Sfruttare i modelli generativi per potenziare l’apprendimento semi-supervisionato
Usare modelli generativi per migliorare l'apprendimento semi-supervisionato
Introduzione
Nel mondo dinamico dell’apprendimento automatico, una sfida costante è sfruttare appieno il potenziale limitato dei dati etichettati. Entra nel campo dell’apprendimento semi-supervisionato, un approccio ingegnoso che armonizza un piccolo gruppo di dati etichettati con un tesoro di dati non etichettati. In questo articolo, esploreremo una strategia rivoluzionaria: sfruttare modelli generativi, in particolare Variational Autoencoders (VAEs) e Generative Adversarial Networks (GANs). Alla fine di questo viaggio affascinante, capirai come questi modelli generativi possano migliorare profondamente le prestazioni degli algoritmi di apprendimento semi-supervisionato, come un colpo di scena magistrale in una narrazione avvincente.
Obiettivi di apprendimento
- Inizieremo approfondendo l’apprendimento semi-supervisionato, capendo perché è importante e vedendo come viene utilizzato in scenari di apprendimento automatico reali.
- Successivamente, ti presenteremo il mondo affascinante dei modelli generativi, concentrando l’attenzione su VAE e GAN. Scopriremo come potenziano l’apprendimento semi-supervisionato.
- Preparati a metterti all’opera mentre ti guidiamo attraverso il lato pratico. Imparerai come integrare questi modelli generativi nei progetti di apprendimento automatico del mondo reale, dalla preparazione dei dati all’addestramento del modello.
- Evidenzieremo i vantaggi, come il miglioramento della generalizzazione del modello e il risparmio dei costi. Inoltre, mostreremo come questo approccio si applica in diversi campi.
- Ogni viaggio ha le sue sfide e le affronteremo. Vedremo anche le importanti considerazioni etiche, assicurandoci che tu sia ben preparato per utilizzare in modo responsabile i modelli generativi nell’apprendimento semi-supervisionato.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
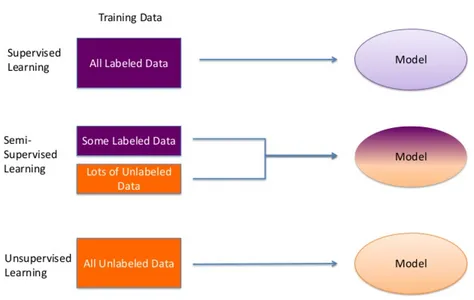
Introduzione all’apprendimento semi-supervisionato
Nel vasto panorama dell’apprendimento automatico, acquisire dati etichettati può essere intimidatorio. Spesso comporta sforzi dispendiosi in termini di tempo e denaro per annotare i dati, il che può limitare la scalabilità dell’apprendimento supervisionato. Entra in gioco l’apprendimento semi-supervisionato, un approccio intelligente che colma il divario tra i dati etichettati e quelli non etichettati. Riconosce che, sebbene i dati etichettati siano molto importanti, vasti insiemi di dati non etichettati spesso giacciono inutilizzati, pronti per essere sfruttati.
Immagina di dover insegnare a un computer a riconoscere vari animali nelle immagini, ma etichettare ognuno richiede uno sforzo eroico. Ecco dove entra in gioco l’apprendimento semi-supervisionato. Suggerisce di mescolare un piccolo gruppo di immagini etichettate con un ampio insieme di immagini non etichettate per addestrare i modelli di apprendimento automatico. Questo approccio consente al modello di sfruttare il potenziale inespresso dei dati non etichettati, migliorando le sue prestazioni e adattabilità. È come avere una manciata di stelle guida per navigare attraverso una galassia di informazioni.
- Incontra TinyLlama un piccolo modello di intelligenza artificiale che mira a preaddestrare un modello di lama da 1,1 miliardi su 3 trilioni di token.
- Alibaba presenta due modelli di linguaggio per la visione a grande scala (LVLM) open-source Qwen-VL e Qwen-VL-Chat
- Ripensare l’integrità accademica nell’era dell’IA un’analisi comparativa di ChatGPT e studenti universitari in 32 corsi
Nel nostro viaggio attraverso l’apprendimento semi-supervisionato, esploreremo la sua importanza, i principi fondamentali e le strategie innovative, con particolare attenzione a come i modelli generativi come VAE e GAN possano amplificare le sue capacità. Sblocciamo il potere dell’apprendimento semi-supervisionato, mano nella mano con i modelli generativi.
Modelli generativi: potenziare l’apprendimento semi-supervisionato
Nel mondo affascinante dell’apprendimento automatico, i modelli generativi emergono come veri e propri cambiavalute, dando nuova linfa vitale all’apprendimento semi-supervisionato. Questi modelli possiedono un talento unico: non solo possono comprendere le complessità dei dati, ma possono anche generare nuovi dati che riflettono ciò che hanno appreso. Tra i migliori performer in questo campo ci sono Variational Autoencoders (VAEs) e Generative Adversarial Networks (GANs). Intraprendiamo un viaggio per scoprire come questi modelli generativi diventano catalizzatori, spingendo i limiti dell’apprendimento semi-supervisionato.
VAE eccelle nel catturare l’essenza delle distribuzioni dei dati. Lo fa mappando i dati di input in uno spazio nascosto e poi ricostruendoli meticolosamente. Questa capacità trova un profondo scopo nell’apprendimento semi-supervisionato, dove i VAE incoraggiano i modelli a distillare rappresentazioni significative e concise dei dati. Queste rappresentazioni, coltivate senza la necessità di un’abbondanza di dati etichettati, sono la chiave per una migliore generalizzazione anche quando si affrontano esempi etichettati limitati. Sul palco opposto, i GAN si impegnano in un’intrigante danza avversaria. Qui, un generatore si sforza di creare dati virtualmente indistinguibili dai dati reali, mentre un discriminatore assume il ruolo di un critico vigile. Questo duetto dinamico porta all’aumento dei dati e apre la strada alla generazione di valori completamente nuovi. È attraverso queste performance affascinanti che VAE e GAN si mettono in primo piano, aprendo una nuova era dell’apprendimento semi-supervisionato.
Passaggi di Implementazione Pratici
Ora che abbiamo esplorato gli aspetti teorici, è il momento di metterci al lavoro e approfondire l’implementazione pratica dell’apprendimento semi-supervisionato con modelli generativi. Qui avviene la magia, dove convertiamo le idee in soluzioni reali. Ecco i passaggi necessari per dare vita a questa sinergia:

Passo 1: Preparazione dei Dati – Preparare il Terreno
Come in ogni produzione ben eseguita, abbiamo bisogno di una buona e solida base. Inizia raccogliendo i tuoi dati. Dovresti avere un piccolo set di dati etichettati e una sostanziale riserva di dati non etichettati. Assicurati che i tuoi dati siano puliti, ben organizzati e pronti per il palcoscenico.
# Esempio di codice per il caricamento e la preelaborazione dei dati
import pandas as pd
from sklearn.model_selection import train_test_split
# Carica i dati etichettati
labeled_data = pd.read_csv('labeled_data.csv')
# Carica i dati non etichettati
unlabeled_data = pd.read_csv('unlabeled_data.csv')
# Preelabora i dati (ad esempio, normalizza, gestisci valori mancanti)
labeled_data = preprocess_data(labeled_data)
unlabeled_data = preprocess_data(unlabeled_data)
# Dividi i dati etichettati in set di addestramento e di validazione
train_data, validation_data = train_test_split(labeled_data, test_size=0.2, random_state=42)
#importa csvPasso 2: Incorporazione di Modelli Generativi – Gli Effetti Speciali
I modelli generativi, le nostre star dello spettacolo, salgono sul palco. Integra Variational Autoencoders (VAE) o Generative Adversarial Networks (GAN) nel tuo flusso di apprendimento semi-supervisionato. Puoi scegliere di addestrare un modello generativo sui tuoi dati non etichettati o usarlo per l’aumento dei dati. Questi modelli aggiungono gli effetti speciali che fanno brillare il tuo apprendimento semi-supervisionato.
# Esempio di codice per l'integrazione di VAE per l'aumento dei dati
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Lambda
from tensorflow.keras import Model
# Definisci l'architettura del VAE (encoder e decoder)
# ... (Definisci i livelli dell'encoder)
# ... (Definisci i livelli del decoder)
# Crea il modello VAE
vae = Model(inputs=input_layer, outputs=decoded)
# Compila il modello VAE
vae.compile(optimizer='adam', loss='mse')
# Preallenamento del VAE sui dati non etichettati
vae.fit(unlabeled_data, unlabeled_data, epochs=10, batch_size=64)
#importa csvPasso 3: Addestramento Semi-Supervisionato – Prove dell’Ensemble
Ora è il momento di addestrare il tuo modello di apprendimento semi-supervisionato. Combina i dati etichettati con i dati aumentati generati dai modelli generativi. Questo cast di dati permetterà al tuo modello di estrarre caratteristiche importanti e generalizzare in modo efficace, proprio come un attore esperto che interpreta il proprio ruolo alla perfezione.
# Esempio di codice per l'apprendimento semi-supervisionato utilizzando TensorFlow/Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Crea un modello semi-supervisionato (ad esempio, una rete neurale)
model = Sequential()
# Aggiungi livelli (ad esempio, livello di input, livelli nascosti, livello di output)
model.add(Dense(128, activation='relu', input_dim=input_dim))
model.add(Dense(64, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compila il modello
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Addestra il modello con dati etichettati e dati aumentati
model.fit(
x=train_data[['feature1', 'feature2']], # Usa le caratteristiche rilevanti
y=train_data['label'], # Etichette dei dati etichettati
epochs=50, # Regola se necessario
batch_size=32,
validation_data=(validation_data[['feature1', 'feature2']], validation_data['label'])
)Passo 4: Valutazione e Ottimizzazione – La Prova Generale
Una volta che il modello è addestrato, è il momento della prova generale. Valuta le sue prestazioni utilizzando un set di dati di validazione separato. Ottimizza il modello in base ai risultati. Itera e perfeziona finché non raggiungi risultati ottimali, proprio come un regista che perfeziona una performance fino a renderla impeccabile.
# Esempio di codice per la valutazione del modello e il miglioramento
from sklearn.metrics import accuracy_score
# Effettua la previsione sul set di validazione
y_pred = model.predict(validation_data[['feature1', 'feature2']])
# Calcola l'accuratezza
accuracy = accuracy_score(validation_data['label'], y_pred.argmax(axis=1))
# Affina gli iperparametri o l'architettura del modello in base ai risultati di validazione
# Itera fino a raggiungere le prestazioni ottimaliIn questi passaggi pratici, convertiamo i concetti in azioni, completi di frammenti di codice per guidarti. È qui che lo script prende vita, e il tuo modello di apprendimento semi-supervisionato, alimentato da modelli generativi, prende il suo posto sotto i riflettori. Quindi, andiamo avanti e vediamo questa implementazione in azione.
Benefici e Applicazioni Realistiche
Quando combiniamo modelli generativi con l’apprendimento semi-supervisionato, i risultati sono rivoluzionari. Ecco perché è importante:
1. Generalizzazione Potenziata: Sfruttando dati non etichettati, i modelli addestrati in questo modo si comportano eccezionalmente bene con un numero limitato di esempi etichettati, esattamente come un attore talentuoso che brilla sul palcoscenico anche con un minimo di prove.
2. Aumento dei Dati: I modelli generativi, come i VAE e i GAN, forniscono una ricca fonte di dati aumentati. Questo migliora la robustezza del modello e previene l’overfitting, come un reparto scenografico unico che crea infinite variazioni di scene.
3. Riduzione dei Costi di Etichettatura: Etichettare i dati può essere costoso. Integrando modelli generativi, si riduce la necessità di un’estesa annotazione dei dati, ottimizzando il budget di produzione.
4. Adattamento di Dominio: Questo approccio eccelle nell’adattarsi a nuovi domini non visti con pochi dati etichettati, simile a un attore che transita senza problemi tra ruoli diversi.
5. Applicazioni Realistiche: Le possibilità sono molte. Nell’elaborazione del linguaggio naturale, migliora l’analisi del sentiment, la traduzione linguistica e la generazione di testo. Nella visione artificiale, eleva la classificazione delle immagini, il rilevamento degli oggetti e il riconoscimento facciale. È un prezioso strumento nel settore sanitario per la diagnosi di malattie, nel settore finanziario per il rilevamento delle frodi e nella guida autonoma per una miglior percezione.
Questo non è solo una teoria, ma un cambiamento pratico che rivoluziona diverse industrie, promettendo risultati e prestazioni affascinanti, proprio come un film ben realizzato che lascia un’impressione duratura.
Sfide e Considerazioni Etiche
Nel nostro percorso attraverso il territorio affascinante dell’apprendimento semi-supervisionato con modelli generativi, è necessario fare luce sulle sfide e le considerazioni etiche che accompagnano questo approccio innovativo.
- Qualità e Distribuzione dei Dati: Una delle principali sfide risiede nell’assicurare la qualità e la rappresentatività dei dati utilizzati per addestrare i modelli generativi e successivamente per l’apprendimento semi-supervisionato. Dati distorti o rumorosi possono portare a risultati distorti, proprio come una sceneggiatura difettosa che influisce sull’intera produzione.
- Addestramento di Modelli Complessi: L’integrazione di modelli generativi può introdurre complessità nel processo di addestramento. Richiede competenze non solo nell’apprendimento automatico tradizionale, ma anche nelle sfumature della modellazione generativa.
- Privacy e Sicurezza dei Dati: Mentre lavoriamo con grandi quantità di dati, garantire la privacy e la sicurezza dei dati diventa fondamentale. La gestione di informazioni sensibili o personali richiede protocolli rigorosi, simili alla salvaguardia di sceneggiature confidenziali nell’industria dell’intrattenimento.
- Prevenzione di Bias e Imparzialità: L’uso di modelli generativi deve essere effettuato con attenzione per evitare che i bias vengano perpetuati nei dati generati o influenzino le decisioni del modello.
- Conformità Regolamentare: Diverse industrie, come la sanità e la finanza, hanno regolamentazioni rigorose sulla gestione dei dati. È obbligatorio rispettare queste regole, proprio come garantire che una produzione sia conforme agli standard del settore.
- IA Etica: C’è la considerazione etica generale dell’impatto dell’IA e dell’apprendimento automatico sulla società. Garantire che i benefici di queste tecnologie siano accessibili ed equi per tutti è simile a promuovere la diversità e l’inclusione nel mondo dell’intrattenimento.
Mentre affrontiamo queste sfide e considerazioni etiche, è necessario avvicinarsi all’integrazione dei modelli generativi nell’apprendimento semi-supervisionato con diligenza e responsabilità. Proprio come creare un’opera d’arte stimolante e socialmente consapevole, questo approccio dovrebbe mirare ad arricchire la società riducendo al minimo i danni.

Risultati Sperimentali e Case Study
Adesso, approfondiamo la questione: risultati sperimentali che dimostrano l’impatto tangibile della combinazione di modelli generativi con l’apprendimento semi-supervisionato.
- Miglioramento della Classificazione delle Immagini: Nel campo della computer vision, i ricercatori hanno condotto esperimenti utilizzando modelli generativi per aumentare i dataset limitati di dati etichettati per la classificazione delle immagini. I risultati sono stati notevoli; i modelli addestrati con questo approccio hanno dimostrato una precisione significativamente maggiore rispetto ai metodi tradizionali di apprendimento supervisionato.
- Traduzione del Linguaggio con Dati Limitati: Nel campo dell’elaborazione del linguaggio naturale, i case study hanno dimostrato l’efficacia dell’apprendimento semi-supervisionato con modelli generativi per la traduzione del linguaggio. Con solo una quantità minima di dati di traduzione etichettati e una grande quantità di dati monolingui, i modelli sono stati in grado di ottenere un’accuratezza di traduzione impressionante.
- Diagnosi Mediche: Rivolgendo la nostra attenzione al settore sanitario, gli esperimenti hanno dimostrato il potenziale di questo approccio nella diagnostica medica. Con una carenza di immagini mediche etichettate, l’apprendimento semi-supervisionato, potenziato da modelli generativi, ha permesso una precisa rilevazione delle malattie.
- Rilevamento delle Frodi nel Settore Finanziario: Nell’industria finanziaria, i case study hanno dimostrato la potenza dei modelli generativi nell’apprendimento semi-supervisionato per il rilevamento delle frodi. Integrando dati etichettati con esempi, i modelli hanno raggiunto un’elevata precisione nell’identificazione delle transazioni fraudolente.
L’apprendimento semi-supervisionato illustra come questa sinergia possa portare a risultati notevoli in diversi ambiti, simile agli sforzi collaborativi di professionisti provenienti da campi diversi che si uniscono per creare qualcosa di grandioso.
Conclusioni
In questa esplorazione tra modelli generativi e apprendimento semi-supervisionato, abbiamo scoperto un approccio innovativo che promette di rivoluzionare l’apprendimento automatico. Questa potente sinergia affronta la sfida perenne della scarsità di dati, consentendo ai modelli di emergere in settori in cui i dati etichettati sono scarsi. Concludendo, è evidente che questa integrazione rappresenta un cambiamento di paradigma, aprendo nuove possibilità e ridefinendo il panorama dell’intelligenza artificiale.
Punti Chiave
1. Efficienza attraverso la Fusione: L’apprendimento semi-supervisionato con modelli generativi colma il divario tra dati etichettati e non etichettati, offrendo un percorso più efficiente ed economico per l’apprendimento automatico.
2. Stelle dei Modelli Generativi: I Variational Autoencoder (VAE) e i Generative Adversarial Networks (GAN) svolgono un ruolo cruciale nell’aumentare il processo di apprendimento, simili a co-protagonisti talentuosi che valorizzano una performance.
3. Implementazione Pratica: L’implementazione richiede una preparazione attenta dei dati, l’integrazione senza soluzione di continuità dei modelli generativi, un addestramento rigoroso, un rifinimento iterativo e una considerazione etica vigile, simile alla pianificazione meticolosa di una grande produzione.
4. Impatto Versatile nel Mondo Reale: I benefici si estendono a diversi ambiti, dalla sanità alla finanza. Dimostrando l’adattabilità e l’applicabilità nel mondo reale di questo approccio, simile a uno script diverso e unico che risuona con diverse audience.
5. Responsabilità Etica: Come qualsiasi strumento, le considerazioni etiche sono fondamentali. Garantire equità, privacy e un uso responsabile dell’IA è di primaria importanza, simile al mantenimento degli standard etici nell’industria artistica e dell’intrattenimento.
Domande Frequenti
I contenuti multimediali mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.