Sfrutta il potere dei database vettoriali influenzare i modelli di linguaggio con informazioni personalizzate.
Utilizza database vettoriali per personalizzare i modelli di linguaggio.
Potenzia i tuoi modelli di linguaggio con i database vettoriali! Personalizza i promp utilizzando i tuoi dati per modellare il comportamento di questi potenti modelli, dando loro un contesto. Integra informazioni personali per un’esperienza di generazione del linguaggio su misura.
In questo articolo, impareremo come due nuove tecnologie: i database vettoriali e i grandi modelli di linguaggio, possono lavorare insieme. Questa combinazione sta attualmente causando una significativa interruzione nell’industria tecnologica.
Spesso viene utilizzata per incorporare la propria documentazione o i database di conoscenza aziendali, su cui il modello di linguaggio non è stato addestrato. L’idea è garantire che tali informazioni siano prese in considerazione durante la generazione delle risposte del modello. Si tratta di fornire al modello di linguaggio l’accesso alle informazioni utili che possono migliorare o rendere più pertinenti le sue uscite, o entrambe.
Questo è il caso d’uso che esploreremo. Ecco i passaggi che seguiremo:
- Creare il database vettoriale utilizzando ChromaDB.
- Memorizzare le informazioni nel database.
- Ricavare informazioni tramite una query.
- Generare un prompt esteso utilizzando queste informazioni.
- Caricare un modello da Hugging Face.
- Passare il prompt al modello.
- Il modello fornirà una risposta, tenendo conto delle informazioni fornite.
Seguendo questi passaggi, possiamo utilizzare ChromaDB per aggiungere facilmente informazioni personali al processo decisionale del modello di linguaggio.
- Incontra I2D2 un nuovo framework di intelligenza artificiale per generare conoscenze generiche da modelli di linguaggio utilizzando decodifica vincolata e apprendimento mediante auto-imitazione
- Da ChatGPT a Pi, e ti dirò perché!
- Preparati per una rivoluzione sonora nell’IA il 2023 è l’anno delle onde sonore generative
In questo modo, possiamo ottenere risposte altamente personalizzate e pertinenti dal punto di vista contestuale.
Approfondiamo ogni passaggio e sblocchiamo il pieno potenziale di questo approccio!
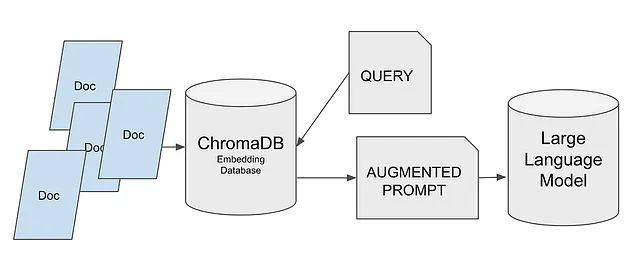
Ma prima di immergerci, facciamo una breve introduzione su come funzionano i database vettoriali.
Come funzionano i database vettoriali?
Prima di tutto, questi database memorizzano vettori, come suggerisce il loro nome. Dobbiamo trasformare il testo che abbiamo in informazioni che possono essere memorizzate in questi strumenti. In altre parole, dobbiamo convertire il nostro testo in vettori.
Esistono vari approcci disponibili, ma in sintesi, tutti convertono una sequenza di testo, che possono essere parole, sillabe o frasi, in vettori.
I vettori che otteniamo sono multidimensionali e naturalmente possiamo calcolare la differenza tra un vettore e un altro o cercare vettori che siano più vicini a uno specifico.
Con queste informazioni, possiamo capire come funziona in generale.
- Convertiamo il testo in vettori e li memorizziamo.
- Convertiamo il testo da cercare in vettori e li confrontiamo.
- Selezioniamo i vettori più vicini.
- Questi vettori vengono quindi convertiti nuovamente in testo e restituiti.
Dimentichiamoci delle ricerche di testo! Si tratta solo di confronti tra vettori.
Come avrai già intuito, il processo di conversione del testo in vettori dovrebbe essere lo stesso sia per il testo memorizzato che per il testo da cercare. Altrimenti, il confronto sarebbe privo di significato.
I database vettoriali stanno assumendo sempre più importanza, non solo per casi come il nostro in cui cerchiamo notizie correlate, ma anche per qualsiasi sistema di raccomandazione.
In effetti, i vettori sono essenzialmente rappresentazioni numeriche e non devono necessariamente originare da testo. Possiamo memorizzare film trasformati in vettori, insieme ai loro metadati, e cercarne di simili. Potremmo persino identificare modelli che ci permettano di consigliare film in base alle abitudini di visione dell’utente. Aspetta un attimo… potrebbe essere che Netflix li sta usando anche per il loro sistema di raccomandazione? Facciamo una scommessa?
Quale tecnologia utilizzeremo?
Per quanto riguarda il database, ho scelto ChromaDB. È uno dei database più recenti ad emergere ed è rapidamente diventato popolare. Vedrai che il suo utilizzo è estremamente semplice! Non dovremo preoccuparci molto perché ChromaDB si occupa della maggior parte del lavoro per noi. È una soluzione open-source che può essere integrata senza problemi con LangChain, il che è importante perché, in futuri articoli, utilizzeremo LangChain per costruire soluzioni sempre più complesse.
Otterremo il modello da Hugging Face. In particolare, ho usato dolly-v2–3b. Questa è la versione più piccola della famiglia di modelli Dolly. Suggerisco di utilizzare versioni più piccole dei modelli quando possibile.
Personalmente, mi diverto ad sperimentare con modelli diversi ogni volta che ne ho l’opportunità, e Hugging Face offre una vasta selezione di modelli tra cui scegliere.
Se vuoi provare un modello diverso, puoi cercarlo su Hugging Face e assicurarti che sia addestrato per la generazione di testo.

Cominciamo con il progetto!
Puoi trovare il codice in un Notebook su Kaggle, dove puoi forkarlo, eseguirlo e sperimentarci. È anche disponibile su GitHub in un repository dove conservo tutti i notebook del corso Large Language Models, così come i relativi articoli.
Usare un Vectorial DB per ottimizzare i prompts per LLM
Esplorare ed eseguire codice di machine learning con Kaggle Notebooks | Utilizzare dati da fonti dati multiple
www.kaggle.com
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuisci allo sviluppo di peremartra/Large-Language-Model-Notebooks-Course creando un account su GitHub.
github.com
Se sei interessato a seguire l’intero corso, è meglio iscriversi al Repository GitHub. In questo modo, riceverai notifiche di nuove lezioni o modifiche a quelle esistenti.
Importiamo le librerie necessarie.
Per iniziare, dovremo installare alcuni pacchetti Python:
- sentence-transformers: Questa libreria è necessaria per trasformare frasi in vettori di lunghezza fissa, ovvero per l’embedding.
- transformers: Questo pacchetto fornisce varie librerie e utility che facilitano il lavoro con modelli transformer. Anche se potremmo non usarlo direttamente, non installarlo causerà un messaggio di errore quando si lavora con il modello.
- chromadb: Il nostro database vettoriale. È facile da usare, open-source e veloce. È probabilmente il database vettoriale più ampiamente utilizzato per la memorizzazione di embedding.
Puoi installare questi pacchetti utilizzando i seguenti comandi:
!pip install sentence-transformers!pip install xformers!pip install chromadbLe seguenti due librerie ti saranno probabilmente familiari: Numpy e Pandas. Sono due delle librerie Python più utilizzate nella scienza dei dati.
Numpy è una libreria per il calcolo numerico che facilita il calcolo matematico.
Pandas, d’altra parte, è la libreria di riferimento per la manipolazione e l’analisi dei dati.
import numpy as np import pandas as pdCarica il dataset.
Ho preparato il notebook per lavorare con tre diversi dataset disponibili su Kaggle. Tutti i dataset contengono articoli di notizie ma in diversi formati. Due di essi contengono solo riassunti degli articoli, mentre il terzo include il testo completo degli articoli.
Topic Labeled News Dataset
108774 articoli di notizie etichettati con 8 argomenti (equilibrati)
www.kaggle.com
BBC News
Dataset in aggiornamento automatico – BBC News RSS Feeds
www.kaggle.com
MIT AI News Pubblicato fino al 2023
Tutte le notizie relative all’intelligenza artificiale pubblicate da MIT sul loro sito web.
www.kaggle.com
L’unico motivo per cui il notebook funziona con tre diversi dataset è quello di facilitare l’esperimento e vedere come la soluzione reagisce a input diversi. Sentiti libero di provare quanti dataset desideri. Si tratta di osservare e comprendere il comportamento e le prestazioni della soluzione con diverse fonti di dati.
Dato che lavoriamo con risorse limitate su piattaforme come Kaggle o Colab, ho impostato un limite sul numero di articoli di notizie da caricare. Questo limite è definito dalla variabile MAX_NEWS.
Il campo che contiene l’articolo di notizie è stato assegnato alla variabile DOCUMENT, mentre ciò che potrebbe essere considerato metadati o categorie è memorizzato nella variabile TOPIC. In questo modo, isoliamo il resto del notebook dal dataset specifico che scegliamo di utilizzare.
È sufficiente rimuovere il commento per il dataset che si desidera utilizzare.
news = pd.read_csv('/kaggle/input/topic-labeled-news-dataset/labelled_newscatcher_dataset.csv', sep=';')MAX_NEWS = 1000DOCUMENT="title"TOPIC="topic"#news = pd.read_csv('/kaggle/input/bbc-news/bbc_news.csv')#MAX_NEWS = 1000#DOCUMENT="description"#TOPIC="title"#news = pd.read_csv('/kaggle/input/mit-ai-news-published-till-2023/articles.csv')#MAX_NEWS = 100#DOCUMENT="Article Body"#TOPIC="Article Header"#Poiché si tratta solo di un corso, selezioniamo una piccola porzione di notizie.subset_news = news.head(MAX_NEWS)Importiamo e configuriamo il database dei vettori.
Prima di tutto, importeremo ChromaDB, seguito dalla sua classe Settings dal modulo di configurazione. Questa classe ci consente di modificare la configurazione del sistema ChromaDB e personalizzarne il comportamento.
import chromadbfrom chromadb.config import SettingsOra che abbiamo importato la libreria, creiamo un oggetto settings chiamando la classe Settings importata.
L’oggetto settings verrà creato con due parametri.
- chroma_db_impl: Indicheremo l’implementazione da utilizzare per il database e il formato in cui memorizzeremo i dati. Non entrerò nei dettagli di tutte le varie scelte, ma spiegherò le motivazioni dietro quelle che ho scelto: — Per l’implementazione, abbiamo selezionato “duckdb”. Offre ottime prestazioni poiché opera principalmente in memoria ed è completamente compatibile con SQL. — Per quanto riguarda il formato dei dati, useremo “parquet”. È la scelta ottimale per i dati tabulari. Parquet offre un buon rapporto di compressione e offre elevate prestazioni per la query e l’elaborazione dei dati.
- persist_directory: Questo parametro contiene il percorso in cui vogliamo salvare le informazioni. Se non lo specifichiamo, il database sarà in memoria e non persistente. Tuttavia, lavorare esclusivamente in memoria può causare problemi in ambienti cloud o collaborativi come Kaggle, in quanto potrebbe cercare di creare un file temporaneo.
settings_chroma = Settings(chroma_db_impl="duckdb+parquet", persist_directory='./input')chroma_client = chromadb.Client(settings_chroma)Lavorare con i dati in ChromaDB.
I dati in ChromaDB sono organizzati in collezioni. Ogni collezione deve avere un nome univoco, quindi se proviamo a creare una collezione utilizzando un nome esistente, verrà generato un errore.
Per ottenere questo, verificheremo se la collezione esiste nell’elenco delle collezioni ChromaDB. Se esiste, la elimineremo prima di crearla nuovamente. È importante notare che questo approccio è adatto per test e sperimentazioni in questo notebook. In un ambiente di produzione dovrebbe essere implementata una strategia diversa.
In alternativa, avremmo potuto creare tre collezioni separate, una per ogni dataset. Lascio questa idea qui, nel caso in cui si voglia modificare il notebook e adattarlo alle proprie preferenze.
collection_name = "news_collection"if len(chroma_client.list_collections()) > 0 and collection_name in [chroma_client.list_collections()[0].name]: chroma_client.delete_collection(name=collection_name)collection = chroma_client.create_collection(name=collection_name)Dopo aver creato la collezione, siamo pronti per aggiungere i nostri dati al database ChromaDB. Possiamo farlo chiamando la funzione `add` e fornendo il documento, i metadati e un identificatore univoco per ogni record.
Il documento può avere qualsiasi lunghezza e includerà l’intero contenuto del nostro documento. A seconda della lunghezza dei documenti che vogliamo memorizzare, possiamo considerare di dividerli in parti più piccole, come pagine o capitoli. Dobbiamo tenere presente che le informazioni restituite dal database verranno utilizzate per creare il contesto del nostro prompt, e che questi prompt hanno limitazioni in termini di lunghezza che possono raggiungere. Pertanto, è importante considerare il compromesso tra la lunghezza dei documenti e le limitazioni di lunghezza del prompt durante la progettazione del nostro sistema.
In questo esempio, useremo l’intera informazione del documento per creare il prompt. Tuttavia, in progetti più avanzati, possiamo utilizzare un altro modello per generare un riassunto delle informazioni restituite. Questo ci consente di creare un prompt con meno contenuti ma con maggiore pertinenza. Esploreremo ulteriormente questo approccio quando approfondiremo come funziona LangChain.
I metadati non vengono utilizzati nella ricerca vettoriale stessa. I metadati vengono utilizzati per memorizzare categorie o informazioni aggiuntive che possono essere utilizzate nel post-filtraggio per raffinare i risultati.
Per quanto riguarda l’identificatore univoco, possiamo generarne facilmente uno usando Python. Può essere semplice come generare numeri da 0 a MAX_RANGE.
collection.add( documents=subset_news[DOCUMENT].tolist(), metadatas=[{TOPIC: topic} for topic in subset_news[TOPIC].tolist()], ids=[f"id{x}" for x in range(MAX_NEWS)],)Una volta che abbiamo le informazioni memorizzate in ChromaDB, possiamo eseguire query e recuperare documenti che corrispondono all’argomento desiderato o alla query di ricerca.
Come accennato in precedenza, i risultati vengono restituiti in base alla similarità tra i termini di ricerca e il contenuto dei documenti.
È importante notare che i metadati non vengono utilizzati nel processo di ricerca. Il confronto viene effettuato unicamente in base al contenuto del documento stesso.
results = collection.query(query_texts=["laptop"], n_results=10 )print(results)Nel parametro `n_results`, specifichiamo il numero massimo di documenti che vogliamo che vengano restituiti.
Vediamo la risposta:
{‘ids’: [[‘id173’, ‘id829’, ‘id117’, ‘id535’, ‘id141’, ‘id218’, ‘id390’, ‘id273’, ‘id56’, ‘id900’]], ‘embeddings’: None, ‘documents’: [[‘The Legendary Toshiba is Officially Done With Making Laptops’, ‘3 gaming laptop deals you can’t afford to miss today’, ‘Lenovo and HP control half of the global laptop market’, ‘Asus ROG Zephyrus G14 gaming laptop announced in India’, ‘Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)’, “Apple’s Next MacBook Could Be the Cheapest in Company’s History”, “Features of Huawei’s Desktop Computer Revealed”, ‘Redmi to launch its first gaming laptop on August 14: Here are all the details’, ‘Toshiba shuts the lid on laptops after 35 years’, ‘This is the cheapest Windows PC by a mile and it even has a spare SSD slot’]], ‘metadatas’: [[{‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}]], ‘distances’: [[0.8593593835830688, 1.02944016456604, 1.0793330669403076, 1.093000888824463, 1.1329681873321533, 1.2130440473556519, 1.2143317461013794, 1.216413974761963, 1.2220635414123535, 1.2754170894622803]]}
Come possiamo vedere, ha restituito 10 articoli di notizie. Sono tutti molto brevi ma riguardano i laptop. Curiosamente, non tutti contengono la parola “laptop”. Come è possibile?
Immagina che i vettori siano rappresentati in uno spazio multidimensionale, dove ogni vettore rappresenta un punto in quel spazio. La similarità tra vettori è determinata misurando la distanza tra questi punti. Immaginiamo uno spazio bidimensionale e prendiamo una delle frasi restituite come esempio per rappresentare le parole in quel spazio.
‘Acer Swift 3 con CPU Intel Ice Lake di decima generazione, schermo 2K e altro ancora lanciato in India a INR 64999 (865 dollari statunitensi)’
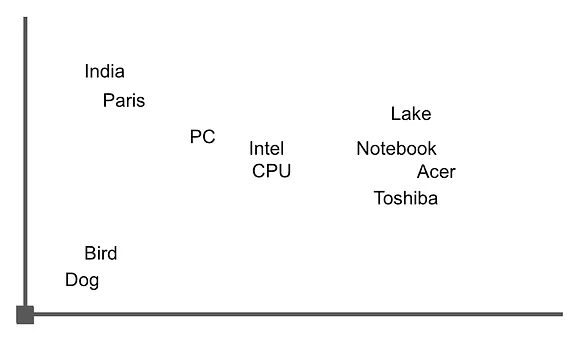
Il grafico potrebbe assomigliare a questa immagine, dove possiamo vedere che le parole legate a “notebook” sono raggruppate vicine tra loro. Calcolando la distanza tra di esse utilizzando l’aritmetica vettoriale, possiamo recuperare frasi o documenti che contengono queste parole.
Ora che abbiamo i dati e una comprensione di base del funzionamento della ricerca, possiamo iniziare a lavorare con il modello.
Carichiamo il modello da Hugging Face e creiamo il promemoria.
Ora è il momento di iniziare a lavorare con le librerie dell’universo Transformers. La popolarissima libreria mantenuta da Hugging Face fornisce accesso a un incredibile numero di modelli.
Importiamo le seguenti utility:
- AutoTokenizer: Questo strumento viene utilizzato per la tokenizzazione del testo ed è compatibile con molti dei modelli pre-addestrati disponibili nella libreria di Hugging Face.
- AutoModelForCasualLM: Fornisce un’interfaccia per l’utilizzo di modelli specificamente progettati per compiti di generazione di testo, come quelli basati su GPT. Nel nostro mini-progetto, stiamo utilizzando il modello databricks/dolly-v2-3b.
- Pipeline: Ciò ci consente di creare una pipeline che combina diverse attività.
Il modello che ho selezionato è dolly-v2-3b, che è il modello più piccolo della famiglia Dolly. Tuttavia, ha comunque 3 miliardi di parametri. Questo modello è più che sufficiente per il nostro piccolo esperimento e, in base ai test che ho condotto, sembra performare meglio in questo caso rispetto a GPT-2.
Tuttavia, ti incoraggio a sperimentare con modelli diversi. La mia unica raccomandazione è di iniziare con il modello più piccolo disponibile nella famiglia che scegli.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_id = "databricks/dolly-v2-3b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
lm_model = AutoModelForCausalLM.from_pretrained(model_id)Dopo queste righe, ora abbiamo il tokenizer nella variabile `tokenizer` e il modello in `lm_model`. Utilizzeremo queste variabili per creare la pipeline.
Nella chiamata della pipeline, dobbiamo specificare la dimensione della risposta, che limiterò a 256 token.
Forniamo anche il valore “auto” per il campo `device_map`. Ciò indica che il modello stesso deciderà se utilizzare la CPU o la GPU per la generazione di testo.
pipe = pipeline(
"text-generation",
model=lm_model,
tokenizer=tokenizer,
max_new_tokens=256,
device_map="auto",)Creazione del promemoria.
Per creare il promemoria, utilizzeremo il risultato della query eseguita in precedenza sul database. Nel nostro caso, ha restituito 10 articoli correlati alla parola “notebook”.
Il promemoria sarà composto da due parti:
1. Il contesto: qui forniremo le informazioni che il modello deve considerare oltre a ciò che già conosce. Nel nostro caso, sarà il risultato ottenuto dalla query al database.
2. La domanda dell’utente: questa è la parte in cui l’utente può inserire la sua domanda o query specifica.
Costruire il promemoria è semplice come concatenare insieme i testi desiderati per ottenere il promemoria desiderato.
question = "Posso comprare un laptop Toshiba?"
context = " ".join([f"#{str(i)}" for i in results["documents"][0]])
#context = context[0:5120]
prompt_template = f"Contesto rilevante: {context}\n\n Domanda dell'utente: {question}"
prompt_templateVediamo come appare il promemoria:
“Contesto rilevante: #The Legendary Toshiba ha ufficialmente smesso di produrre laptop #3 offerte di laptop per giochi che non puoi permetterti di perdere oggi #Lenovo e HP controllano la metà del mercato globale dei laptop #Asus ROG Zephyrus G14, laptop per giochi, annunciato in India #Acer Swift 3 con CPU Intel Ice Lake di decima generazione, schermo 2K e altro ancora, lanciato in India a INR 64999 (865 dollari statunitensi) #Il prossimo MacBook di Apple potrebbe essere il più economico nella storia dell’azienda #Caratteristiche del computer desktop di Huawei rivelate #Redmi lancerà il suo primo laptop per giochi il 14 agosto: ecco tutti i dettagli #Toshiba chiude il coperchio sui laptop dopo 35 anni #Questo è il PC Windows più economico di tutti i tempi ed ha persino uno slot SSD di riserva\n\n Domanda dell’utente: Posso comprare un laptop Toshiba?”
Come puoi vedere, tutto è piuttosto semplice! Non ci sono segreti. Semplicemente diciamo al modello: “Considera questo contesto che sto fornendo, seguito da un’interruzione di riga, e la domanda dell’utente è questa”.
Da qui in poi, il modello si prende il controllo e fa tutto il lavoro di interpretazione del prompt e generazione di una risposta corretta.
Otteniamo la risposta. Tutto ciò che dobbiamo fare è chiamare la pipeline precedentemente creata e passarle il prompt creato di recente.
lm_response = pipe(prompt_template)print(lm_response[0]["generated_text"])Vediamo la risposta del modello:
Contesto rilevante: #La leggendaria Toshiba ha ufficialmente smesso di produrre laptop #3 offerte di laptop per il gaming che non puoi permetterti di perdere oggi #Lenovo e HP controllano la metà del mercato globale dei laptop #Asus ROG Zephyrus G14 laptop per il gaming annunciato in India #Acer Swift 3 con processore Intel Ice Lake di decima generazione, schermo 2K e altro ancora lanciato in India per INR 64999 (US$865) #Il prossimo MacBook di Apple potrebbe essere il più economico nella storia dell’azienda #Svelate le caratteristiche del computer desktop di Huawei #Redmi lancerà il suo primo laptop per il gaming il 14 agosto: ecco tutti i dettagli #Toshiba chiude il capitolo dei laptop dopo 35 anni #Questo è il PC Windows più economico in assoluto e ha persino uno slot SSD di riserva
La domanda dell’utente: Posso comprare un laptop Toshiba?La risposta: No, Toshiba ha deciso di smettere di produrre laptop.
Perfetto! Il modello ha preso in considerazione il contesto che abbiamo fornito e ha costruito correttamente la risposta dell’utente, utilizzando non solo le sue conoscenze preallenate ma anche le informazioni che abbiamo passato nel prompt.
Conclusioni, prossimi passi.
Suppongo che tu abbia capito che tutto è stato molto più semplice di quanto sembrasse all’inizio.
Abbiamo utilizzato un database vettoriale per archiviare le nostre informazioni, che abbiamo utilizzato per costruire il prompt per un grande modello di linguaggio.
Il modello ha restituito la risposta corretta, tenendo conto del contesto che abbiamo fornito. Puoi immaginare che questo modo di lavorare apre un mondo di possibilità e si integra perfettamente con l’ottimizzazione dei grandi modelli di linguaggio.
Se vuoi sperimentare con il notebook, ricorda che è disponibile su Kaggle e GitHub.
Ecco alcune idee:
1. Utilizza tutti i dataset per cui il notebook è preparato e, se possibile, prova ad incorporare un nuovo dataset.
2. Esplora modelli diversi su Hugging Face e confronta i risultati.
3. Modifica il processo di creazione del prompt.
Sentiti libero di sperimentare, iterare ed esplorare diverse possibilità. Questo ti aiuterà a comprendere in modo più approfondito i database vettoriali, i grandi modelli di linguaggio e la loro applicazione nelle operazioni di elaborazione del linguaggio naturale.
Scrivo regolarmente su Deep Learning e machine learning. Considera seguirmi su VoAGI per ricevere aggiornamenti su nuovi articoli. E, naturalmente, sei invitato a connetterti con me su LinkedIn.






