Matrici sparse a blocchi per modelli di linguaggio più piccoli e più veloci
Sparse block matrices for smaller and faster language models.
Risparmiare spazio e tempo, un zero alla volta
In precedenti post del blog abbiamo introdotto le matrici sparse e ciò che possono fare per migliorare le reti neurali.
L’assunzione di base è che i livelli densi completi spesso sono eccessivi e possono essere potati senza una significativa perdita di precisione. In alcuni casi, i livelli lineari sparsi possono persino migliorare la precisione e/o la generalizzazione.
Il problema principale è che il codice attualmente disponibile che supporta il calcolo con algebra sparsa è gravemente carente in efficienza. Siamo ancora in attesa del supporto ufficiale di PyTorch.
Ecco perché abbiamo esaurito la pazienza e abbiamo dedicato del tempo quest’estate per affrontare questa “lacuna”. Oggi, siamo entusiasti di rilasciare l’estensione pytorch_block_sparse.
- Modelli di codificatori-decodificatori basati su Transformer
- Ricerca degli iperparametri con Transformers e Ray Tune
- Portare il sistema di traduzione fairseq wmt19 su transformers
Da sola, o ancora meglio combinata con altri metodi come la distillazione e la quantizzazione, questa libreria permette di ottenere reti che sono contemporaneamente più piccole e più veloci, una cosa che Hugging Face considera cruciale per consentire a chiunque di utilizzare reti neurali in produzione a basso costo e per migliorare l’esperienza dell’utente finale.
Utilizzo
Il modulo BlockSparseLinear fornito è un sostituto plug-and-play per torch.nn.Linear, ed è semplice utilizzarlo nei tuoi modelli:
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinear
...
# self.fc = nn.Linear(1024, 256)
self.fc = BlockSparseLinear(1024, 256, densità=0.1)L’estensione fornisce anche un BlockSparseModelPatcher che permette di modificare un modello esistente “al volo”, come mostrato in questo notebook di esempio. Tale modello può poi essere addestrato normalmente, senza alcuna modifica nel codice sorgente del modello.
NVIDIA CUTLASS
Questa estensione si basa sulla dimostrazione di concetto cutlass tilesparse di Yulhwa Kim.
Utilizza template C++ CUDA per la moltiplicazione di matrici sparse a blocchi basata su CUTLASS.
CUTLASS è una collezione di template CUDA C++ per l’implementazione di kernel CUDA ad alte prestazioni. Con CUTLASS, è possibile avvicinarsi alle prestazioni di cuBLAS su kernel personalizzati senza ricorrere al codice assembly.
Le versioni più recenti includono tutti i primitivi Ampere Tensor Core, fornendo accelerazioni di velocità x10 o superiori con una limitata perdita di precisione. Le prossime versioni di pytorch_block_sparse faranno uso di questi primitivi, in quanto la sparsità a blocchi è compatibile al 100% con i requisiti dei Tensor Core.
Prestazioni
Nello stato attuale della libreria, le prestazioni per le matrici sparse sono circa due volte più lente rispetto alle controparti dense ottimizzate con cuBLAS, ma siamo fiduciosi di poter migliorare questo aspetto in futuro.
Questo rappresenta un enorme miglioramento rispetto alle matrici sparse di PyTorch: la loro implementazione attuale è un ordine di grandezza più lenta rispetto a quella densa.
Ma il punto più importante è che il guadagno di prestazioni nell’utilizzo di matrici sparse aumenta con la sparsità, quindi una matrice con sparsità del 75% è approssimativamente 2 volte più veloce dell’equivalente denso.
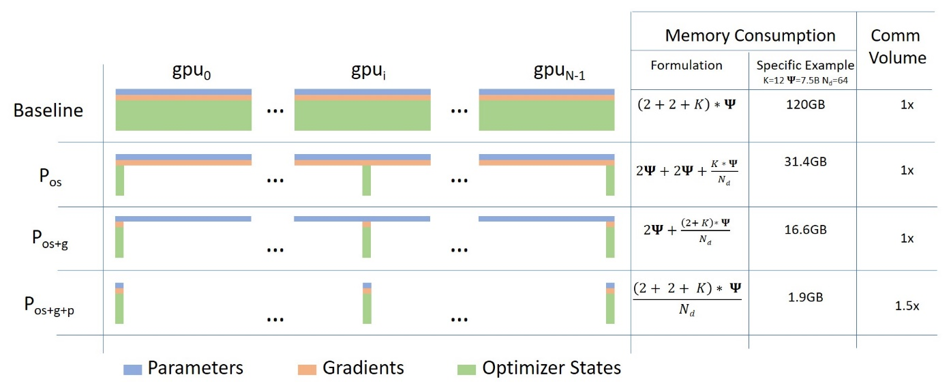
I risparmi di memoria sono ancora più significativi: per una sparsità del 75%, il consumo di memoria si riduce di un fattore 4x, come ci si potrebbe aspettare.
Lavori futuri
Riuscire ad addestrare efficacemente livelli lineari blocchi sparsi è stato solo il primo passo. Attualmente, il pattern di sparsità è fisso all’inizializzazione, e naturalmente ottimizzarlo durante l’apprendimento porterà a notevoli miglioramenti.
Quindi, nelle future versioni, potrai aspettarti strumenti per misurare l'”utilità” dei parametri al fine di ottimizzare il pattern di sparsità. Le sparsità a blocchi del 50% di NVIDIA Ampere probabilmente porteranno a un ulteriore significativo guadagno di prestazioni, proprio come avviene passando a versioni più recenti di CUTLASS.
Quindi, rimanete sintonizzati per ulteriori interessanti novità sulla sparsità in un futuro prossimo!