‘Il Riformatore – Spingendo i limiti del modellamento del linguaggio’
Il Riformatore - Pushing the limits of language modeling.
![]()
Come il Reformer utilizza meno di 8GB di RAM per addestrare su sequenze di mezzo milione di token
Il modello Reformer, come introdotto da Kitaev, Kaiser et al. (2020), è uno dei modelli di trasformazione più efficienti in termini di memoria per la modellazione di sequenze lunghe fino ad oggi.
Recentemente, la modellazione di sequenze lunghe ha suscitato un grande interesse, come si può vedere dai numerosi contributi solo di quest’anno – Beltagy et al. (2020), Roy et al. (2020), Tay et al., Wang et al., solo per citarne alcuni. La motivazione alla base della modellazione di sequenze lunghe è che molte attività di NLP, come la sintesi, la risposta alle domande, richiedono al modello di elaborare sequenze di input più lunghe di quelle che i modelli, come BERT, sono in grado di gestire. Nei compiti che richiedono al modello di elaborare una sequenza di input molto grande, i modelli di sequenze lunghe non devono tagliare la sequenza di input per evitare un overflow di memoria e quindi sono stati dimostrati essere più performanti rispetto ai modelli standard simili a “BERT” cf. Beltagy et al. (2020).
Il Reformer spinge al limite la modellazione di sequenze lunghe grazie alla sua capacità di elaborare fino a mezzo milione di token contemporaneamente, come mostrato in questa demo. A titolo di confronto, un modello convenzionale bert-base-uncased limita la lunghezza dell’input a soli 512 token. Nel Reformer, ogni parte dell’architettura standard del trasformatore è riprogettata per ottimizzare il requisito di memoria minima senza una significativa riduzione delle prestazioni.
- ‘Distribuisci facilmente i modelli di Hugging Face con Amazon SageMaker’
- ‘Deep Learning su Internet Allenamento collaborativo dei modelli di linguaggio’
- ‘Apprendimento attivo con AutoNLP e Prodigy’
I miglioramenti della memoria possono essere attribuiti a 4 caratteristiche introdotte dagli autori del Reformer nel mondo dei trasformatori:
- Layer di auto-attenzione del Reformer – Come implementare efficientemente l’auto-attenzione senza essere limitati a un contesto locale?
- Strati di feed forward segmentati – Come ottenere un migliore rapporto tempo-memoria per strati di feed forward di grandi dimensioni?
- Strati di residui reversibili – Come ridurre drasticamente il consumo di memoria nell’addestramento tramite un’architettura di residui intelligente?
- Codifiche posizionali assiali – Come rendere utilizzabili le codifiche posizionali per sequenze di input estremamente grandi?
Lo scopo di questo post del blog è fornire al lettore una comprensione approfondita di ciascuna delle quattro caratteristiche del Reformer menzionate in precedenza. Sebbene le spiegazioni siano incentrate sul Reformer, il lettore dovrebbe avere una migliore intuizione sulle circostanze in cui ciascuna delle quattro caratteristiche può essere efficace anche per altri modelli di trasformatori. Le quattro sezioni sono solo vagamente connesse, quindi possono essere lette anche individualmente.
Il Reformer fa parte della libreria 🤗Transformers. Per tutti gli utenti del Reformer, si consiglia di leggere questo post del blog molto dettagliato per comprendere meglio come funziona il modello e come impostare correttamente la sua configurazione. Tutte le equazioni sono accompagnate dal loro nome equivalente per la configurazione del Reformer, ad esempio config.<param_name>, in modo che il lettore possa fare rapidamente riferimento alla documentazione ufficiale e al file di configurazione.
Nota: le codifiche posizionali assiali non sono spiegate nel paper ufficiale del Reformer, ma vengono ampiamente utilizzate nel codice ufficiale. Questo post del blog fornisce la prima spiegazione approfondita delle codifiche posizionali assiali.
1. Layer di auto-attenzione del Reformer
Il Reformer utilizza due tipi di layer di auto-attenzione speciali: layer di auto-attenzione locale e layer di auto-attenzione con Locality Sensitive Hashing (LSH).
Per introdurre meglio questi nuovi layer di auto-attenzione, faremo un breve ripasso dell’auto-attenzione convenzionale come introdotto da Vaswani et al. (2017).
Questo post del blog utilizza la stessa notazione e colorazione del popolare post del blog The illustrated transformer, quindi si consiglia vivamente al lettore di leggere prima questo post del blog.
Importante: anche se il Reformer è stato originariamente introdotto per l’auto-attenzione causale, può essere utilizzato anche per l’auto-attenzione bidirezionale. In questo post, l’auto-attenzione del Reformer viene presentata per l’auto-attenzione bidirezionale.
Ripasso dell’Auto-attenzione Globale
Il nucleo di ogni modello Transformer è il layer di auto-attenzione. Per ripassare il layer di auto-attenzione convenzionale, che qui chiamiamo auto-attenzione globale, supponiamo di applicare un layer del trasformatore al vettore di embedding sequenziale X = x 1 , … , x n \mathbf{X} = \mathbf{x}_1, \ldots, \mathbf{x}_n X = x 1 , … , x n dove ogni vettore x i \mathbf{x}_{i} x i ha dimensione config.hidden_size, cioè d h d_h d h .
In breve, uno strato di self-attention globale proietta X \mathbf{X} X alle matrici di query, chiave e valore Q , K , V \mathbf{Q}, \mathbf{K}, \mathbf{V} Q , K , V e calcola l’output Z \mathbf{Z} Z utilizzando l’operazione softmax come segue: Z = SelfAttn ( X ) = softmax ( Q K T ) V \mathbf{Z} = \text{SelfAttn}(\mathbf{X}) = \text{softmax}(\mathbf{Q}\mathbf{K}^T) \mathbf{V} Z = SelfAttn ( X ) = softmax ( Q K T ) V con Z \mathbf{Z} Z di dimensione d h × n d_h \times n d h × n (trascurando il fattore di normalizzazione delle chiavi e i pesi di self-attention W O \mathbf{W}^{O} W O per semplicità). Per ulteriori dettagli sull’operazione completa del transformer, consulta il transformer illustrato.
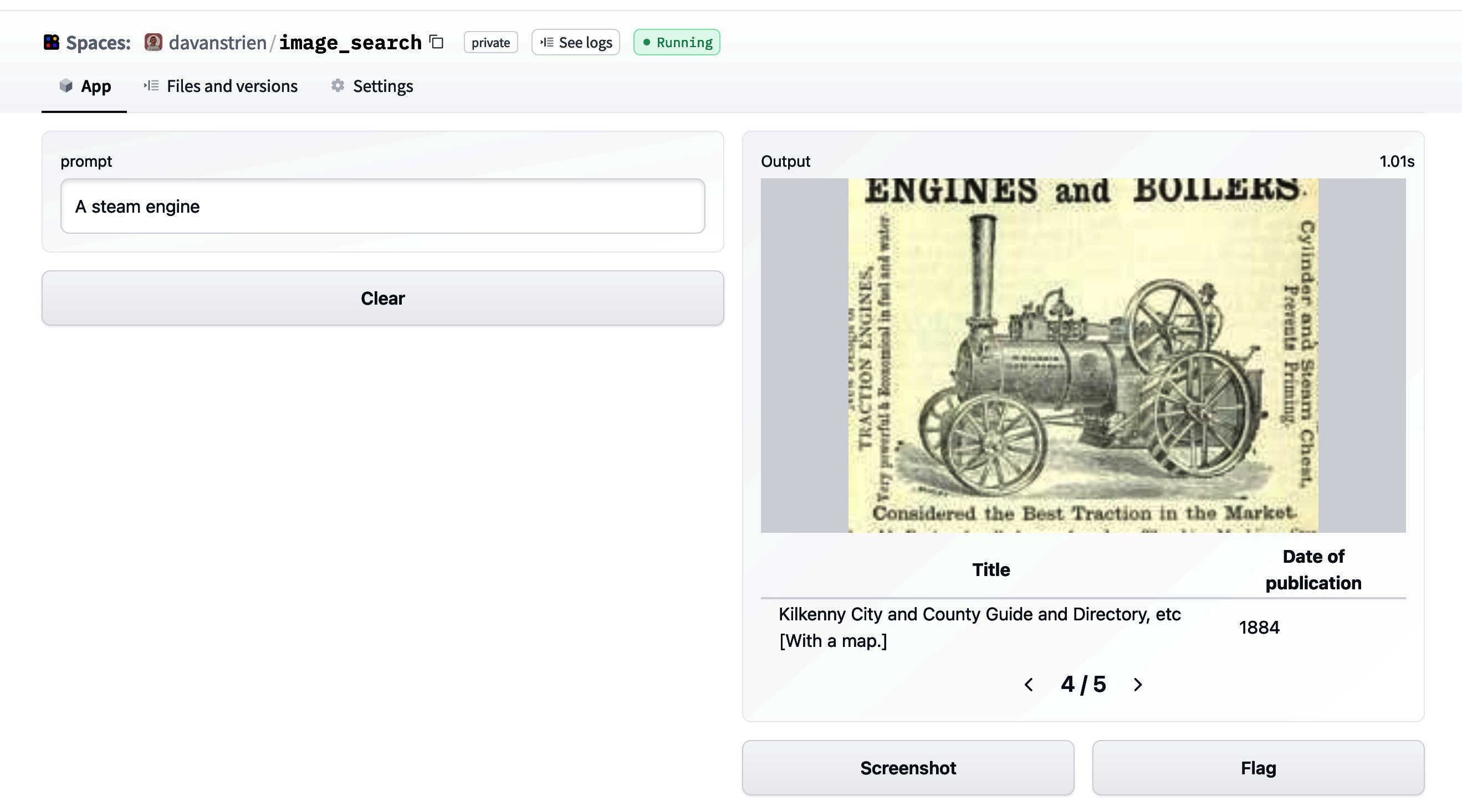
Visivamente, possiamo illustrare questa operazione come segue per n = 16 , d h = 3 n=16, d_h=3 n = 1 6 , d h = 3 :

Si noti che per tutte le visualizzazioni si assume che batch_size e config.num_attention_heads siano 1. Alcuni vettori, ad esempio x 3 \mathbf{x_3} x 3 e il suo vettore di output corrispondente z 3 \mathbf{z_3} z 3 sono contrassegnati in modo che la self-attention LSH possa essere successivamente spiegata meglio. La logica presentata può essere facilmente estesa per la self-attention multi-head ( config.num_attention_heads > 1). Si consiglia al lettore di leggere il transformer illustrato come riferimento per la self-attention multi-head.
È importante ricordare che per ogni vettore di output z i \mathbf{z}_{i} z i , l’intera sequenza di input X \mathbf{X} X viene elaborata. Il tensore del prodotto interno Q K T \mathbf{Q}\mathbf{K}^T Q K T ha una complessità di memoria asintotica di O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) che di solito rappresenta il collo di bottiglia della memoria in un modello transformer.
Questo è anche il motivo per cui bert-base-cased ha una config.max_position_embedding_size di solo 512.
Self-Attention Locale
La self-attention locale è la soluzione ovvia per ridurre il collo di bottiglia della memoria O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) , consentendoci di modellare sequenze più lunghe con un costo computazionale ridotto. Nella self-attention locale, l’input X = X 1 : n = x 1 , … , x n \mathbf{X} = \mathbf{X}_{1:n} = \mathbf{x}_{1}, \ldots, \mathbf{x}_{n} X = X 1 : n = x 1 , … , x n viene diviso in n c n_{c} n c blocchi: X = [ X 1 : l c , … , X ( n c − 1 ) ∗ l c : n c ∗ l c ] \mathbf{X} = \left[\mathbf{X}_{1:l_{c}}, \ldots, \mathbf{X}_{(n_{c} – 1) * l_{c} : n_{c} * l_{c}}\right] X = [ X 1 : l c , … , X ( n c − 1 ) ∗ l c : n c ∗ l c ] ciascuno di lunghezza config.local_chunk_length , ovvero l c l_{c} l c , e successivamente viene applicata la self-attention globale su ciascun blocco separatamente.
Prendiamo la nostra sequenza di input per n = 16 , d h = 3 n=16, d_h=3 n = 1 6 , d h = 3 nuovamente per la visualizzazione:
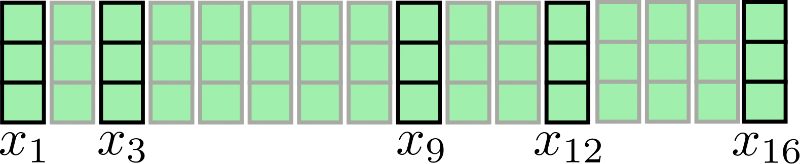
Assumendo l c = 4 , n c = 4 , l’attenzione chunked può essere illustrata come segue:

Come si può vedere, l’operazione di attenzione viene applicata per ogni chunk X 1 : 4 , X 5 : 8 , X 9 : 12 , X 13 : 16 individualmente. Il primo svantaggio di questa architettura diventa evidente: alcuni vettori di input non hanno accesso al loro contesto immediato, ad esempio x 9 non ha accesso a x 8 e viceversa nel nostro esempio. Questo è problematico perché questi token non sono in grado di apprendere rappresentazioni delle parole che tengono conto del loro contesto immediato.
Una semplice soluzione consiste nel ampliare ogni chunk con config.local_num_chunks_before , cioè n p , chunk e config.local_num_chunks_after , cioè n a , in modo che ogni vettore di input abbia almeno accesso a n p vettori di input precedenti e n a vettori di input successivi. Questo può essere anche inteso come chunking con sovrapposizione, mentre n p e n a definiscono la quantità di sovrapposizione che ogni chunk ha con tutti i chunk precedenti e successivi. Indichiamo questa estesa auto-attenzione locale come segue:
Z loc = [ Z 1 : l c loc , … , Z ( n c − 1 ) ∗ l c : n c ∗ l c loc ] , con Z l c ∗ ( i − 1 ) + 1 : l c ∗ i loc = SelfAttn ( X l c ∗ ( i − 1 − n p ) + 1 : l c ∗ ( i + n a ) ) [ n p ∗ l c : − n a ∗ l c ] , ∀ i ∈ { 1 , … , n c }
Okay, questa formula sembra piuttosto complicata. Rendiamola più semplice. Nei livelli di auto-attenzione del Reformer, n a viene di solito impostato a 0 e n p viene impostato a 1, quindi riscriviamo la formula per i = 1 :
Z 1 : l c loc = SelfAttn ( X − l c + 1 : l c ) [ l c : ]
Notiamo che abbiamo una relazione circolare in modo che il primo segmento possa partecipare anche all’ultimo segmento. Illustreremo nuovamente questa attenzione locale leggermente migliorata. Prima di tutto, applichiamo un’auto-attenzione all’interno di ogni segmento con finestra e manteniamo solo il segmento di output centrale.
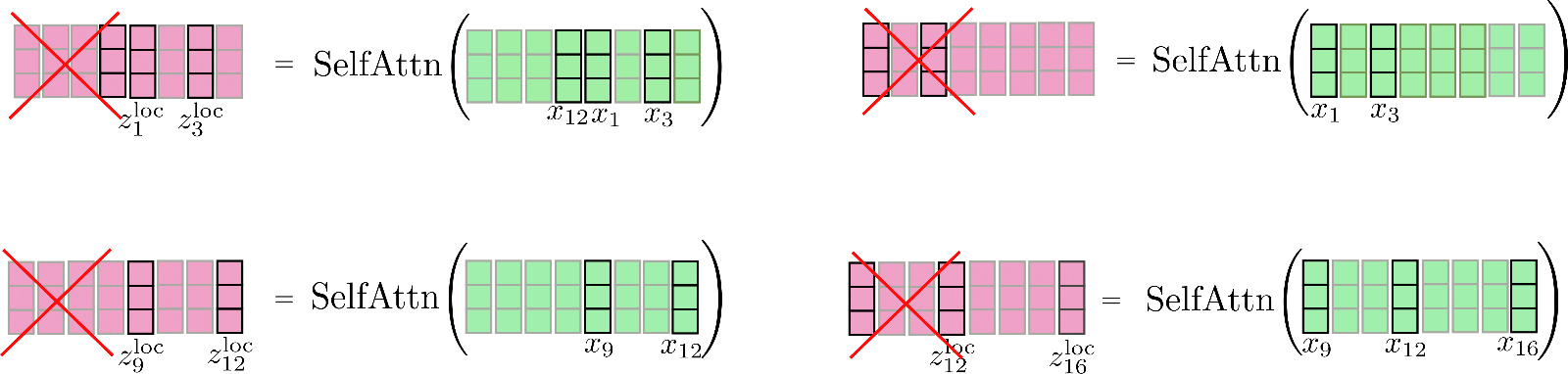
Infine, l’output rilevante viene concatenato con Z loc \mathbf{Z}^{\text{loc}} Z loc e appare come segue.
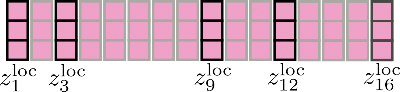
Si noti che l’auto-attenzione locale è implementata in modo efficiente in modo che nessun output venga calcolato e successivamente “scartato” come mostrato qui a scopo illustrativo dalla croce rossa.
È importante notare qui che estendere i vettori di input per ogni funzione di auto-attenzione suddivisa consente a ciascun singolo vettore di output z i \mathbf{z}_{i} z i di questa funzione di auto-attenzione di apprendere rappresentazioni vettoriali migliori. Ad esempio, ciascuno dei vettori di output z 5 loc , z 6 loc , z 7 loc , z 8 loc \mathbf{z}_{5}^{\text{loc}}, \mathbf{z}_{6}^{\text{loc}}, \mathbf{z}_{7}^{\text{loc}}, \mathbf{z}_{8}^{\text{loc}} z 5 loc , z 6 loc , z 7 loc , z 8 loc può tener conto di tutti i vettori di input X 1 : 8 \mathbf{X}_{1:8} X 1 : 8 per apprendere rappresentazioni migliori.
Il guadagno nel consumo di memoria è piuttosto ovvio: la complessità di memoria O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) viene suddivisa per ogni segmento individualmente in modo che il consumo di memoria asintotico totale sia ridotto a O ( n c ∗ l c 2 ) = O ( n ∗ l c ) \mathcal{O}(n_{c} * l_{c}^2) = \mathcal{O}(n * l_{c}) O ( n c ∗ l c 2 ) = O ( n ∗ l c ) .
Questa auto-attenzione locale migliorata è migliore dell’architettura di auto-attenzione locale di base, ma ha ancora un grave inconveniente nel fatto che ogni vettore di input può partecipare solo a un contesto locale di dimensione predefinita. Per compiti di elaborazione del linguaggio naturale che non richiedono al modello di trasformazione di apprendere dipendenze a lungo raggio tra i vettori di input, che includono argomenti come il riconoscimento del discorso, il riconoscimento delle entità nominate e la modellazione causale del linguaggio di frasi corte, questo potrebbe non essere un grosso problema. Molti compiti di elaborazione del linguaggio naturale richiedono invece che il modello apprenda dipendenze a lungo raggio, quindi l’auto-attenzione locale potrebbe portare a un significativo degrado delle prestazioni, ad esempio:
- Risposta alle domande: il modello deve apprendere la relazione tra i token della domanda e i token di risposta pertinenti che molto probabilmente non si troveranno nella stessa gamma locale
- Scelta multipla: il modello deve confrontare tra loro più segmenti di token di risposta che di solito sono separati da una lunghezza significativa
- Riassunto: il modello deve apprendere la relazione tra una lunga sequenza di token di contesto e una sequenza più breve di token di riassunto, mentre le relazioni rilevanti tra contesto e riassunto molto probabilmente non possono essere catturate dall’auto-attenzione locale
- ecc…
L’auto-attenzione locale da sola molto probabilmente non è sufficiente affinché il modello di trasformazione apprenda le relazioni rilevanti tra i vettori di input (token) tra loro.
Pertanto, Reformer utilizza inoltre uno strato di auto-attenzione efficiente che approssima l’auto-attenzione globale, chiamato auto-attenzione LSH.
Auto-attenzione LSH
Ok, ora che abbiamo capito come funziona l’auto-attenzione locale, possiamo affrontare la parte probabilmente più innovativa di Reformer: Auto-attenzione con hashing sensibile alla località (LSH).
Il presupposto dell’auto-attenzione LSH è di essere più o meno efficiente come l’auto-attenzione locale mentre approssima l’auto-attenzione globale.
L’auto-attenzione LSH si basa sull’algoritmo LSH presentato in Andoni et al (2015), da cui il suo nome.
L’idea alla base dell’auto-attenzione LSH si basa sulla consapevolezza che se n è grande, la softmax applicata ai pesi prodotto-scalare di attenzione Q K T \mathbf{Q}\mathbf{K}^T Q K T si applica solo a pochissimi vettori di valore con valori significativamente maggiori di 0 per ogni vettore di query.
Spieghiamo questo in maggior dettaglio. Siano k i ∈ K = [ k 1 , … , k n ] T \mathbf{k}_{i} \in \mathbf{K} = \left[\mathbf{k}_1, \ldots, \mathbf{k}_n \right]^T k i ∈ K = [ k 1 , … , k n ] T e q i ∈ Q = [ q 1 , … , q n ] T \mathbf{q}_{i} \in \mathbf{Q} = \left[\mathbf{q}_1, \ldots, \mathbf{q}_n\right]^T q i ∈ Q = [ q 1 , … , q n ] T i vettori chiave e di interrogazione, rispettivamente. Per ogni q i \mathbf{q}_{i} q i , il calcolo softmax ( q i T K T ) \text{softmax}(\mathbf{q}_{i}^T \mathbf{K}^T) softmax ( q i T K T ) può essere approssimato utilizzando solo quei vettori chiave k j \mathbf{k}_{j} k j che hanno una similitudine coseno elevata con q i \mathbf{q}_{i} q i . Questo perché la funzione softmax attribuisce un peso esponenzialmente maggiore a valori di input più grandi. Fin qui tutto bene, il problema successivo consiste nel trovare efficientemente i vettori che hanno una similitudine coseno elevata con q i \mathbf{q}_{i} q i per tutti i i i .
Innanzitutto, gli autori di Reformer notano che la condivisione delle proiezioni di interrogazione e chiave: Q = K \mathbf{Q} = \mathbf{K} Q = K non influisce sulle prestazioni di un modello transformer 1 {}^1 1 . Ora, invece di dover trovare i vettori chiave con similitudine coseno elevata per ogni vettore di interrogazione q i q_i q i , è sufficiente trovare la similitudine coseno tra i vettori di interrogazione stessi. Questo è importante perché c’è una proprietà transitiva per l’approssimazione del prodotto punto tra i vettori di interrogazione: se q i \mathbf{q}_{i} q i ha una similitudine coseno elevata con i vettori di interrogazione q j \mathbf{q}_{j} q j e q k \mathbf{q}_{k} q k , allora q j \mathbf{q}_{j} q j ha anche una similitudine coseno elevata con q k \mathbf{q}_{k} q k . Pertanto, i vettori di interrogazione possono essere raggruppati in bucket, in modo che tutti i vettori di interrogazione appartenenti allo stesso bucket abbiano una similitudine coseno elevata tra loro. Definiamo C m C_{m} C m come l’insieme di indici di posizione m, tali che i loro vettori di interrogazione corrispondenti si trovano nello stesso bucket: C m = { i ∣ s.t. q i ∈ mth cluster } C_{m} = \{ i | \text{ s.t. } \mathbf{q}_{i} \in \text{mth cluster}\} C m = { i ∣ s.t. q i ∈ mth cluster } e config.num_buckets , cioè n b n_{b} n b , come il numero di bucket.
Per ogni insieme di indici C m C_{m} C m , la funzione softmax dei vettori di interrogazione corrispondente softmax ( Q i ∈ C m Q i ∈ C m T ) \text{softmax}(\mathbf{Q}_{i \in C_{m}} \mathbf{Q}^T_{i \in C_{m}}) softmax ( Q i ∈ C m Q i ∈ C m T ) approssima la funzione softmax dell’autointerazione globale con proiezioni di interrogazione e chiave condivise softmax ( q i T Q T ) \text{softmax}(\mathbf{q}_{i}^T \mathbf{Q}^T) softmax ( q i T Q T ) per tutti gli indici di posizione i i i in C m C_{m} C m .
In secondo luogo, gli autori utilizzano l’algoritmo LSH per raggruppare i vettori di interrogazione in un numero predefinito di bucket n b n_{b} n b . L’algoritmo LSH è una scelta ideale qui perché è molto efficiente ed è un’approssimazione dell’algoritmo del nearest neighbor per la similitudine coseno. Spiegare il funzionamento dello schema LSH esula dagli scopi di questo documento, quindi teniamo presente che per ogni vettore q i \mathbf{q}_{i} q i l’algoritmo LSH assegna il suo indice di posizione i i i a uno dei bucket predefiniti n b n_{b} n b , cioè LSH ( q i ) = m \text{LSH}(\mathbf{q}_{i}) = m LSH ( q i ) = m con i ∈ { 1 , … , n } i \in \{1, \ldots, n\} i ∈ { 1 , … , n } e m ∈ { 1 , … , n b } m \in \{1, \ldots, n_{b}\} m ∈ { 1 , … , n b } .
Visivamente, possiamo illustrare questo come segue per il nostro esempio originale:

In terzo luogo, si può notare che avendo raggruppato tutti i vettori di query in n b n_{b} n b bucket, l’insieme corrispondente di indici C m C_{m} C m può essere utilizzato per permutare i vettori di input x 1 , … , x n \mathbf{x}_1, \ldots, \mathbf{x}_n x 1 , … , x n di conseguenza 2 {}^2 2 in modo che l’attenzione condivisa tra query e chiave possa essere applicata in modo simile all’attenzione locale.
Chiarifichiamo con i nostri vettori di input di esempio X = x 1 , . . . , x 16 \mathbf{X} = \mathbf{x}_1, …, \mathbf{x}_{16} X = x 1 , . . . , x 1 6 assumiamo che config.num_buckets=4 e config.lsh_chunk_length = 4 . Guardando il grafico sopra possiamo vedere che abbiamo assegnato ciascun vettore di query q 1 , … , q 16 \mathbf{q}_1, \ldots, \mathbf{q}_{16} q 1 , … , q 1 6 a uno dei cluster C 1 , C 2 , C 3 , C 4 \mathcal{C}_{1}, \mathcal{C}_{2}, \mathcal{C}_{3}, \mathcal{C}_{4} C 1 , C 2 , C 3 , C 4 . Se ora ordiniamo i corrispondenti vettori di input x 1 , … , x 16 \mathbf{x}_1, \ldots, \mathbf{x}_{16} x 1 , … , x 1 6 di conseguenza, otteniamo l’input permutato seguente X ′ \mathbf{X’} X ′ :
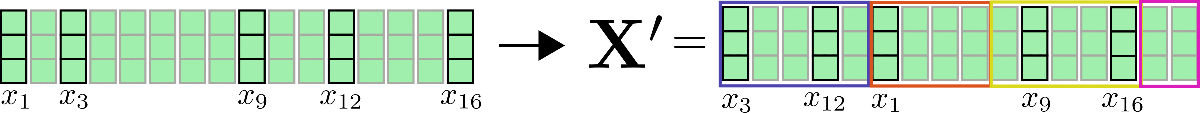
Il meccanismo di autoattenzione dovrebbe essere applicato per ogni cluster individualmente in modo che per ogni cluster C m \mathcal{C}_m C m l’output corrispondente venga calcolato come segue: Z i ∈ C m LSH = SelfAttn Q = K ( X i ∈ C m ) \mathbf{Z}^{\text{LSH}}_{i \in \mathcal{C}_m} = \text{SelfAttn}_{\mathbf{Q}=\mathbf{K}}(\mathbf{X}_{i \in \mathcal{C}_m}) Z i ∈ C m LSH = SelfAttn Q = K ( X i ∈ C m ) .
Illustreremo questo nuovamente per il nostro esempio.
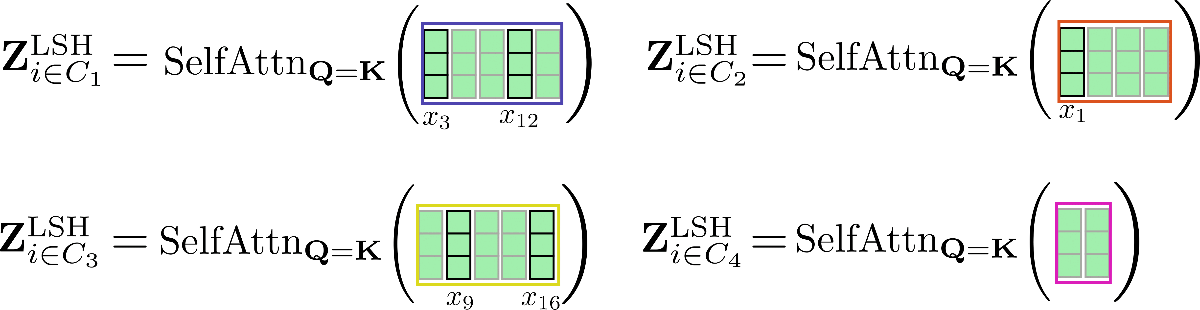
Come si può vedere, la funzione di autoattenzione opera su matrici di dimensioni diverse, il che non è ottimale per il batching efficiente in GPU e TPU.
Per superare questo problema, l’input permutato può essere suddiviso nello stesso modo in cui viene fatto per l’attenzione locale in modo che ogni chunk abbia dimensione config.lsh_chunk_length . Suddividendo l’input permutato, un bucket potrebbe essere diviso in due chunk diversi. Per rimediare a questo problema, nell’autoattenzione LSH ogni chunk fa riferimento al suo chunk precedente config.lsh_num_chunks_before=1 oltre a se stesso, allo stesso modo dell’autoattenzione locale ( config.lsh_num_chunks_after di solito viene impostato a 0). In questo modo, possiamo essere sicuri che tutti i vettori in un bucket si attengano l’uno all’altro con una probabilità elevata 3 {}^3 3 .
In generale, per tutti i chunk k ∈ { 1 , … , n c } k \in \{1, \ldots, n_{c}\} k ∈ { 1 , … , n c } , l’autoattenzione LSH può essere indicata come segue:
Z ′ l c ∗ k + 1 : l c ∗ ( k + 1 ) LSH = SelfAttn Q = K ( X ′ l c ∗ k + 1 ) : l c ∗ ( k + 1 ) ) [ l c : ] \mathbf{Z’}_{l_{c} * k + 1:l_{c} * (k + 1)}^{\text{LSH}} = \text{SelfAttn}_{\mathbf{Q} = \mathbf{K}}(\mathbf{X’}_{l_{c} * k + 1): l_{c} * (k + 1)})\left[l_{c}:\right] Z ′ l c ∗ k + 1 : l c ∗ ( k + 1 ) LSH = SelfAttn Q = K ( X ′ l c ∗ k + 1 ) : l c ∗ ( k + 1 ) ) [ l c : ]
con X ′ \mathbf{X’} X ′ e Z ′ \mathbf{Z’} Z ′ che sono i vettori di input e output permutati secondo l’algoritmo LSH. Abbastanza formule complicate, vediamo l’auto-attenzione LSH.
I vettori permutati X ′ \mathbf{X’} X ′ come mostrato sopra sono divisi in blocchi e l’auto-attenzione query chiave condivisa viene applicata a ciascun blocco.
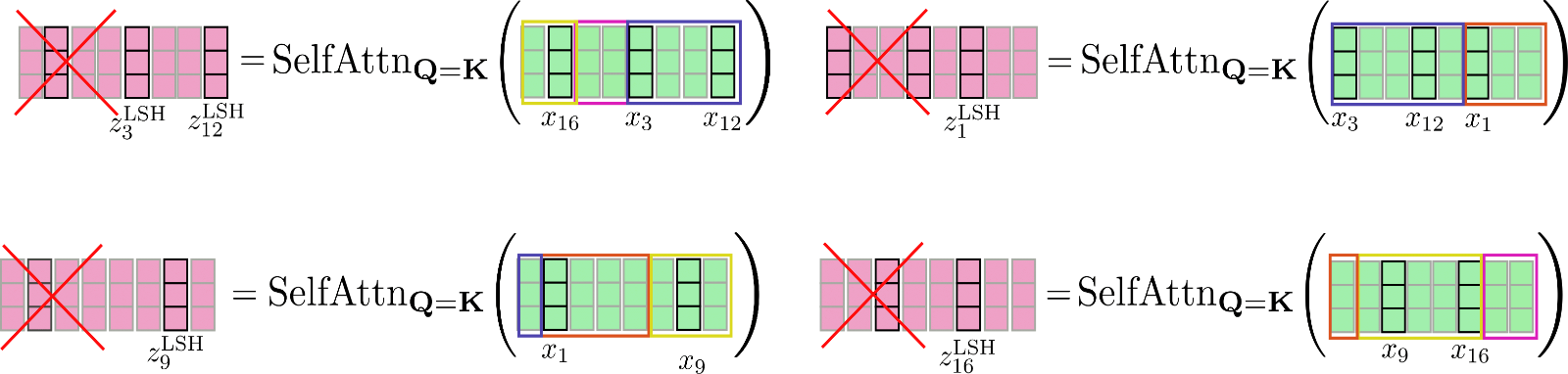
Infine, l’output Z ′ LSH \mathbf{Z’}^{\text{LSH}} Z ′ LSH viene riordinato nella sua permutazione originale.
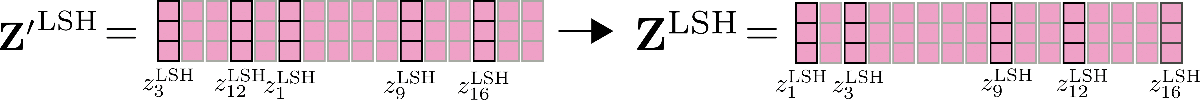
Un’altra caratteristica importante da menzionare qui è che l’accuratezza dell’auto-attenzione LSH può essere migliorata eseguendo l’auto-attenzione LSH config.num_hashes, ad esempio n h n_{h} n h volte in parallelo, ognuna con un hash LSH casuale diverso. Impostando config.num_hashes > 1, per ogni posizione di output i i i, vengono calcolati e successivamente uniti più vettori di output z i LSH , 1 , … , z i LSH , n h \mathbf{z}^{\text{LSH}, 1}_{i}, \ldots, \mathbf{z}^{\text{LSH}, n_{h}}_{i} z i LSH , 1 , … , z i LSH , n h : z i LSH = ∑ k n h Z i LSH , k ∗ weight i k \mathbf{z}^{\text{LSH}}_{i} = \sum_k^{n_{h}} \mathbf{Z}^{\text{LSH}, k}_{i} * \text{weight}^k_i z i LSH = ∑ k n h Z i LSH , k ∗ weight i k . Il peso i k \text{weight}^k_i peso i k rappresenta l’importanza dei vettori di output z i LSH , k \mathbf{z}^{\text{LSH}, k}_{i} z i LSH , k della round di hashing k k k rispetto alle altre round di hashing ed è proporzionale in modo esponenziale al termine di normalizzazione del loro calcolo softmax. L’intuizione dietro questo è che se il vettore di query corrispondente q i k \mathbf{q}_{i}^{k} q i k ha una somiglianza coseno elevata con tutti gli altri vettori di query nel suo blocco rispettivo, quindi il termine di normalizzazione softmax di questo blocco tende ad essere alto, in modo che i vettori di output corrispondenti q i k \mathbf{q}_{i}^{k} q i k siano una migliore approssimazione dell’attenzione globale e quindi ricevano più peso rispetto ai vettori di output delle round di hashing con un termine di normalizzazione softmax più basso. Per ulteriori dettagli, consultare l’Appendice A del paper. Per il nostro esempio, l’auto-attenzione LSH a più round può essere illustrata come segue.
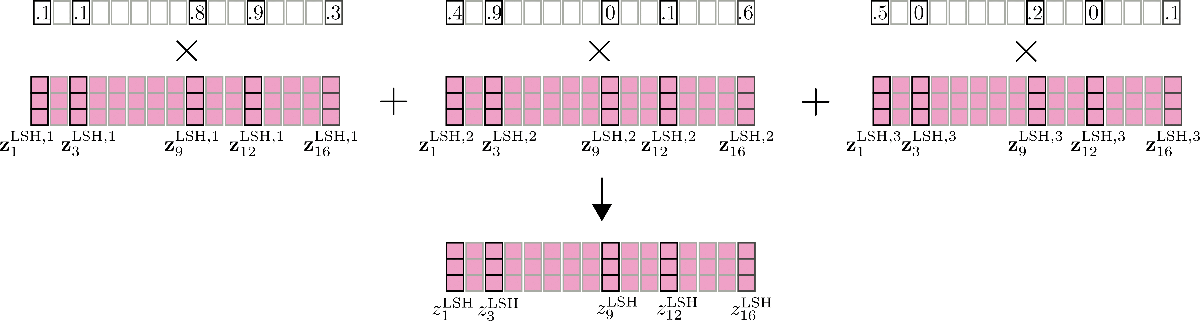
Perfetto. Questo è tutto. Ora sappiamo come funziona l’auto-attenzione LSH in Reformer.
Riguardo alla complessità di memoria, ora abbiamo due termini che competono tra loro per essere il collo di bottiglia della memoria: il prodotto scalare: O(nh * nc * lc^2) = O(n * nh * lc) e la memoria richiesta per l’aggregazione tramite LSH: O(n * nh * nb^2) con lc che rappresenta la lunghezza del blocco. Poiché per valori grandi di n, il numero di blocchi cresce molto più velocemente della lunghezza del blocco lc, l’utente può nuovamente scomporre il numero di blocchi config.num_buckets come spiegato qui.
Riassumiamo brevemente ciò che abbiamo analizzato sopra:
- Vogliamo approssimare l’attenzione globale utilizzando la conoscenza che l’operazione softmax pone solo pesi significativi su pochi vettori chiave.
- Se i vettori chiave sono uguali ai vettori di query questo significa che per ogni vettore di query q i \mathbf{q}_{i} q i , la softmax pone solo un peso significativo su altri vettori di query che sono simili in termini di similarità coseno.
- Questa relazione funziona in entrambi i modi, il che significa che se q j \mathbf{q}_{j} q j è simile a q i \mathbf{q}_{i} q i allora q j \mathbf{q}_{j} q j è anche simile a q i \mathbf{q}_{i} q i , in modo che possiamo fare una clusterizzazione globale prima di applicare l’auto-attenzione su un input permutato.
- Applichiamo l’auto-attenzione locale sull’input permutato e riordiniamo l’output alla sua permutazione originale.
1 {}^{1} 1 Gli autori hanno eseguito alcuni esperimenti preliminari confermando che l’auto-attenzione condivisa tra query e chiavi funziona più o meno allo stesso modo dell’auto-attenzione standard.
2 {}^{2} 2 Per essere più precisi, i vettori di query all’interno di un bucket vengono ordinati secondo il loro ordine originale. Ciò significa che se, ad esempio, i vettori q 1 , q 3 , q 7 \mathbf{q}_1, \mathbf{q}_3, \mathbf{q}_7 q 1 , q 3 , q 7 sono tutti hashati nel bucket 2, l’ordine dei vettori nel bucket 2 sarebbe ancora q 1 \mathbf{q}_1 q 1 , seguito da q 3 \mathbf{q}_3 q 3 e q 7 \mathbf{q}_7 q 7 .
3 {}^3 3 A proposito, è da menzionare che gli autori mettono una maschera sul vettore di query q i \mathbf{q}_{i} q i per evitare che il vettore si riferisca a se stesso. Poiché la similarità coseno di un vettore con se stesso sarà sempre alta o più alta della similarità coseno con altri vettori, i vettori di query nell’auto-attenzione condivisa tra query e chiavi sono fortemente scoraggiati a riferirsi a se stessi.
Benchmark
Recentemente sono stati aggiunti strumenti di benchmark ai Transformers – vedere qui per una spiegazione più dettagliata.
Per mostrare quanto memoria può essere risparmiata utilizzando l’auto-attenzione “locale” + “LSH”, il modello Reformer google/reformer-enwik8 viene testato con diverse lunghezze di local_attn_chunk_length e lsh_attn_chunk_length . La configurazione predefinita e l’utilizzo del modello google/reformer-enwik8 possono essere controllati in modo più dettagliato qui .
Prima di tutto, facciamo alcuni import e installazioni necessari.
#@title Installazioni e Importazioni
# installazioni con pip
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArgumentsPrima di tutto, testiamo l’utilizzo della memoria del modello Reformer utilizzando l’auto-attenzione globale. Ciò può essere ottenuto impostando lsh_attn_chunk_length = local_attn_chunk_length = 8192 in modo che per tutte le sequenze di input minori o uguali a 8192, il modello passi automaticamente all’auto-attenzione globale.
config = ReformerConfig.from_pretrained("google/reformer-enwik8", lsh_attn_chunk_length=16386, local_attn_chunk_length=16386, lsh_num_chunks_before=0, local_num_chunks_before=0)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16386], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1279.0, style=ProgressStyle(description…
1 / 1
Non si adatta alla GPU. Memoria CUDA esaurita. Tentativo di allocare 2.00 GiB (GPU 0; capacità totale 11.17 GiB; 8.87 GiB già allocati; 1.92 GiB liberi; 8.88 GiB totali riservati da PyTorch)
==================== INFERENZA - MEMORIA - RISULTATO ====================
--------------------------------------------------------------------------------
Nome Modello Batch Size Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1465
Reformer 1 4096 2757
Reformer 1 8192 7893
Reformer 1 16386 N/A
--------------------------------------------------------------------------------Più lunga è la sequenza di input, più evidente è la relazione quadratica O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) tra la sequenza di input e l’utilizzo di memoria massimo. Come si può vedere, nella pratica sarebbe necessaria una sequenza di input molto più lunga per osservare chiaramente che il raddoppio della sequenza di input quadruplica l’utilizzo di memoria massimo.
Per questo, un modello google/reformer-enwik8 che utilizza l’attenzione globale, con una lunghezza di sequenza superiore a 16K, provoca un overflow di memoria.
Ora, attiviamo l’auto-attenzione locale e LSH utilizzando i parametri predefiniti del modello.
config = ReformerConfig.from_pretrained("google/reformer-enwik8")
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16384, 32768, 65436], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
1 / 1
Non si adatta alla GPU. Memoria CUDA esaurita. Tentativo di allocare 2.00 GiB (GPU 0; capacità totale 11.17 GiB; 7.85 GiB già allocati; 1.74 GiB liberi; 9.06 GiB riservati in totale da PyTorch)
Non si adatta alla GPU. Memoria CUDA esaurita. Tentativo di allocare 4.00 GiB (GPU 0; capacità totale 11.17 GiB; 6.56 GiB già allocati; 3.99 GiB liberi; 6.81 GiB riservati in totale da PyTorch)
==================== INFERENZA - MEMORIA - RISULTATO ====================
--------------------------------------------------------------------------------
Nome del Modello Dimensione Batch Lunghezza Sequenza Memoria in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1785
Reformer 1 4096 2621
Reformer 1 8192 4281
Reformer 1 16384 7607
Reformer 1 32768 N/A
Reformer 1 65436 N/A
--------------------------------------------------------------------------------Come ci si aspetta, l’utilizzo dell’auto-attenzione locale e LSH è molto più efficiente in termini di memoria per sequenze di input più lunghe, in modo che il modello esaurisca la memoria solo a 16K token per una GPU da 11GB di RAM in questo notebook.
2. Strati di Feed Forward Chunked
I modelli basati su Transformer spesso utilizzano strati di feed forward molto grandi dopo lo strato di auto-attenzione in parallelo. Questo strato può occupare una quantità significativa della memoria complessiva e talvolta rappresentare il collo di bottiglia della memoria di un modello. Introdotto per la prima volta nel paper Reformer, il feed forward chunking è una tecnica che consente di scambiare una migliore consumazione di memoria con un aumento del consumo di tempo.
Strato di Feed Forward Chunked in Reformer
In Reformer, lo strato di auto-attenzione LSH – o auto-attenzione locale – è seguito di solito da una connessione residua, che definisce la prima parte in un blocco di Transformer. Per maggiori dettagli su questo, fare riferimento a questo blog.
L’output della prima parte del blocco di Transformer, chiamato output di auto-attenzione normalizzato, può essere scritto come Z ‾ = Z + X, con Z che può essere Z LSH o Z loc in Reformer.
Per il nostro esempio di input x 1 , … , x 16, illustreremo l’output di auto-attenzione normalizzato come segue.

Ora, la seconda parte di un blocco di Transformer di solito consiste in due strati di feed forward 1 ^{1} 1, definiti come Linear int ( … ) che elabora Z ‾ in un output intermedio Y int e Linear out ( … ) che elabora l’output intermedio in un output finale Y out. I due strati di feed forward possono essere definiti come
Y out = Linear out ( Y int ) = Linear out ( Linear int ( Z ‾ ) ) .
È importante ricordare in questo punto che matematicamente l’output di uno strato di feed forward in posizione y out , i \mathbf{y}_{\text{out}, i} y out , i dipende solo dall’input in questa posizione y ‾ i \mathbf{\overline{y}}_{i} y i . A differenza dello strato di attenzione, ogni output y out , i \mathbf{y}_{\text{out}, i} y out , i è quindi completamente indipendente da tutti gli input y ‾ j ≠ i \mathbf{\overline{y}}_{j \ne i} y j = i di diverse posizioni.
Rappresentiamo gli strati di feed forward per z ‾ 1 , … , z ‾ 16 \mathbf{\overline{z}}_1, \ldots, \mathbf{\overline{z}}_{16} z 1 , … , z 1 6 .
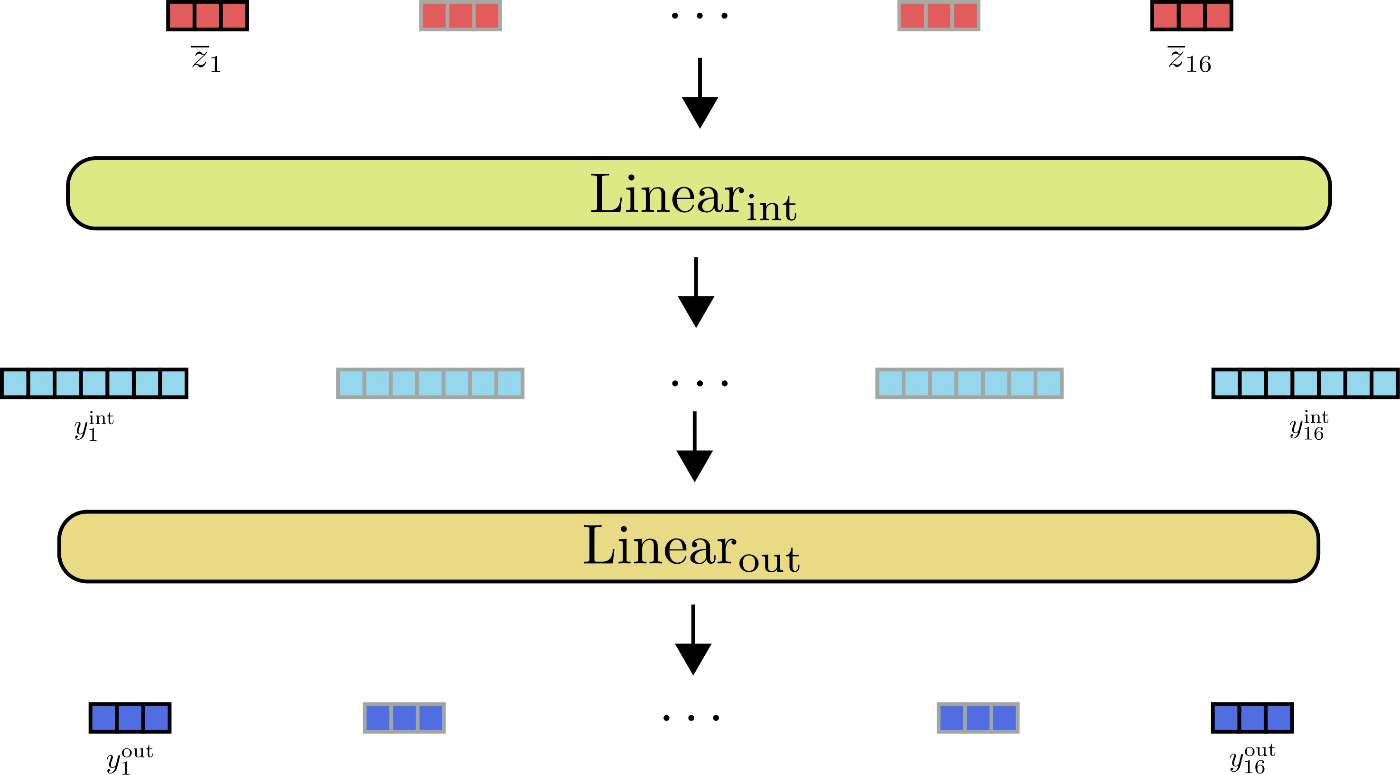
Come si può vedere dall’illustrazione, tutti i vettori di input z ‾ i \mathbf{\overline{z}}_{i} z i sono elaborati dallo stesso strato di feed forward in parallelo.
Diventa interessante quando si osservano le dimensioni di output degli strati di feed forward. Nel Reformer, la dimensione di output di Linear int \text{Linear}_{\text{int}} Linear int è definita come config.feed_forward_size , ad esempio d f d_{f} d f , e la dimensione di output di Linear out \text{Linear}_{\text{out}} Linear out è definita come config.hidden_size , cioè d h d_{h} d h .
Gli autori del Reformer hanno osservato che in un modello di transformer la dimensione intermedia d f d_{f} d f tende di solito ad essere molto più grande della dimensione di output 2 ^{2} 2 d h d_{h} d h . Questo significa che il tensore Y int \mathbf{\mathbf{Y}}_\text{int} Y int di dimensione d f × n d_{f} \times n d f × n allocata una quantità significativa della memoria totale e può addirittura diventare il collo di bottiglia della memoria.
Per avere una migliore percezione delle differenze nelle dimensioni, rappresentiamo le matrici Y int \mathbf{Y}_\text{int} Y int e Y out \mathbf{Y}_\text{out} Y out per il nostro esempio.
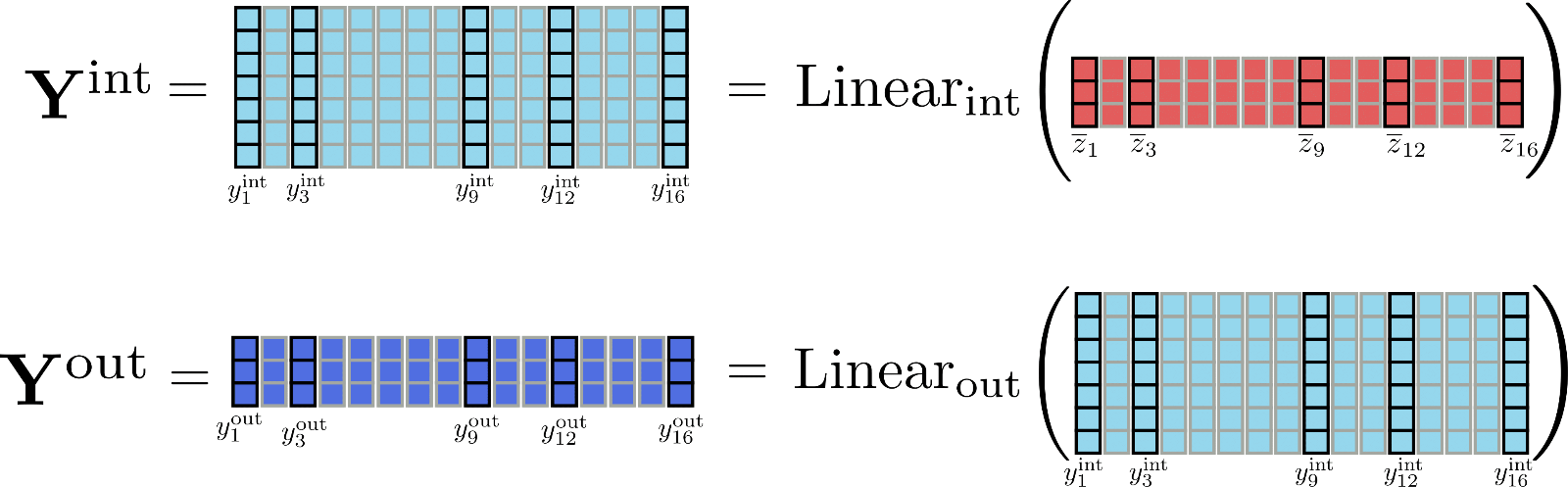
Diventa abbastanza ovvio che il tensore Y int \mathbf{Y}_\text{int} Y int occupa molta più memoria ( d f d h × n \frac{d_{f}}{d_{h}} \times n d h d f × n per essere precisi) rispetto a Y out \mathbf{Y}_\text{out} Y out . Ma è necessario calcolare l’intera matrice intermedia Y int \mathbf{Y}_\text{int} Y int ? Non proprio, perché è rilevante solo la matrice di output Y out \mathbf{Y}_\text{out} Y out . Per scambiare memoria con velocità, è possibile quindi suddividere il calcolo degli strati lineari in chunk per elaborare solo un chunk alla volta. Definendo config.chunk_size_feed_forward come c f c_{f} c f , gli strati lineari suddivisi sono definiti come Y out = [ Y out , 1 : c f , … , Y out , ( n − c f ) : n ] \mathbf{Y}_{\text{out}} = \left[\mathbf{Y}_{\text{out}, 1: c_{f}}, \ldots, \mathbf{Y}_{\text{out}, (n – c_{f}): n}\right] Y out = [ Y out , 1 : c f , … , Y out , ( n − c f ) : n ] con Y out , ( c f ∗ i ) : ( i ∗ c f + i ) = Linear out ( Linear int ( Z ‾ ( c f ∗ i ) : ( i ∗ c f + i ) ) ) \mathbf{Y}_{\text{out}, (c_{f} * i): (i * c_{f} + i)} = \text{Linear}_{\text{out}}(\text{Linear}_{\text{int}}(\mathbf{\overline{Z}}_{(c_{f} * i): (i * c_{f} + i)})) Y out , ( c f ∗ i ) : ( i ∗ c f + i ) = Linear out ( Linear int ( Z ( c f ∗ i ) : ( i ∗ c f + i ) ) ) . In pratica, ciò significa semplicemente che l’output viene calcolato incrementalmente e concatenato per evitare di dover memorizzare l’intero tensore intermedio Y int \mathbf{Y}_{\text{int}} Y int in memoria.
Supponendo che c f = 1 per il nostro esempio, possiamo illustrare il calcolo incrementale dell’output per la posizione i = 9 come segue.
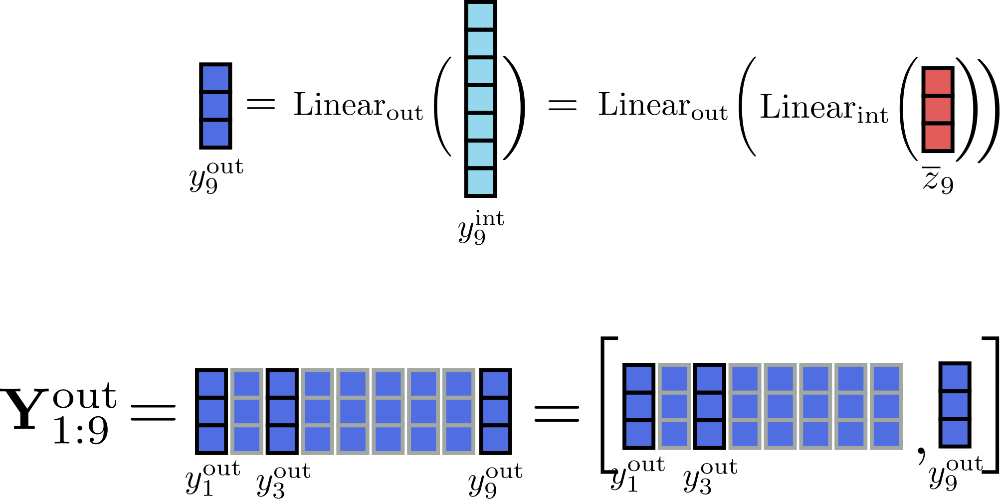
Elaborando gli input in blocchi di dimensione 1, gli unici tensori che devono essere memorizzati in memoria contemporaneamente sono Y out \mathbf{Y}_\text{out} Y out di dimensione massima 16 × d h 16 \times d_{h} 1 6 × d h , y int , i \mathbf{y}_{\text{int}, i} y int , i di dimensione d f d_{f} d f e l’input Z ‾ \mathbf{\overline{Z}} Z di dimensione 16 × d h 16 \times d_{h} 1 6 × d h , con d h d_{h} d h che è config.hidden_size 3 ^{3} 3 .
Infine, è importante ricordare che i livelli lineari suddivisi producono un output matematicamente equivalente ai livelli lineari convenzionali e possono quindi essere applicati a tutti i livelli lineari del transformer. L’utilizzo di config.chunk_size_feed_forward consente quindi un miglior compromesso tra memoria e velocità in determinati casi d’uso.
1 {}^1 1 Per una spiegazione più semplice, per ora viene omesso il livello di normalizzazione del layer che di solito viene applicato a Z ‾ \mathbf{\overline{Z}} Z prima di essere elaborato dai livelli feed forward.
2 {}^2 2 In bert-base-uncased , ad esempio, la dimensione intermedia d f d_{f} d f è quattro volte più grande della dimensione dell’output d h d_{h} d h .
3 {}^3 3 Come promemoria, si assume che l’output config.num_attention_heads sia 1 per chiarezza e illustrazione in questo notebook, in modo che l’output dei livelli di self-attention possa essere considerato di dimensione config.hidden_size .
Maggiori informazioni sui livelli lineari / feed forward suddivisi possono essere trovate anche qui nella documentazione di 🤗Transformers.
Benchmark
Vediamo quanto memoria può essere risparmiata utilizzando i livelli feed forward suddivisi.
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
Building wheel for transformers (setup.py) ... [?25l[?25hdonePrima, confrontiamo il modello predefinito google/reformer-enwik8 senza i livelli feed forward suddivisi con quello con i livelli feed forward suddivisi.
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8") # nessun suddivisione
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1) # suddivisione feed forward
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
Non entra nella GPU. Memoria CUDA esaurita. Tentativo di allocare 2.00 GiB (GPU 0; capacità totale di 11.17 GiB; 7.85 GiB già allocati; 1.74 GiB liberi; 9.06 GiB riservati in totale da PyTorch)
2 / 2
Non entra nella GPU. Memoria CUDA esaurita. Tentativo di allocare 2.00 GiB (GPU 0; capacità totale di 11.17 GiB; 7.85 GiB già allocati; 1.24 GiB liberi; 9.56 GiB riservati in totale da PyTorch)
==================== INFERENZA - MEMORIA - RISULTATO ====================
--------------------------------------------------------------------------------
Nome del modello Dimensione del batch Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 4281
Reformer-No-Chunk 8 2048 7607
Reformer-No-Chunk 8 4096 N/A
Reformer-Chunk 8 1024 4309
Reformer-Chunk 8 2048 7669
Reformer-Chunk 8 4096 N/A
--------------------------------------------------------------------------------Interessante, i livelli di avanzamento del feed forward a blocchi non sembrano aiutare affatto qui. Il motivo è che config.feed_forward_size non è sufficientemente grande per fare una vera differenza. Solo a lunghezze di sequenza più lunghe di 4096, si può notare una leggera diminuzione dell’utilizzo della memoria.
Vediamo cosa succede al picco di utilizzo della memoria se aumentiamo la dimensione del livello di avanzamento del feed forward di un fattore 4 e riduciamo anche il numero di attenzioni di un fattore 4 in modo che il livello di avanzamento del feed forward diventi il collo di bottiglia della memoria.
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=0, num_attention_{h}eads=2, feed_forward_size=16384) # no chuck
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1, num_attention_{h}eads=2, feed_forward_size=16384) # feed forward chunk
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Nome del Modello Dimensione Batch Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 3743
Reformer-No-Chunk 8 2048 5539
Reformer-No-Chunk 8 4096 9087
Reformer-Chunk 8 1024 2973
Reformer-Chunk 8 2048 3999
Reformer-Chunk 8 4096 6011
--------------------------------------------------------------------------------Ora si può notare una chiara diminuzione dell’utilizzo della memoria di picco per sequenze di input più lunghe. In conclusione, si deve notare che i livelli di avanzamento del feed forward a blocchi hanno senso solo per modelli con poche attenzioni e ampi livelli di avanzamento del feed forward.
3. Livelli Residuali Reversibili
I livelli residuali reversibili sono stati introdotti per la prima volta in N. Gomez et al e utilizzati per ridurre il consumo di memoria durante l’addestramento del popolare modello ResNet. Matematicamente, i livelli residuali reversibili sono leggermente diversi dai livelli residuali “reali”, ma non richiedono che le attivazioni vengano salvate durante il passaggio in avanti, il che può ridurre drasticamente il consumo di memoria durante l’addestramento.
Livelli Residuali Reversibili in Reformer
Iniziamo investigando perché addestrare un modello richiede molta più memoria rispetto all’inferenza del modello.
Quando si esegue un modello in inferenza, la memoria richiesta corrisponde più o meno alla memoria necessaria per calcolare il singolo tensore più grande nel modello. D’altra parte, quando si addestra un modello, la memoria richiesta corrisponde più o meno alla somma di tutti i tensori differenziabili.
Questo non sorprende se si considera come funziona l’autodifferenziazione nei framework di deep learning. Queste slide della lezione di Roger Grosse dell’Università di Toronto sono ottime per comprendere meglio l’autodifferenziazione.
In poche parole, per calcolare il gradiente di una funzione differenziabile (ad esempio, un layer), l’autodifferenziazione richiede il gradiente dell’output della funzione e il tensore di input e output della funzione stessa. Mentre i gradienti vengono calcolati dinamicamente e successivamente scartati, i tensori di input e output (chiamati attivazioni) di una funzione vengono memorizzati durante il passaggio in avanti.
Bene, applichiamo questo concetto a un modello transformer. Un modello transformer include una serie di più livelli di transformer, chiamati anche livelli di attenzione multipla. Ogni livello di transformer aggiuntivo costringe il modello a memorizzare più attivazioni durante il passaggio in avanti e aumenta quindi la memoria richiesta per l’addestramento. Diamo un’occhiata più dettagliata. Un livello di transformer consiste essenzialmente in due livelli residuali. Il primo livello residuo rappresenta il meccanismo di autoattenzione come spiegato nella sezione 1) e il secondo livello residuo rappresenta i livelli lineari o di avanzamento del feed forward come spiegato nella sezione 2).
Utilizzando la stessa notazione di prima, l’input di un livello di transformer, ovvero X \mathbf{X} X, viene prima normalizzato 1 ^{1} 1 e successivamente elaborato dal livello di autoattenzione per ottenere l’output Z = SelfAttn ( LayerNorm ( X ) ) \mathbf{Z} = \text{SelfAttn}(\text{LayerNorm}(\mathbf{X})) Z = SelfAttn ( LayerNorm ( X ) ). Abbrevieremo questi due livelli con G G G in modo che Z = G ( X ) \mathbf{Z} = G(\mathbf{X}) Z = G ( X ). Successivamente, l’output Z \mathbf{Z} Z viene aggiunto all’input Z ‾ = Z + X \mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X} Z = Z + X e la somma viene alimentata al secondo livello residuo, ovvero i due livelli lineari. Z ‾ \mathbf{\overline{Z}} Z viene elaborato da un secondo livello di normalizzazione, seguito dai due livelli lineari per ottenere Y = Linear ( LayerNorm ( Z + X ) ) \mathbf{Y} = \text{Linear}(\text{LayerNorm}(\mathbf{Z} + \mathbf{X})) Y = Linear ( LayerNorm ( Z + X ) ). Abbrevieremo il secondo livello di normalizzazione e i due livelli lineari con F F F ottenendo Y = F ( Z ‾ ) \mathbf{Y} = F(\mathbf{\overline{Z}}) Y = F ( Z ). Infine, il residuo Y \mathbf{Y} Y viene aggiunto a Z ‾ \mathbf{\overline{Z}} Z per ottenere l’output del livello di transformer Y ‾ = Y + Z ‾ \mathbf{\overline{Y}} = \mathbf{Y} + \mathbf{\overline{Z}} Y = Y + Z .
Illustreremo un layer di transformer completo utilizzando l’esempio di x 1 , … , x 16 \mathbf{x}_1, \ldots, \mathbf{x}_{16} x 1 , … , x 1 6 .
![]()
Per calcolare il gradiente di ad esempio il blocco di self-attention G G G , tre tensori devono essere noti in precedenza: il gradiente ∂ Z \partial \mathbf{Z} ∂ Z , l’output Z \mathbf{Z} Z e l’input X \mathbf{X} X . Mentre ∂ Z \partial \mathbf{Z} ∂ Z può essere calcolato al volo e scartato successivamente, i valori di Z \mathbf{Z} Z e X \mathbf{X} X devono essere calcolati e memorizzati durante il passaggio in avanti poiché non è possibile ricalcolarli facilmente al volo durante la backpropagation. Pertanto, durante il passaggio in avanti, grandi output di tensori, come la matrice di prodotto scalare tra query e chiave Q K T \mathbf{Q}\mathbf{K}^T Q K T o l’output intermedio dei layer lineari Y int \mathbf{Y}^{\text{int}} Y int , devono essere memorizzati in memoria 2 ^{2} 2 .
Qui, i layer residuali reversibili vengono in nostro aiuto. L’idea è relativamente semplice. Il blocco residuale è progettato in modo tale che anziché dover memorizzare il tensore di input e output di una funzione, entrambi possono essere facilmente ricalcolati durante il passaggio all’indietro in modo che nessun tensore debba essere memorizzato in memoria durante il passaggio in avanti. Questo viene ottenuto utilizzando due flussi di input X ( 1 ) , X ( 2 ) \mathbf{X}^{(1)}, \mathbf{X}^{(2)} X ( 1 ) , X ( 2 ) , e due flussi di output Y ‾ ( 1 ) , Y ‾ ( 2 ) \mathbf{\overline{Y}}^{(1)}, \mathbf{\overline{Y}}^{(2)} Y ( 1 ) , Y ( 2 ) . La prima parte residuale Z \mathbf{Z} Z viene calcolata dal primo flusso di output Z = G ( X ( 1 ) ) \mathbf{Z} = G(\mathbf{X}^{(1)}) Z = G ( X ( 1 ) ) e successivamente aggiunta all’input del secondo flusso di input, in modo che Z ‾ = Z + X ( 2 ) \mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}^{(2)} Z = Z + X ( 2 ) . Allo stesso modo, la parte residuale Y = F ( Z ‾ ) \mathbf{Y} = F(\mathbf{\overline{Z}}) Y = F ( Z ) viene aggiunta nuovamente al primo flusso di input, in modo che i due flussi di output siano definiti da Y ( 1 ) = Y + X ( 1 ) \mathbf{Y}^{(1)} = \mathbf{Y} + \mathbf{X}^{(1)} Y ( 1 ) = Y + X ( 1 ) e Y ( 2 ) = X ( 2 ) + Z = Z ‾ \mathbf{Y}^{(2)} = \mathbf{X}^{(2)} + \mathbf{Z} = \mathbf{\overline{Z}} Y ( 2 ) = X ( 2 ) + Z = Z .
Il layer di transformer reversibile può essere visualizzato per x 1 , … , x 16 \mathbf{x}_1, \ldots, \mathbf{x}_{16} x 1 , … , x 1 6 come segue.
![]()
Come si può vedere, gli output Y ‾ ( 1 ) , Y ‾ ( 2 ) \mathbf{\overline{Y}}^{(1)}, \mathbf{\overline{Y}}^{(2)} Y ( 1 ) , Y ( 2 ) vengono calcolati in un modo molto simile a Y ‾ \mathbf{\overline{Y}} Y del layer non reversibile, ma sono matematicamente diversi. Gli autori di Reformer osservano in alcuni esperimenti iniziali che le prestazioni di un modello di transformer reversibile corrispondono alle prestazioni di un modello di transformer standard. La prima differenza visibile rispetto al layer di transformer standard è che ci sono due flussi di input e output 3 ^{3} 3 , che inizialmente aumentano leggermente la memoria richiesta per il passaggio in avanti. L’architettura a due flussi è però cruciale per non dover salvare nessuna attivazione durante il passaggio in avanti. Spieghiamo. Per la backpropagation, il layer di transformer reversibile deve calcolare i gradienti ∂ G \partial G ∂ G e ∂ F \partial F ∂ F . Oltre ai gradienti ∂ Y \partial \mathbf{Y} ∂ Y e ∂ Z \partial \mathbf{Z} ∂ Z che possono essere calcolati al volo, i valori tensoriali Y \mathbf{Y} Y , Z ‾ \mathbf{\overline{Z}} Z devono essere noti per ∂ F \partial F ∂ F e i valori tensoriali Z \mathbf{Z} Z e X ( 1 ) \mathbf{X}^{(1)} X ( 1 ) per ∂ G \partial G ∂ G per far funzionare l’autodifferenziazione.
Se assumiamo di conoscere Y ‾ ( 1 ) , Y ‾ ( 2 ) \mathbf{\overline{Y}}^{(1)}, \mathbf{\overline{Y}}^{(2)} Y ( 1 ) , Y ( 2 ) , si può facilmente dedurre dal grafico che è possibile calcolare X ( 1 ) , X ( 2 ) \mathbf{X}^{(1)}, \mathbf{X}^{(2)} X ( 1 ) , X ( 2 ) come segue. X ( 1 ) = F ( Y ‾ ( 1 ) ) − Y ‾ ( 1 ) \mathbf{X}^{(1)} = F(\mathbf{\overline{Y}}^{(1)}) – \mathbf{\overline{Y}}^{(1)} X ( 1 ) = F ( Y ( 1 ) ) − Y ( 1 ) . Ottimo, ora che X ( 1 ) \mathbf{X}^{(1)} X ( 1 ) è noto, X ( 2 ) \mathbf{X}^{(2)} X ( 2 ) può essere calcolato come X ( 2 ) = Y ‾ ( 1 ) − G ( X ( 1 ) ) \mathbf{X}^{(2)} = \mathbf{\overline{Y}}^{(1)} – G(\mathbf{X}^{(1)}) X ( 2 ) = Y ( 1 ) − G ( X ( 1 ) ) . Bene, ora Z \mathbf{Z} Z e Y \mathbf{Y} Y sono facili da calcolare tramite Y = Y ‾ ( 1 ) − X ( 1 ) \mathbf{Y} = \mathbf{\overline{Y}}^{(1)} – \mathbf{X}^{(1)} Y = Y ( 1 ) − X ( 1 ) e Z = Y ‾ ( 2 ) − X ( 2 ) \mathbf{Z} = \mathbf{\overline{Y}}^{(2)} – \mathbf{X}^{(2)} Z = Y ( 2 ) − X ( 2 ) . Quindi, in conclusione, se solo le uscite Y ‾ ( 1 ) , Y ‾ ( 2 ) \mathbf{\overline{Y}}^{(1)}, \mathbf{\overline{Y}}^{(2)} Y ( 1 ) , Y ( 2 ) dell’ ultimo strato trasformatore reversibile vengono memorizzate durante il passaggio in avanti, tutte le altre attivazioni rilevanti possono essere derivate facendo uso di G G G e F F F durante il passaggio all’indietro e passando X ( 1 ) \mathbf{X}^{(1)} X ( 1 ) e X ( 2 ) \mathbf{X}^{(2)} X ( 2 ) . L’onere di due passaggi in avanti di G G G e F F F per ogni strato trasformatore reversibile durante la retropropagazione viene scambiato con il non dover memorizzare nessuna attivazione durante il passaggio in avanti. Non è male!
Nota : Da poco tempo, i principali framework di deep learning hanno rilasciato codice che consente di memorizzare solo determinate attivazioni e ricalcolare quelle più grandi durante la propagazione all’indietro (Tensoflow qui e PyTorch qui ). Per gli strati reversibili standard, ciò significa ancora che almeno un’attivazione deve essere memorizzata per ogni strato del trasformatore, ma definendo quali attivazioni possono essere ricalcolate dinamicamente è possibile risparmiare molta memoria.
1 ^{1} 1 Nei due precedenti paragrafi, abbiamo omesso gli strati di normalizzazione del livello che precedono sia lo strato di autoattenzione che gli strati lineari. Il lettore dovrebbe sapere che sia X \mathbf{X} X che Z ‾ \mathbf{\overline{Z}} Z vengono entrambi elaborati da normalizzazione del livello prima di essere alimentati rispettivamente a autoattenzione e agli strati lineari. 2 ^{2} 2 Mentre nel progetto la dimensione di Q K \mathbf{Q}\mathbf{K} Q K è scritta come n × n n \times n n × n , in uno strato di autoattenzione LSH o autoattenzione locale la dimensione sarebbe solo n × l c × n h n \times l_{c} \times n_{h} n × l c × n h o n × l c n \times l_{c} n × l c rispettivamente, con l c l_{c} l c che rappresenta la lunghezza del chunk e n h n_{h} n h il numero di hash. 3 ^{3} 3 Nel primo strato trasformatore reversibile, X ( 2 ) \mathbf{X}^{(2)} X ( 2 ) viene impostato uguale a X ( 1 ) \mathbf{X}^{(1)} X ( 1 ) .
Benchmark
Per misurare l’effetto dei livelli residui reversibili, confrontiamo il consumo di memoria di BERT con Reformer durante l’addestramento per un numero crescente di livelli.
#@title Installazioni e importazioni
# Installazione dei pacchetti
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, BertConfig, PyTorchBenchmark, PyTorchBenchmarkArgumentsMisuriamo la memoria richiesta per il modello BERT standard bert-base-uncased aumentando il numero di livelli da 4 a 12.
config_4_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=4)
config_8_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=8)
config_12_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=12)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Bert-4-Layers", "Bert-8-Layers", "Bert-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_bert, config_8_layers_bert, config_12_layers_bert], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Download', max=433.0, style=ProgressStyle(description_…
1 / 3
2 / 3
3 / 3
==================== ADDESTRAMENTO - MEMORIA - RISULTATI ====================
--------------------------------------------------------------------------------
Nome Modello Batch Size Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Bert-4-Layers 8 512 4103
Bert-8-Layers 8 512 5759
Bert-12-Layers 8 512 7415
--------------------------------------------------------------------------------Si può notare che l’aggiunta di un singolo livello di BERT aumenta linearmente la memoria richiesta di oltre 400MB.
config_4_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=4, num_hashes=1)
config_8_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=8, num_hashes=1)
config_12_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=12, num_hashes=1)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-4-Layers", "Reformer-8-Layers", "Reformer-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_reformer, config_8_layers_reformer, config_12_layers_reformer], args=benchmark_args)
result = benchmark.run()
1 / 3
2 / 3
3 / 3
==================== ADDESTRAMENTO - MEMORIA - RISULTATI ====================
--------------------------------------------------------------------------------
Nome Modello Batch Size Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Reformer-4-Layers 8 512 4607
Reformer-8-Layers 8 512 4987
Reformer-12-Layers 8 512 5367
--------------------------------------------------------------------------------D’altra parte, per Reformer, l’aggiunta di un livello aggiunge significativamente meno memoria nella pratica. L’aggiunta di un singolo livello aumenta la memoria richiesta in media di meno di 100MB, quindi un modello Reformer a 12 livelli più grande, reformer-enwik8, richiede meno memoria rispetto a un modello BERT a 12 livelli, bert-base-uncased.
4. Codifiche Posizionali Assiali
Reformer rende possibile elaborare sequenze di input molto lunghe. Tuttavia, per sequenze di input così lunghe, le normali matrici di pesi di encoding posizionale da sole userebbero più di 1GB per memorizzare i loro pesi. Per evitare tali matrici di encoding posizionale così grandi, il codice ufficiale di Reformer ha introdotto le Codifiche Posizionali Assiali.
Importante: Le Codifiche Posizionali Assiali non sono spiegate nel paper ufficiale, ma possono essere ben comprese guardando il codice e parlando con gli autori.
Codifica Posizionale Assiale nel Reformer
I Transformer hanno bisogno di codifiche posizionali per tener conto dell’ordine delle parole nell’input perché i livelli di autoattenzione non hanno una nozione di ordine. Di solito, le codifiche posizionali sono definite da una semplice matrice di ricerca E = [ e 1 , … , e n max ] \mathbf{E} = \left[\mathbf{e}_1, \ldots, \mathbf{e}_{n_\text{max}}\right] E = [ e 1 , … , e n max ]. Il vettore di codifica posizionale e i \mathbf{e}_{i} e i viene quindi semplicemente aggiunto al vettore di input i-esimo x i + e i \mathbf{x}_{i} + \mathbf{e}_{i} x i + e i in modo che il modello possa distinguere se un vettore di input (detto anche token) si trova nella posizione i i i o j j j. Per ogni posizione di input, il modello deve essere in grado di cercare il vettore di codifica posizionale corrispondente in modo che la dimensione di E \mathbf{E} E sia definita dalla lunghezza massima dei vettori di input che il modello può elaborare config.max_position_embeddings, cioè n max n_\text{max} n max , e config.hidden_size, cioè d h d_{h} d h dei vettori di input.
Assumendo d h = 4 d_{h}=4 d h = 4 e n max = 49 n_\text{max}=49 n max = 4 9, una matrice di codifica posizionale del genere può essere visualizzata come segue:

Qui mostriamo solo le codifiche posizionali e 1 \mathbf{e}_{1} e 1 , e 2 \mathbf{e}_{2} e 2 e e 49 \mathbf{e}_{49} e 4 9 ognuna di dimensione, nota anche come altezza 4.
Immaginiamo di voler addestrare un modello Reformer su sequenze di lunghezza fino a 0,5M di token e un vettore di input config.hidden_size di 1024 (vedi notebook qui ). Le relative codifiche posizionali hanno una dimensione di 0,5 M × 1024 ∼ 512 M 0.5M \times 1024 \sim 512M 0 . 5 M × 1 0 2 4 ∼ 5 1 2 M parametri, che corrispondono a una dimensione di 2GB.
Codifiche posizionali di questo tipo utilizzerebbero una quantità di memoria eccessivamente grande sia durante il caricamento del modello in memoria che durante il salvataggio del modello su disco rigido.
Gli autori del Reformer sono riusciti a ridurre drasticamente le dimensioni delle codifiche posizionali tagliando la dimensione config.hidden_size a metà e scomponendo in modo intelligente la dimensione n max n_\text{max} n max . Nel Transformer, l’utente può decidere in quale forma n max n_\text{max} n max può essere scomposto impostando config.axial_pos_shape su una lista appropriata di due valori n max 1 n_\text{max}^1 n max 1 e n max 2 n_\text{max}^2 n max 2 in modo che n max 1 × n max 2 = n max n_\text{max}^1 \times n_\text{max}^2 = n_\text{max} n max 1 × n max 2 = n max . Impostando config.axial_pos_embds_dim su una lista appropriata di due valori d h 1 d_{h}^{1} d h 1 e d h 2 d_{h}^2 d h 2 in modo che d h 1 + d h 2 = d h d_{h}^1 + d_{h}^2 = d_{h} d h 1 + d h 2 = d h , l’utente può decidere come tagliare la dimensione della dimensione del hidden size. Ora, vediamo e spieghiamo in modo più intuitivo.
Si può pensare di scomporre n max n_{\text{max}} n max piegando la dimensione in un terzo asse, che viene mostrato di seguito per la scomposizione config.axial_pos_shape = [7, 7]:
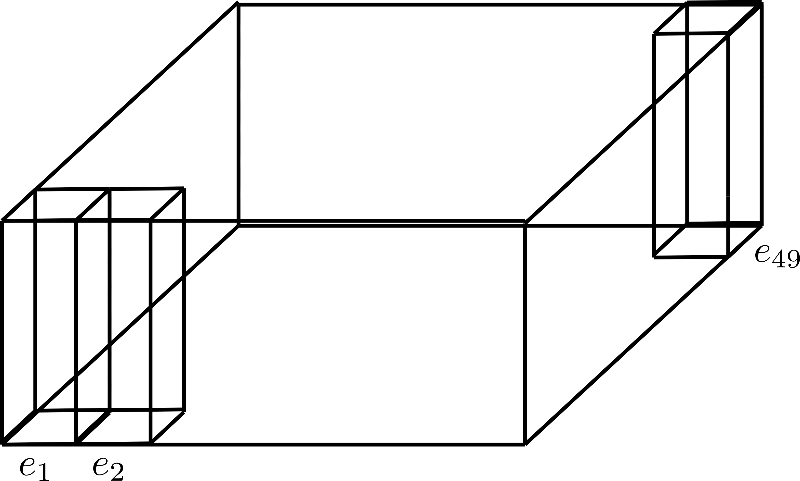
Ognuno dei tre prismi rettangolari in piedi corrisponde a uno dei vettori di codifica e 1 , e 2 , e 49 \mathbf{e}_{1}, \mathbf{e}_{2}, \mathbf{e}_{49} e 1 , e 2 , e 4 9 , ma possiamo vedere che i 49 vettori di codifica sono divisi in 7 righe di 7 vettori ciascuna. Ora l’idea è quella di utilizzare solo una riga di 7 vettori di codifica e espandere quei vettori per le altre 6 righe, riutilizzando essenzialmente i loro valori. Poiché è sconsigliato avere gli stessi valori per diversi vettori di codifica, ogni vettore di dimensione (detto anche altezza) config.hidden_size=4 viene diviso nel vettore di codifica inferiore e down \mathbf{e}_\text{down} e down di dimensione 1 1 1 e nel vettore di codifica superiore e up \mathbf{e}_\text{up} e up di dimensione 3 3 3 , in modo che la parte inferiore possa essere espansa lungo la dimensione della riga e la parte superiore possa essere espansa lungo la dimensione della colonna. Vediamolo con maggiore chiarezza.
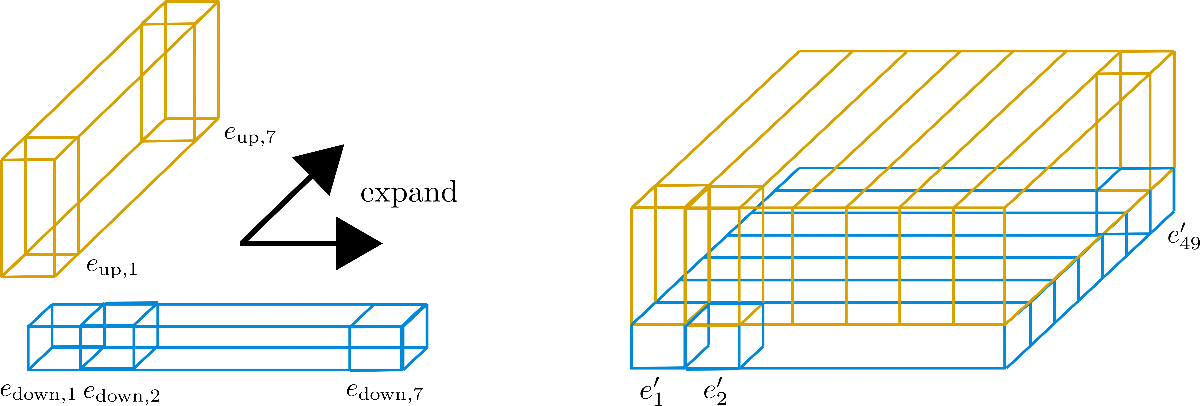
Possiamo vedere che abbiamo diviso i vettori di embedding in e down \mathbf{e}_\text{down} e down (in blu) e e up \mathbf{e}_\text{up} e up (in giallo). Ora per i “sotto”-vettori E down = [ e down , 1 , … , e down , 49 ] \mathbf{E}_\text{down} = \left[\mathbf{e}_{\text{down},1}, \ldots, \mathbf{e}_{\text{down},49}\right] E down = [ e down , 1 , … , e down , 4 9 ] viene mantenuta solo la prima riga, cioè la larghezza nel grafico, di 7 7 7 e viene espansa lungo la dimensione della colonna, cioè la profondità del grafico. Al contrario, per i “sotto”-vettori E up = [ e up , 1 , … , e up , 49 ] \mathbf{E}_\text{up} = \left[\mathbf{e}_{\text{up},1}, \ldots, \mathbf{e}_{\text{up},49}\right] E up = [ e up , 1 , … , e up , 4 9 ] viene mantenuta solo la prima colonna di 7 7 7 e viene espansa lungo la dimensione della riga. I vettori di embedding risultanti e ′ i \mathbf{e’}_{i} e ′ i corrispondono a
e ′ i = [ [ e down, i % n max 1 ] T , [ e up, ⌊ i n max 2 ⌋ ] T ] T \mathbf{e’}_{i} = \left[ \left[\mathbf{e}_{\text{down, } i \% n_\text{max}^1}\right]^T, \left[\mathbf{e}_{\text{up, } \left \lfloor{\frac{i}{{n}^2_{\text{max}}}}\right \rfloor} \right]^T \right]^T e ′ i = ⎣ ⎢ ⎢ ⎡ [ e down, i % n max 1 ] T , ⎣ ⎢ ⎡ e up, ⌊ n max 2 i ⌋ ⎦ ⎥ ⎤ T ⎦ ⎥ ⎥ ⎤ T
dove n max 1 = 7 n_\text{max}^1 = 7 n max 1 = 7 e n max 2 = 7 n_\text{max}^2 = 7 n max 2 = 7 nel nostro esempio. Queste nuove codifiche E ′ = [ e ′ 1 , … , e ′ n max ] \mathbf{E’} = \left[\mathbf{e’}_{1}, \ldots, \mathbf{e’}_{n_\text{max}}\right] E ′ = [ e ′ 1 , … , e ′ n max ] sono chiamate Codifiche di Posizione Assiale.
In seguito, queste codifiche di posizione assiale sono illustrate in modo più dettagliato per il nostro esempio.
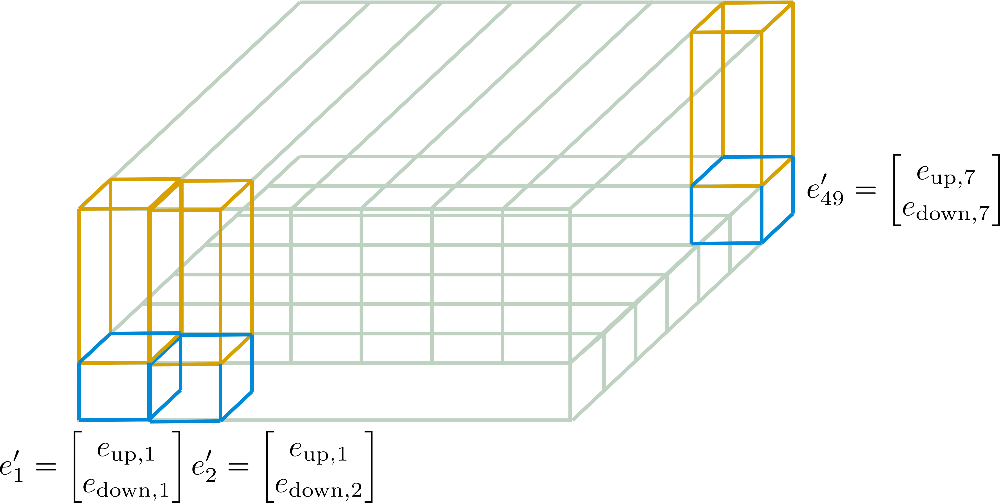
Ora dovrebbe essere più comprensibile come i vettori di codifica posizionale finali E ′ \mathbf{E’} E ′ sono calcolati solo a partire da E down \mathbf{E}_{\text{down}} E down di dimensione d h 1 × n max 1 d_{h}^1 \times n_{\text{max}^1} d h 1 × n max 1 e E up \mathbf{E}_{\text{up}} E up di dimensione d h 2 × n max 2 d_{h}^2 \times n_{\text{max}}^2 d h 2 × n max 2 .
L’aspetto cruciale da notare qui è che le Codifiche Posizionali Assiali si assicurano che nessuno dei vettori [ e ′ 1 , … , e ′ n max ] \left[\mathbf{e’}_1, \ldots, \mathbf{e’}_{n_{\text{max}}}\right] [ e ′ 1 , … , e ′ n max ] siano uguali tra loro per design e che la dimensione complessiva della matrice di codifica sia ridotta da n max × d h n_{\text{max}} \times d_{h} n max × d h a n max 1 × d h 1 + n max 2 × d h 2 n_{\text{max}}^1 \times d_{h}^1 + n_\text{max}^2 \times d_{h}^2 n max 1 × d h 1 + n max 2 × d h 2 . Consentendo a ciascun vettore di codifica posizionale assiale di essere diverso per design, il modello ha molta più flessibilità nel imparare rappresentazioni posizionali efficienti se le codifiche posizionali assiali sono apprese dal modello.
Per dimostrare la drastica riduzione di dimensione, supponiamo di aver impostato config.axial_pos_shape = [1024, 512] e config.axial_pos_embds_dim = [512, 512] per un modello Reformer che può elaborare input fino a una lunghezza di 0,5 milioni di token. La matrice di codifica posizionale risultante avrebbe avuto una dimensione di solo 1024 × 512 + 512 × 512 ∼ 800 K 1024 \times 512 + 512 \times 512 \sim 800K 1 0 2 4 × 5 1 2 + 5 1 2 × 5 1 2 ∼ 8 0 0 K parametri, che corrisponde a circa 3MB. Questa è una drastica riduzione rispetto ai 2GB che una matrice di codifica posizionale standard richiederebbe in questo caso.
Per una spiegazione più sintetica e matematica, fare riferimento alla documentazione di 🤗Transformers qui.
Benchmark
Infine, confrontiamo anche il consumo di memoria massimo delle codifiche posizionali convenzionali con le codifiche posizionali assiali.
#@title Installazioni e importazioni
# installazioni pip
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments, ReformerModelLe codifiche posizionali dipendono solo da due parametri di configurazione: la lunghezza massima consentita delle sequenze di input config.max_position_embeddings e config.hidden_size. Utilizziamo un modello che spinge la lunghezza massima consentita delle sequenze di input a mezzo milione di token, chiamato google/reformer-crime-and-punishment, per vedere l’effetto dell’utilizzo delle codifiche posizionali assiali.
Per cominciare, confrontiamo la forma delle codifiche di posizione assiale con le codifiche di posizione standard e il numero di parametri nel modello.
config_no_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=False) # disattiva le codifiche posizionali assiali
config_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=True, axial_pos_embds_dim=(64, 192), axial_pos_shape=(512, 1024)) # abilita le codifiche posizionali assiali
print("Codifiche posizionali predefinite")
print(20 * '-')
model = ReformerModel(config_no_pos_axial_embeds)
print(f"Forma delle codifiche posizionali: {model.embeddings.position_embeddings}")
print(f"Numero di parametri del modello: {model.num_parameters()}")
print(20 * '-' + '\n\n')
print("Codifiche posizionali assiali")
print(20 * '-')
model = ReformerModel(config_pos_axial_embeds)
print(f"Forma delle codifiche posizionali: {model.embeddings.position_embeddings}")
print(f"Numero di parametri del modello: {model.num_parameters()}")
print(20 * '-' + '\n\n')
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1151.0, style=ProgressStyle(description…
Codifiche posizionali predefinite
--------------------
Forma delle codifiche posizionali: PositionEmbeddings(
(embedding): Embedding(524288, 256)
)
Numero di parametri del modello: 136572416
--------------------
Codifiche posizionali assiali
--------------------
Forma delle codifiche posizionali: AxialPositionEmbeddings(
(weights): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 512x1x64]
(1): Parameter containing: [torch.FloatTensor of size 1x1024x192]
)
)
Numero di parametri del modello: 2584064
--------------------Dopo aver letto la teoria, la forma dei pesi di codifica posizionale assiale non dovrebbe sorprendere il lettore.
Riguardo ai risultati, si può vedere che per modelli in grado di elaborare sequenze di input così lunghe, non è pratico utilizzare codifiche posizionali predefinite. Nel caso di google/reformer-crime-and-punishment, le codifiche posizionali standard da sole contengono più di 100 milioni di parametri. Le codifiche posizionali assiali riducono questo numero a poco più di 200.000.
Infine, confrontiamo anche la memoria richiesta durante l’elaborazione.
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-No-Axial-Pos-Embeddings", "Reformer-Axial-Pos-Embeddings"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_pos_axial_embeds, config_pos_axial_embeds], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Nome Modello Dimensione Batch Lunghezza Seq Memoria in MB
--------------------------------------------------------------------------------
Reformer-No-Axial-Pos-Embeddin 8 512 959
Reformer-Axial-Pos-Embeddings 8 512 447
--------------------------------------------------------------------------------Si può vedere che l’utilizzo di embedding posizionali assiali riduce il requisito di memoria a circa la metà nel caso di google/reformer-crime-and-punishment.