Creazione di animazioni per mostrare 4 algoritmi di clustering basati su centroidi utilizzando Python e Sklearn
Creazione di animazioni per 4 algoritmi di clustering con Python e Sklearn
Usando la visualizzazione dei dati e le animazioni per capire il processo di 4 algoritmi di clustering basati sui centroidi.
Analisi di clustering
L’analisi di clustering è una tecnica efficace di apprendimento automatico che raggruppa i dati in base alle loro somiglianze e differenze. I gruppi di dati ottenuti possono essere utilizzati per vari scopi, come segmentazione, strutturazione e decisioni.
Per eseguire l’analisi di clustering, sono disponibili molti metodi basati su diversi algoritmi. Questo articolo si concentrerà principalmente sul clustering basato sui centroidi, che è una tecnica comune e utile.
Clustering basato sui centroidi
In sostanza, la tecnica basata sui centroidi funziona calcolando ripetutamente per ottenere i centroidi ottimali (centri dei cluster) e quindi assegnando i punti dati ai più vicini.
A causa delle numerose iterazioni, la visualizzazione dei dati può essere utilizzata per esprimere ciò che accade durante il processo. Pertanto, lo scopo di questo articolo è creare animazioni per mostrare il processo basato sui centroidi con Python e Sklearn.
- Migliori strumenti di intelligenza artificiale per la produzione musicale 2023
- Kris Nagel, CEO di Sift – Serie di interviste
- Proteggi i tuoi progetti Python evita l’invocazione diretta di setup.py per una protezione definitiva del codice!
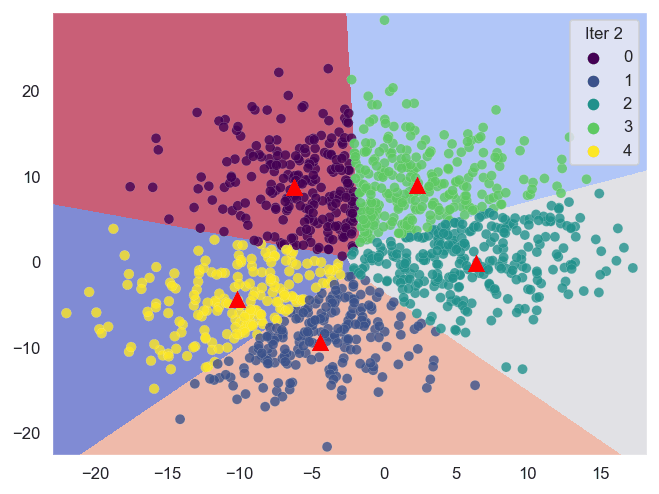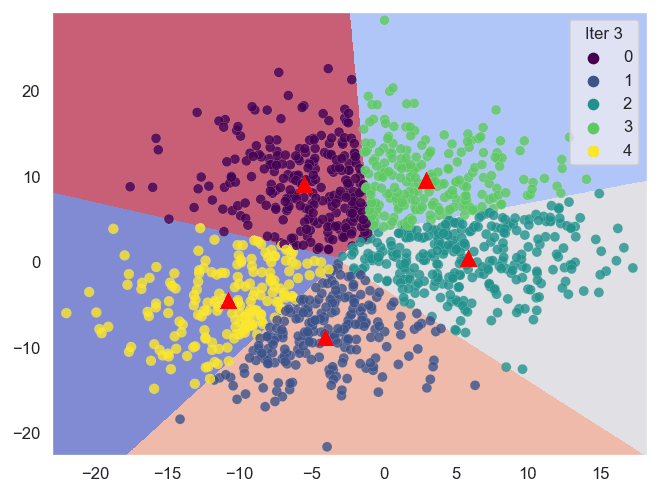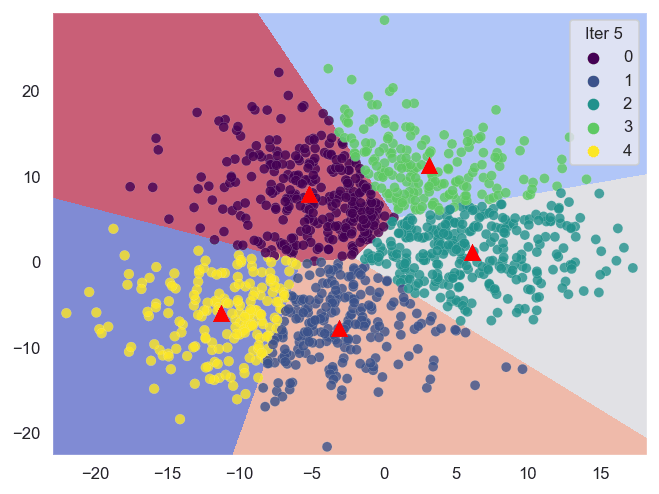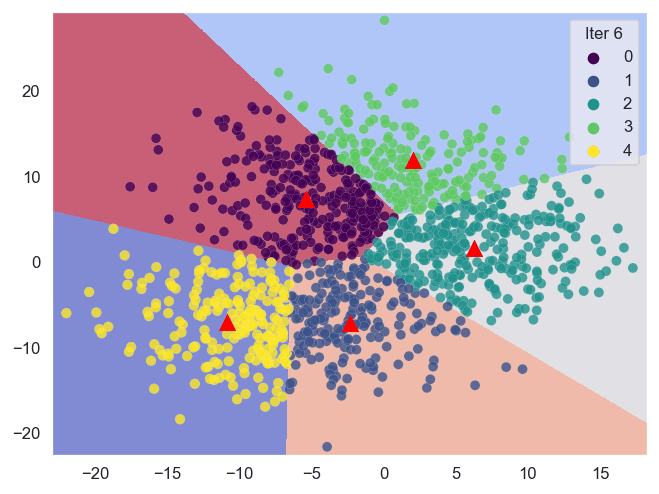
Sklearn (Scikit-learn) è una potente libreria che ci aiuta a eseguire l’analisi di clustering in modo efficiente. Di seguito sono riportate le tecniche di clustering basate sui centroidi con cui lavoreremo.
- Clustering K-means
- Clustering MiniBatch K-means
- Clustering Bisecting K-means
- Clustering Mean-Shift
Cominciamo
Ottenere i dati
Inizia importando le librerie.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsCome esempio, questo articolo utilizzerà un dataset generato, che può essere facilmente creato utilizzando make_blobs() di sklearn. Se hai il tuo dataset, questo passaggio può essere saltato.
from sklearn.datasets import make_blobsX, y...





