamo la chiamata all'algoritmo # che ha eseguito l'embedding e creiamo l'oggetto self.get_embedding(embedding_type=self.embedding_type, OPENAI_KEY=OPENAI_KEY) # Qui scegliamo il tipo di archiviazione dei vettori che vogliamo utilizzare if vectorstore_type == "FAISS": model_vectorstore = vs.FAISS elif vectorstore_type == "CHROMA": model_vectorstore = vs.Chroma elif vectorstore_type == "SVM": model_vectorstore = retrievers.SVMRetriever # Qui creiamo l'archivio dei vettori. In questo caso, # il documento proviene da testo grezzo. if self.data_text: try: self.db = model_vectorstore.from_texts(self.document_splited, self.embedding_model) except Exception as error: print( error) # Qui creiamo l'archivio dei vettori. In questo caso, # il documento proviene da un documento come pdf txt... elif self.data_source_path: try: self.db = model_vectorstore.from_documents(self.document_splited, self.embedding_model) except Exception as error: print( error) return self.dbPer illustrare cosa accade in questa fase, possiamo visualizzare l’immagine seguente. Mostra come i frammenti di testo codificati vengono memorizzati nell’archivio dei vettori, consentendoci di calcolare la distanza/similarità tra vettori/punti.
Interruzione: Riepiloghiamo (parte 2) 🌪️
Ottimo! Ora abbiamo un database in grado di archiviare i nostri documenti e calcolare la similarità tra frammenti di testo criptati. Immagina una situazione in cui vogliamo codificare una frase esterna e archiviarla nel nostro archivio di vettori. Questo ci permetterà di calcolare la distanza tra il nuovo vettore e il documento diviso. (Nota che qui dovrebbe essere utilizzata la stessa integrazione per creare l’archivio di vettori.) Possiamo visualizzare ciò attraverso l’immagine seguente.
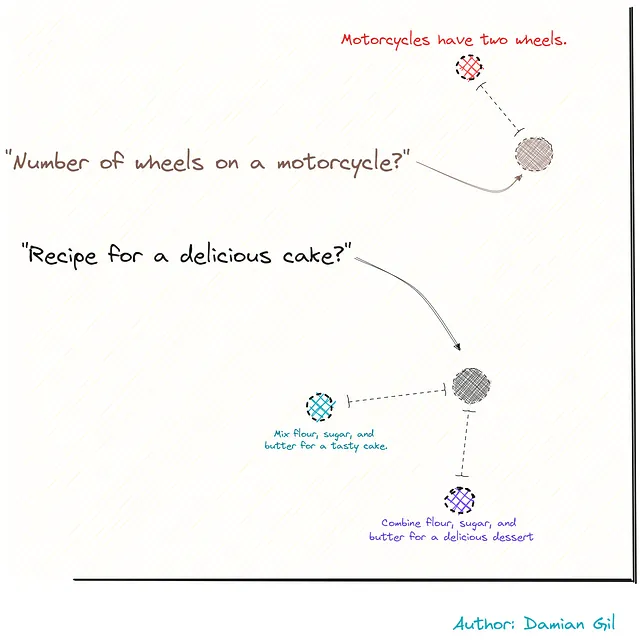
Ricorda l’immagine precedente… abbiamo due domande e le trasformiamo in numeri usando l’integrazione. Poi misuriamo la distanza e troviamo le frasi più vicine alla nostra domanda. Queste frasi sono come combinazioni perfette! È come trovare il miglior pezzo di puzzle in un istante! 🚀🧩🔍
6- Domanda
Ricorda che il nostro obiettivo è fare una domanda su un documento e ottenere una risposta. In questa fase, raccogliamo le domande come input fornito dall’utente.
7 & 8- Divisioni Rilevanti
È qui che inseriamo la nostra domanda nel repository di vettori, incorporandola per trasformare la frase in un vettore digitale. Poi calcoliamo la distanza tra la nostra domanda e le parti del documento, determinando quali parti sono più vicine alla nostra domanda. Il codice è:
# A seconda del tipo di repository di vettori che abbiamo costruito,# useremo una specifica funzione. Tutte restituiscono# una lista delle divisioni più rilevanti.def get_search(self, domanda, with_score=False): documenti_rilevanti = None if self.db and "SVM" not in str(type(self.db)): if with_score: documenti_rilevanti = self.db.similarity_search_with_relevance_scores(domanda) else: documenti_rilevanti = self.db.similarity_search(domanda) elif self.db: documenti_rilevanti = self.db.get_relevant_documents(domanda) return documenti_rilevantiProvalo con il codice qui sotto. Impara come rispondere come una lista di 4 elementi. E quando guardiamo all’interno, in realtà sono parti separate del documento che hai inserito. È come l’app che ti presenta i migliori 4 pezzi di puzzle che si adattano alla tua domanda come un guanto! 🧩💬
9- Risposta (Linguaggio Naturale)
Ottimo, ora abbiamo il testo più rilevante per la nostra domanda. Ma non possiamo semplicemente consegnare queste parti all’utente e terminare. Abbiamo bisogno di una risposta concisa e precisa alla loro domanda. Ed è qui che entra in gioco il nostro Modello Linguistico Intelligente (LLM)! Ci sono molti gusti di LLM. Nel codice, impostiamo “flan-alpaca-large” come predefinito. Non esitare a scegliere la persona che ti ha colpito di più! 🚀🎉
Ecco il piano:
- Ripristiniamo le parti più importanti (divisioni) relative alla domanda.
- Prepariamo un prompt che include la domanda, come vogliamo la risposta e quegli elementi di testo.
- Passiamo questo prompt al nostro Modello Linguistico Intelligente (LLM). Conosce la domanda e le informazioni contenute in questi elementi e ci fornisce risposte naturali.️
Questa ultima parte è mostrata nell’immagine seguente: 🖼️
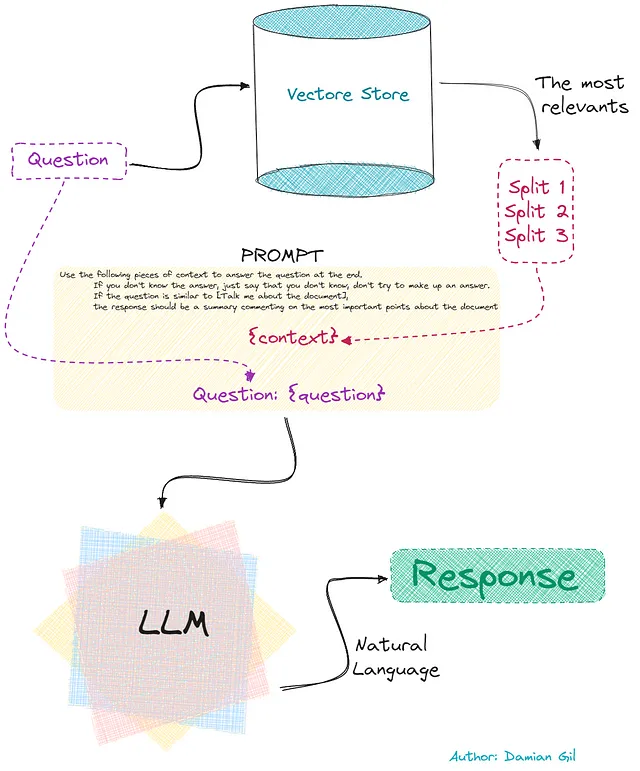
Effettivamente, questo flusso esatto viene eseguito nel codice. Noterai nel codice che c’è un passaggio aggiuntivo nel creare un “prompt”. Infatti, possiamo ottenere una risposta finale che è una combinazione delle risposte trovate dal LLM e altre scelte. Per semplicità, facciamolo nel modo più semplice: “stuff”. Questo significa che la risposta è la prima soluzione trovata dal LLM. Qui, non ti perdi nella teoria! 🌟
def do_question(self, domanda, repo_id="declare-lab/flan-alpaca-large", chain_type="stuff", documenti_rilevanti=None, with_score=False, temperature=0, max_length=300): # Otteniamo le divisioni più rilevanti. documenti_rilevanti = self.get_search(domanda, with_score=with_score) # Definiamo il LLM che vogliamo utilizzare, # dobbiamo introdurre l'id del repository poiché stiamo usando huggingface. self.repo_id = self.repo_id if self.repo_id is not None else repo_id chain_type = chain_type.lower() if chain_type.lower() in CHAIN_TYPE_LIST else CHAIN_TYPE_LIST[0] # Questo controllo è necessario poiché possiamo chiamare la funzione più volte, # ma non avrebbe senso creare un LLM ogni volta che viene effettuata la chiamata. # Quindi controlla se esiste già un llm all'interno della classe # o se l'id del repo (il tipo di llm) è cambiato. if (self.repo_id != repo_id ) or (self.llm is None): self.repo_id = repo_id # Creiamo il LLM. self.llm = HuggingFaceHub(repo_id=self.repo_id,huggingfacehub_api_token=self.HF_API_TOKEN, model_kwargs= {"temperature":temperature, "max_length": max_length}) # Creiamo il prompt prompt_template = """Utilizza i seguenti elementi di contesto per rispondere alla domanda alla fine. Se non conosci la risposta, di' semplicemente che non lo sai, non cercare di inventare una risposta. Se la domanda è simile a [Parlami del documento], la risposta dovrebbe essere un riassunto che commenta i punti più importanti sul documento {context} Domanda: {domanda} """ PROMPT = PromptTemplate( template=prompt_template, input_variables=["context", "domanda"] ) # Creiamo la catena, chain_type= "stuff". self.chain = self.chain if self.chain is not None else load_qa_chain(self.llm, chain_type=chain_type, prompt = PROMPT) # Facciamo la query al LLM utilizzando il prompt # Controlliamo se esiste già una catena definita, # se non esiste viene creata risposta = self.chain({"input_documents": documenti_rilevanti, "question": domanda}, return_only_outputs=True) return rispostaHai raggiunto l’obiettivo, hai capito come funziona il cervello della nostra web app. Dai un high-five se sei qui! Ora, immergiamoci nell’ultima parte dell’articolo, dove esploreremo le pagine dell’app web. 🎉🕵️♂️
App Web
Questa interfaccia è progettata per le persone senza conoscenze tecniche, in modo che tu possa sfruttare al massimo questa tecnologia senza problemi. 🚀👩💻
Usare il sito è estremamente semplice e potente. Fondamentalmente, l’utente deve solo fornire il documento. Se non sei pronto a beneficiare di parametri aggiuntivi, nel passaggio successivo potresti già iniziare a fare domande. 🌟🤖
Vediamo i passaggi da seguire:
- Fornisci il documento o il link web. Nella pagina Passaggio 1️⃣ Crea il Database.
- Configura la configurazione (opzionale). Nella pagina Passaggio 1️⃣ Crea il Database.
- Fai le tue domande e ottieni le risposte! 📚🔍🚀 Nella pagina Passaggio 2️⃣ Chiedi al documento.
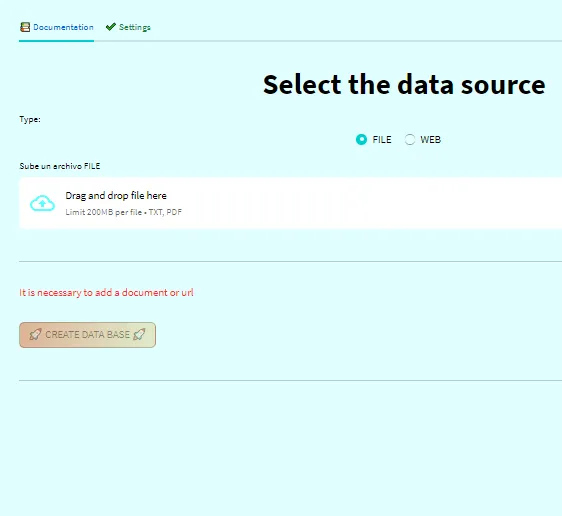
1. Fornisci il documento o il link web.
In questo passaggio, aggiungi il documento caricandolo sul web. Ricorda che se non hai la chiave API di Face Hugging come variabile d’ambiente, la scheda “home” ti chiederà di inserirla. 📂🔑
Una volta allegato il documento e configurato le tue preferenze, verrà visualizzata una tabella di riepilogo della tua configurazione. Il pulsante “Crea Database” verrà quindi sbloccato. Quando fai clic sul pulsante, verrà creato il database o il negozio di vettori, e verrai reindirizzato alla sezione delle domande. 📑🔒🚀
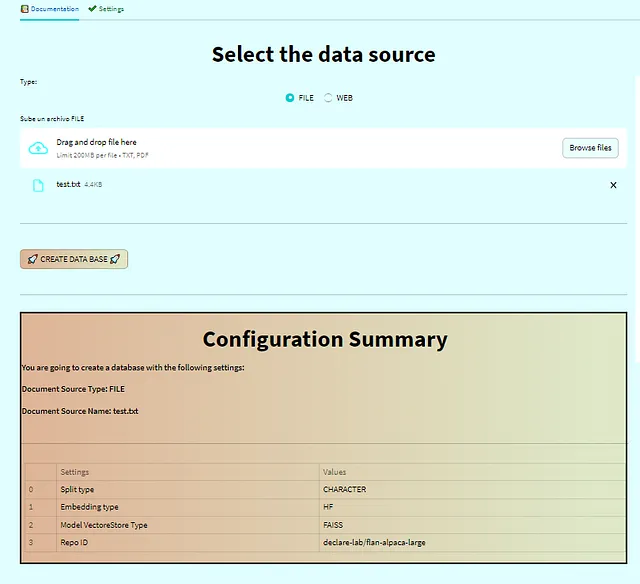
2. Configura la configurazione (opzionale).
Come ho già detto, possiamo configurare il negozio di vettori secondo le nostre preferenze. Ci sono diversi metodi per suddividere i documenti, incorporarli e altro ancora. Questa scheda ti permette di personalizzarla come preferisci. Viene fornita una configurazione predefinita per un setup più rapido. ⚙️🛠️
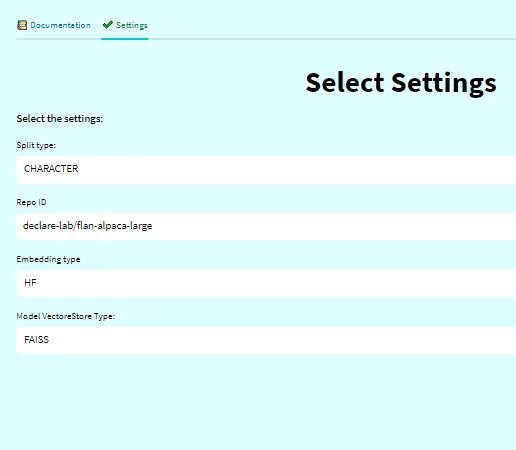
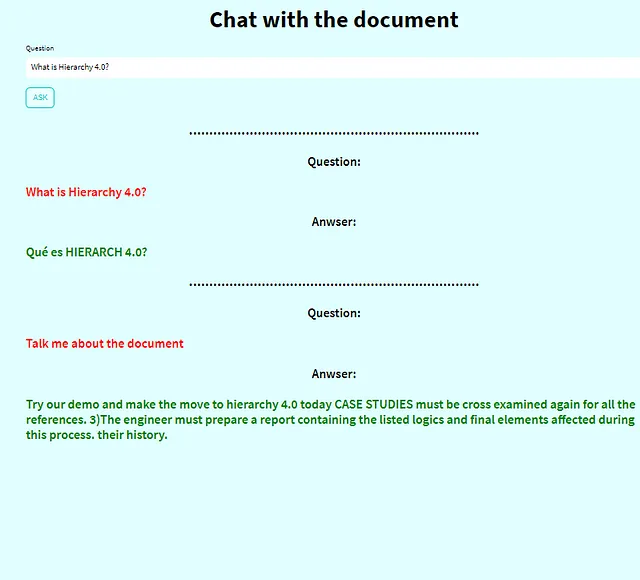
3. Fai le tue domande e ottieni le risposte!
A questo punto, puoi iniziare a fare tutte le domande che vuoi. Ora è il momento di divertirti e interagire con lo strumento quanto vuoi! 🤗🔍💬
Per quelli impazienti (codice)
Per coloro che sono ansiosi di immergersi, è possibile prendere direttamente la classe TalkDocument e incollarla in un notebook Jupyter per iniziare a sperimentare. Potrebbe essere necessario installare alcune dipendenze, ma sono sicuro che non sarà una sfida per voi. Buon divertimento nell’esplorare e sperimentare! Buon coding!! 🚀📚😄
La classe TalkDocument nel codice da eseguire (Codice dell’autore)
Conclusioni
Congratulazioni per essere arrivati così lontano nel nostro entusiasmante viaggio! Abbiamo approfondito come funziona l’intelligenza dietro questa applicazione web. Dall’upload dei documenti al ottenimento delle risposte, avete coperto molta strada! Se vi sentite ispirati, il codice è disponibile nel mio repository GitHub. Sentitevi liberi di collaborare e contattarmi su LinkedIn per qualsiasi domanda o suggerimento! Divertitevi ad esplorare e sperimentare con questo potente strumento!
Se volete, potete controllare il mio GitHub
damiangilgonzalez1995 – Panoramica
Appassionato di dati, sono passato dalla fisica alla scienza dei dati. Ho lavorato presso Telefonica, HP e ora sono CTO presso…
github.com
Riferimenti
- Documentazione di Langchain
- Documentazione di Hugging Face
- Introduzione a Facebook AI Similarity Search (Faiss)
- Documentazione di Streamlit





