Implementazione dei modelli di visione TensorFlow in Hugging Face con TF Serving
'Implementazione modelli visione TensorFlow in Hugging Face con TF Serving'
![]()
Negli ultimi mesi, il team di Hugging Face e i contributori esterni hanno aggiunto una varietà di modelli di visione in TensorFlow a Transformers. Questa lista sta crescendo in modo completo e include già modelli pre-addestrati all’avanguardia come Vision Transformer, Masked Autoencoders, RegNet, ConvNeXt e molti altri!
Quando si tratta di distribuire modelli TensorFlow, ci sono diverse opzioni. A seconda del caso d’uso, potresti voler esporre il tuo modello come endpoint o includerlo direttamente in un’applicazione. TensorFlow fornisce strumenti che coprono ognuno di questi diversi scenari.
In questo post, vedrai come distribuire un modello Vision Transformer (ViT) (per la classificazione delle immagini) localmente utilizzando TensorFlow Serving (TF Serving). Ciò permetterà agli sviluppatori di esporre il modello come endpoint REST o gRPC. Inoltre, TF Serving supporta molte funzionalità specifiche per la distribuzione, come il riscaldamento del modello, il batching lato server, ecc.
- Introduzione alla nuova documentazione audio e video in 🤗 Datasets
- Commenti sul Rapporto Provvisorio sulla Risorsa Nazionale di Ricerca sull’IA degli Stati Uniti
- Nyströmformer Approssimare l’auto-attenzione in tempo lineare e memoria mediante il metodo di Nyström
Per ottenere il codice completo mostrato in questo post, consulta il Notebook Colab mostrato all’inizio.
Tutti i modelli TensorFlow in 🤗 Transformers hanno un metodo chiamato save_pretrained(). Con questo metodo, puoi serializzare i pesi del modello nel formato h5 così come nel formato SavedModel autonomo. TF Serving richiede che il modello sia presente nel formato SavedModel. Quindi, carichiamo prima un modello Vision Transformer e lo salviamo:
from transformers import TFViTForImageClassification
temp_model_dir = "vit"
ckpt = "google/vit-base-patch16-224"
model = TFViTForImageClassification.from_pretrained(ckpt)
model.save_pretrained(temp_model_dir, saved_model=True)Per impostazione predefinita, save_pretrained() creerà prima una directory di versione all’interno del percorso che gli forniamo. Quindi, il percorso diventa: {temp_model_dir}/saved_model/{version}.
Possiamo ispezionare la firma di servizio del SavedModel in questo modo:
saved_model_cli show --dir {temp_model_dir}/saved_model/1 --tag_set serve --signature_def serving_defaultQuesto dovrebbe produrre l’output:
Il SavedModel SignatureDef fornito contiene i seguenti input:
inputs['pixel_values'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, -1, -1)
name: serving_default_pixel_values:0
Il SavedModel SignatureDef fornito contiene i seguenti output:
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1000)
name: StatefulPartitionedCall:0
Il nome del metodo è: tensorflow/serving/predictCome si può notare, il modello accetta input singoli 4-d (chiamati pixel_values) che hanno gli assi seguenti: (batch_size, num_channels, height, width). Per questo modello, l’altezza e la larghezza accettabili sono impostate su 224, e il numero di canali è 3. Puoi verificare ciò ispezionando l’argomento config del modello (model.config). Il modello restituisce un vettore di 1000 dimensioni di logits.
Di solito, ogni modello di ML ha determinati passaggi di pre-elaborazione e post-elaborazione. Anche il modello ViT non fa eccezione. I principali passaggi di pre-elaborazione includono:
-
Scala i valori dei pixel dell’immagine nell’intervallo [0, 1].
-
Normalizza i valori dei pixel scalati nell’intervallo [-1, 1].
-
Ridimensiona l’immagine in modo che abbia una risoluzione spaziale di (224, 224).
Puoi confermare tutto ciò indagando l’estrattore di feature associato al modello:
from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained(ckpt)
print(feature_extractor)Questo dovrebbe stampare:
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}Dato che si tratta di un modello di classificazione delle immagini pre-addestrato sul dataset ImageNet-1k, i risultati del modello devono essere mappati alle classi di ImageNet-1k come passaggio di post-elaborazione.
Per ridurre il carico cognitivo degli sviluppatori e l’errore dovuto all’addestramento, è spesso una buona idea fornire un modello che includa la maggior parte delle operazioni di preprocessing e postprocessing. Pertanto, è necessario serializzare il modello come SavedModel in modo che le operazioni di elaborazione sopra menzionate vengano incorporate nel suo grafo di calcolo.
Preelaborazione
Per la preelaborazione, la normalizzazione dell’immagine è uno dei componenti più essenziali:
def normalize_img(
img, mean=feature_extractor.image_mean, std=feature_extractor.image_std
):
# Ridimensiona nell'intervallo di valori [0, 1] e quindi normalizza.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / stdÈ anche necessario ridimensionare l’immagine e trasporla in modo che abbia le dimensioni del canale principale seguendo il formato standard di 🤗 Transformers. Il frammento di codice sottostante mostra tutte le fasi di preelaborazione:
CONCRETE_INPUT = "pixel_values" # Che è ciò che abbiamo indagato tramite SavedModel CLI.
SIZE = feature_extractor.size
def normalize_img(
img, mean=feature_extractor.image_mean, std=feature_extractor.image_std
):
# Ridimensiona nell'intervallo di valori [0, 1] e quindi normalizza.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
def preprocess(string_input):
decoded_input = tf.io.decode_base64(string_input)
decoded = tf.io.decode_jpeg(decoded_input, channels=3)
resized = tf.image.resize(decoded, size=(SIZE, SIZE))
normalized = normalize_img(resized)
normalized = tf.transpose(
normalized, (2, 0, 1)
) # Poiché i modelli HF sono orientati ai canali.
return normalized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(string_input):
decoded_images = tf.map_fn(
preprocess, string_input, dtype=tf.float32, back_prop=False
)
return {CONCRETE_INPUT: decoded_images}Nota per far sì che il modello accetti input di stringhe :
Quando si lavora con immagini tramite richieste REST o gRPC, la dimensione del payload della richiesta può facilmente aumentare a seconda della risoluzione delle immagini trasmesse. Per questo motivo, è una buona pratica comprimerle in modo affidabile e quindi preparare il payload della richiesta.
Postelaborazione ed esportazione del modello
Ora disponi delle operazioni di preelaborazione che puoi inserire nel grafo di calcolo esistente del modello. In questa sezione, inserirai anche le operazioni di postelaborazione nel grafo ed esporterai il modello!
def model_exporter(model: tf.keras.Model):
m_call = tf.function(model.call).get_concrete_function(
tf.TensorSpec(
shape=[None, 3, SIZE, SIZE], dtype=tf.float32, name=CONCRETE_INPUT
)
)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(string_input):
labels = tf.constant(list(model.config.id2label.values()), dtype=tf.string)
images = preprocess_fn(string_input)
predictions = m_call(**images)
indices = tf.argmax(predictions.logits, axis=1)
pred_source = tf.gather(params=labels, indices=indices)
probs = tf.nn.softmax(predictions.logits, axis=1)
pred_confidence = tf.reduce_max(probs, axis=1)
return {"label": pred_source, "confidence": pred_confidence}
return serving_fnPuoi prima ottenere la funzione concreta dal metodo di passaggio in avanti del modello ( call() ) in modo che il modello sia compilato in un grafo. Dopo di che, puoi applicare i seguenti passaggi nell’ordine:
-
Passa gli input attraverso le operazioni di preelaborazione.
-
Passa gli input di preelaborazione tramite la funzione concreta derivata.
-
Postelabora gli output e restituiscili in un dizionario formattato in modo chiaro.
Ora è il momento di esportare il modello!
MODEL_DIR = tempfile.gettempdir()
VERSION = 1
tf.saved_model.save(
model,
os.path.join(MODEL_DIR, str(VERSION)),
signatures={"serving_default": model_exporter(model)},
)
os.environ["MODEL_DIR"] = MODEL_DIRDopo l’esportazione, esaminiamo nuovamente le firme del modello:
saved_model_cli show --dir {MODEL_DIR}/1 --tag_set serve --signature_def serving_default
Il SignatureDef SavedModel fornito contiene i seguenti input:
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
Il SignatureDef SavedModel fornito contiene i seguenti output:
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Il nome del metodo è: tensorflow/serving/predictPuoi notare che la firma del modello è cambiata. In particolare, il tipo di input è ora una stringa e il modello restituisce due cose: un punteggio di confidenza e l’etichetta in formato stringa.
Se hai già installato TF Serving (come spiegato nel Notebook di Colab), sei pronto per distribuire questo modello!
È sufficiente un singolo comando per farlo:
nohup tensorflow_model_server \
--rest_api_port=8501 \
--model_name=vit \
--model_base_path=$MODEL_DIR >server.log 2>&1Dal comando sopra, i parametri importanti sono:
-
rest_api_portindica il numero di porta che TF Serving utilizzerà per distribuire il punto di accesso REST del tuo modello. Per impostazione predefinita, TF Serving utilizza la porta 8500 per il punto di accesso gRPC. -
model_namespecifica il nome del modello (può essere qualsiasi cosa) che verrà utilizzato per chiamare le API. -
model_base_pathindica il percorso di base del modello che TF Serving utilizzerà per caricare l’ultima versione del modello.
(La lista completa dei parametri supportati è qui .)
E voilà! In pochi minuti, dovresti essere operativo con un modello distribuito che ha due endpoint – REST e gRPC.
Ricorda che hai esportato il modello in modo che accetti input di stringa codificati con il formato base64 . Quindi, per creare il payload della richiesta, puoi fare qualcosa del genere:
# Ottieni un'immagine di un gatto carino.
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
# Leggi l'immagine dal disco come byte grezzi e quindi codificala.
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
# Crea il payload della richiesta.
data = json.dumps({"signature_name": "serving_default", "instances": [b64str]})La specifica del formato del payload della richiesta di TF Serving per il punto di accesso REST è disponibile qui . All’interno degli instances puoi passare più immagini codificate. Questo tipo di endpoint è destinato a essere utilizzato per scenari di previsione online. Per input con più di un singolo punto dati, è consigliabile abilitare l’elaborazione a batch per ottenere vantaggi di ottimizzazione delle prestazioni.
Ora puoi chiamare l’API:
headers = {"content-type": "application/json"}
json_response = requests.post(
"http://localhost:8501/v1/models/vit:predict", data=data, headers=headers
)
print(json.loads(json_response.text))
# {'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}Il punto di accesso REST è – http://localhost:8501/v1/models/vit:predict seguendo la specifica da qui . Per impostazione predefinita, viene sempre utilizzata l’ultima versione del modello. Ma se desideri una versione specifica, puoi fare: http://localhost:8501/v1/models/vit/versions/1:predict .
Sebbene REST sia molto popolare nel mondo delle API, molte applicazioni spesso traggono vantaggio da gRPC. Questo post fa un buon lavoro nel confrontare i due modi di distribuzione. gRPC è di solito preferito per sistemi a bassa latenza, altamente scalabili e distribuiti.
Ci sono un paio di passaggi da seguire. Prima, è necessario aprire un canale di comunicazione:
import grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)Quindi, crea il payload della richiesta:
request = predict_pb2.PredictRequest()
request.model_spec.name = "vit"
request.model_spec.signature_name = "serving_default"
request.inputs[serving_input].CopyFrom(tf.make_tensor_proto([b64str]))Puoi determinare la chiave serving_input in modo programmato nel seguente modo:
loaded = tf.saved_model.load(f"{MODEL_DIR}/{VERSION}")
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Input della funzione di servizio:", serving_input)
# Input della funzione di servizio: string_inputOra, puoi ottenere alcune previsioni:
grpc_predictions = stub.Predict(request, 10.0) # timeout di 10 secondi
print(grpc_predictions)
outputs {
key: "confidence"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
}
float_val: 0.8966591954231262
}
}
outputs {
key: "label"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
}
string_val: "Gatto egiziano"
}
}
model_spec {
name: "resnet"
version {
value: 1
}
signature_name: "serving_default"
}Puoi anche ottenere le coppie chiave-valore di nostro interesse dai risultati precedenti nel seguente modo:
grpc_predictions.outputs["label"].string_val, grpc_predictions.outputs[
"confidence"
].float_val
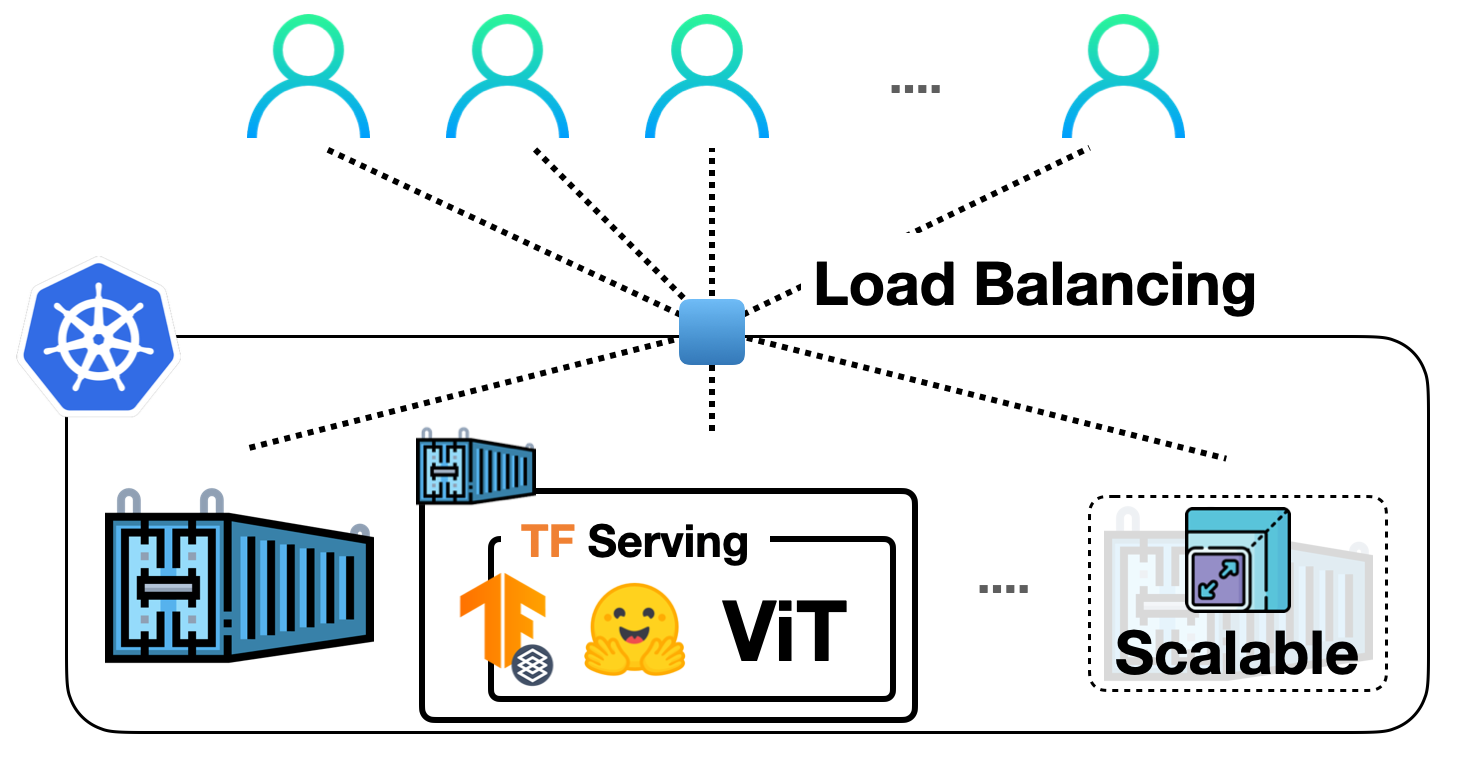
# ([b'Gatto egiziano'], [0.8966591954231262])In questo post, abbiamo imparato come distribuire un modello di visione TensorFlow da Transformers con TF Serving. Se le distribuzioni locali sono ottime per i progetti del fine settimana, vorremmo essere in grado di scalare queste distribuzioni per servire molti utenti. Nella prossima serie di post, vedrai come scalare queste distribuzioni con Kubernetes e Vertex AI.
-
gRPC
-
Apprendimento automatico pratico per la visione artificiale
-
Modelli TensorFlow più veloci in Hugging Face Transformers