Introduzione ai Database in Data Science
Introduzione ai Database in Data Science

La data science consiste nell’estrazione di valore e informazioni da grandi volumi di dati al fine di guidare le decisioni aziendali. Comprende anche la creazione di modelli predittivi utilizzando dati storici. I database facilitano lo storage, la gestione, il recupero e l’analisi efficaci di tali grandi volumi di dati.
Quindi, come data scientist, è importante comprendere i fondamenti dei database. Perché consentono lo storage e la gestione di dataset grandi e complessi, consentendo una ricerca efficiente dei dati, la creazione di modelli e l’ottenimento di informazioni. Esploreremo questo argomento in maggior dettaglio in questo articolo.
Inizieremo discutendo le competenze essenziali dei database per la data science, inclusa SQL per il recupero dei dati, la progettazione dei database, l’ottimizzazione e molto altro. Successivamente, esamineremo i principali tipi di database, i loro vantaggi e casi d’uso.
- Questa ricerca sull’IA rivoluziona il design del modulatore di Mach-Zehnder al silicio attraverso l’apprendimento profondo e gli algoritmi evolutivi
- Time 100 AI I più influenti?
- Ricercatori dell’UCLA introducono un sistema QPI multispettrale progettato basandosi su una rete neurale ottica diffrattiva a banda larga
Competenze Essenziali dei Database per la Data Science
Le competenze dei database sono essenziali per i data scientist, in quanto forniscono le basi per una gestione, analisi e interpretazione efficaci dei dati.
Ecco una panoramica delle competenze chiave dei database che i data scientist dovrebbero comprendere:
Anche se abbiamo cercato di categorizzare i concetti e le competenze dei database in diverse categorie, vanno insieme. E spesso dovrai conoscerli o impararli lungo il percorso quando lavori su progetti.
Passiamo ora a esaminare ognuno dei punti elencati sopra.
1. Tipi e Concetti dei Database
Come data scientist, è importante avere una buona comprensione dei diversi tipi di database, come i database relazionali e NoSQL, e i rispettivi casi d’uso.
2. SQL (Structured Query Language) per il Recupero dei Dati
La padronanza di SQL attraverso la pratica è fondamentale per qualsiasi ruolo nel campo dei dati. Dovresti essere in grado di scrivere e ottimizzare le query SQL per recuperare, filtrare, aggregare e unire dati dai database.
È anche utile comprendere i piani di esecuzione delle query e essere in grado di identificare e risolvere i colli di bottiglia delle prestazioni.
3. Data Modeling e Progettazione dei Database
Oltre alla semplice interrogazione delle tabelle del database, è importante comprendere le basi del data modeling e della progettazione dei database, inclusi i diagrammi entità-relazione (ER), la progettazione dello schema e i vincoli di validazione dei dati.
Dovresti anche essere in grado di progettare schemi di database che supportino l’interrogazione efficiente e lo storage dei dati per scopi analitici.
4. Pulizia e Trasformazione dei Dati
Come data scientist, dovrai preelaborare e trasformare i dati grezzi in un formato adatto all’analisi. I database possono supportare attività di pulizia, trasformazione e integrazione dei dati.
Quindi dovresti sapere come estrarre dati da diverse fonti, trasformarli in un formato adatto e caricarli nei database per l’analisi. È importante essere familiari con gli strumenti ETL, i linguaggi di scripting (Python, R) e le tecniche di trasformazione dei dati.
5. Ottimizzazione dei Database
Dovresti conoscere le tecniche per ottimizzare le prestazioni dei database, come la creazione di indici, la denormalizzazione e l’utilizzo di meccanismi di caching.
Per ottimizzare le prestazioni dei database, vengono utilizzati gli indici per velocizzare il recupero dei dati. Un’indicizzazione corretta migliora i tempi di risposta delle query consentendo al motore di database di individuare rapidamente i dati richiesti.
6. Integrità e Controllo della Qualità dei Dati
L’integrità dei dati viene mantenuta attraverso vincoli che definiscono regole per l’inserimento dei dati. I vincoli come unicità, non null e di controllo garantiscono l’accuratezza e l’affidabilità dei dati.
Le transazioni vengono utilizzate per garantire la coerenza dei dati, garantendo che più operazioni vengano trattate come un’unica unità atomica.
7. Integrazione con Strumenti e Linguaggi
I database possono integrarsi con strumenti e software di analisi e visualizzazione popolari, consentendo ai data scientist di analizzare e presentare in modo efficace i loro risultati. Pertanto, è importante sapere come connettersi e interagire con i database utilizzando linguaggi di programmazione come Python, e eseguire l’analisi dei dati.
È necessaria anche familiarità con strumenti come pandas di Python, R e librerie di visualizzazione.
In sintesi: la comprensione dei vari tipi di database, SQL, la modellazione dei dati, i processi ETL, l’ottimizzazione delle prestazioni, l’integrità dei dati e l’integrazione con i linguaggi di programmazione sono componenti chiave delle competenze di un data scientist.
Nel resto di questa guida introduttiva, ci concentreremo sui concetti fondamentali dei database e sui tipi.
Fondamenti dei database relazionali
I database relazionali sono un tipo di sistema di gestione di database (DBMS) che organizza e archivia i dati in modo strutturato utilizzando tabelle con righe e colonne. I RDBMS popolari includono PostgreSQL, MySQL, Microsoft SQL Server e Oracle.
Esaminiamo alcuni concetti chiave dei database relazionali utilizzando esempi.
Tabelle di database relazionali
In un database relazionale, ogni tabella rappresenta un’entità specifica, e le relazioni tra le tabelle vengono stabilite utilizzando chiavi.
Per capire come i dati sono organizzati nelle tabelle dei database relazionali, è utile partire dalle entità e dagli attributi.
Spesso si desidera archiviare dati sugli oggetti: studenti, clienti, ordini, prodotti e simili. Questi oggetti sono entità e hanno attributi.
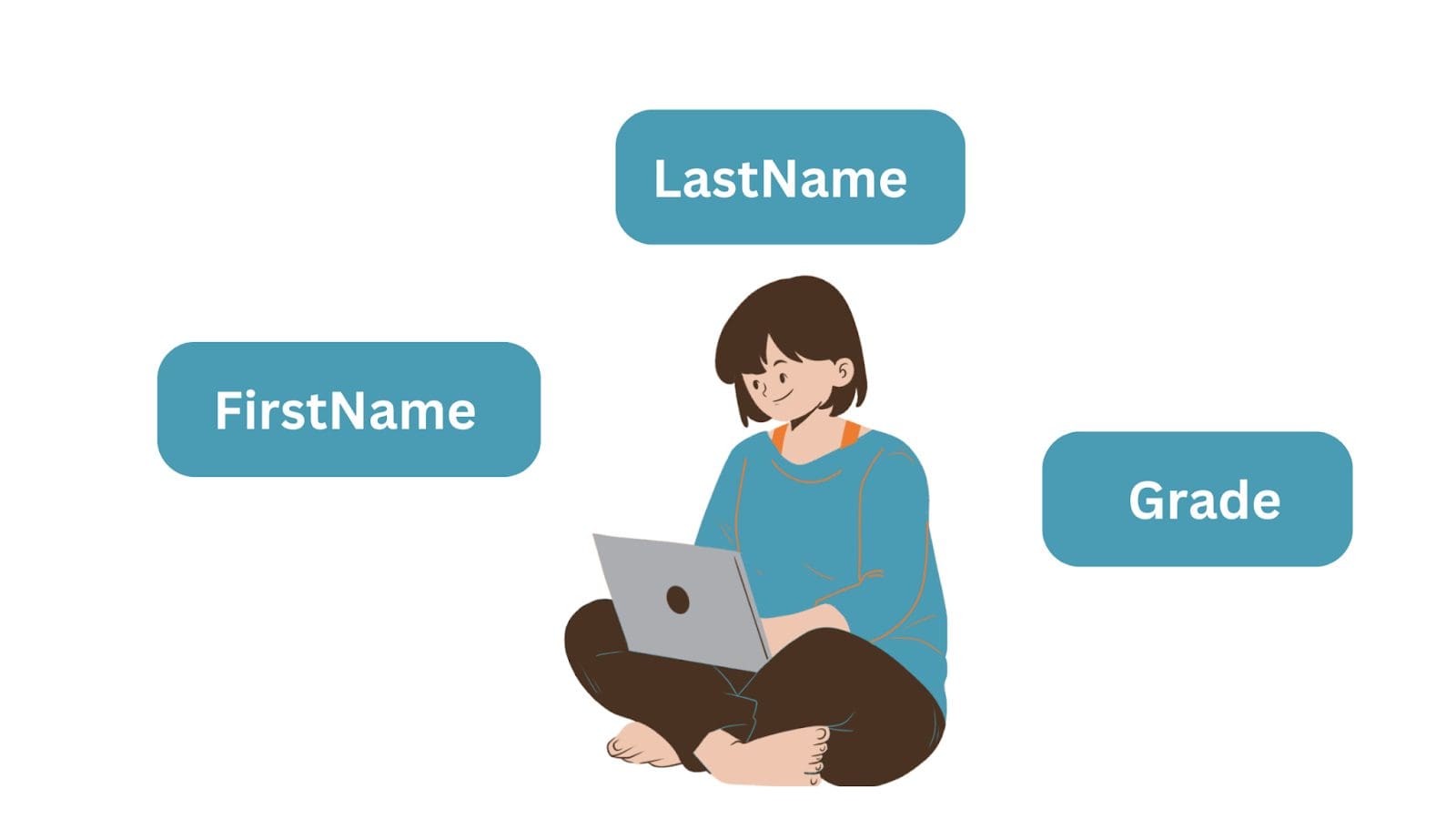
Prendiamo ad esempio una semplice entità: un oggetto “Studente” con tre attributi: Nome, Cognome e Voto. Quando si archiviano i dati, l’entità diventa la tabella del database e gli attributi i nomi delle colonne o i campi. E ogni riga è un’istanza di un’entità.
Le tabelle in un database relazionale sono composte da righe e colonne:
- Le righe sono anche conosciute come record o tuple, e
- Le colonne sono indicate come attributi o campi.
Ecco un esempio di una semplice tabella “Studenti”:
| IDStudente | Nome | Cognome | Voto |
| 1 | Jane | Smith | A+ |
| 2 | Emily | Brown | A |
| 3 | Jake | Williams | B+ |
In questo esempio, ogni riga rappresenta uno studente e ogni colonna rappresenta una informazione sullo studente.
Comprensione delle chiavi
Le chiavi vengono utilizzate per identificare in modo univoco le righe all’interno di una tabella. I due tipi importanti di chiavi includono:
- Chiave primaria: una chiave primaria identifica in modo univoco ogni riga in una tabella. Garantisce l’integrità dei dati e fornisce un modo per fare riferimento a record specifici. Nella tabella “Studenti”, “IDStudente” potrebbe essere la chiave primaria.
- Chiave esterna: una chiave esterna stabilisce una relazione tra le tabelle. Fa riferimento alla chiave primaria di un’altra tabella ed è utilizzata per collegare dati correlati. Ad esempio, se abbiamo un’altra tabella chiamata “Corsi”, la colonna “IDStudente” nella tabella “Corsi” potrebbe essere una chiave esterna che fa riferimento all’ “IDStudente” nella tabella “Studenti”.
Relazioni
I database relazionali ti consentono di stabilire relazioni tra tabelle. Ecco le relazioni più importanti e comuni:
- Relazione uno a uno: In una relazione uno a uno, ogni record in una tabella è correlato a uno – e solo uno – record in un’altra tabella nel database. Ad esempio, una tabella “DettagliStudente” con informazioni aggiuntive su ogni studente potrebbe avere una relazione uno a uno con la tabella “Studenti”.
- Relazione uno a molti: Un record nella prima tabella è correlato a più record nella seconda tabella. Ad esempio, una tabella “Corsi” potrebbe avere una relazione uno a molti con la tabella “Studenti”, in cui ogni corso è associato a più studenti.
- Relazione molti a molti: Più record in entrambe le tabelle sono correlati tra loro. Per rappresentare ciò, viene utilizzata una tabella intermedia, spesso chiamata tabella di collegamento o di giunzione. Ad esempio, una tabella “StudentiCorsi” potrebbe stabilire una relazione molti a molti tra studenti e corsi.
Normalizzazione
La normalizzazione (spesso discussa nell’ambito delle tecniche di ottimizzazione del database) è il processo di organizzazione dei dati in modo da ridurre al minimo la ridondanza dei dati e migliorare l’integrità dei dati. Coinvolge la suddivisione di grandi tabelle in tabelle più piccole correlate. Ogni tabella dovrebbe rappresentare un’entità o un concetto singolo per evitare la duplicazione dei dati.
Ad esempio, se consideriamo la tabella “Studenti” e una ipotetica tabella “Indirizzi”, la normalizzazione potrebbe comportare la creazione di una tabella separata “Indirizzi” con la propria chiave primaria e il collegamento alla tabella “Studenti” mediante una chiave esterna.
Vantaggi e Limitazioni dei Database Relazionali
Ecco alcuni vantaggi dei database relazionali:
- I database relazionali forniscono un modo strutturato e organizzato per memorizzare i dati, rendendo facile definire relazioni tra diversi tipi di dati.
- Supportano le proprietà ACID (Atomicità, Coerenza, Isolamento, Durabilità) per le transazioni, garantendo che i dati rimangano consistenti.
D’altra parte, presentano le seguenti limitazioni:
- I database relazionali hanno difficoltà di scalabilità orizzontale, rendendo difficile gestire grandi quantità di dati e carichi di traffico elevati.
- Richiedono anche uno schema rigido, rendendo difficile adattarsi a modifiche nella struttura dei dati senza modificare lo schema.
- I database relazionali sono progettati per dati strutturati con relazioni ben definite. Potrebbero non essere adatti per la memorizzazione di dati non strutturati o semi-strutturati come documenti, immagini e contenuti multimediali.
Esplorazione dei Database NoSQL
I database NoSQL non memorizzano i dati in tabelle nel tradizionale formato riga-colonna (quindi sono non relazionali). Il termine “NoSQL” sta per “non solo SQL”, indicando che questi database differiscono dal modello di database relazionale tradizionale.
I principali vantaggi dei database NoSQL sono la scalabilità e la flessibilità. Questi database sono progettati per gestire grandi volumi di dati non strutturati o semi-strutturati e offrono soluzioni più flessibili e scalabili rispetto ai database relazionali tradizionali.
I database NoSQL comprendono una varietà di tipi di database che differiscono per i loro modelli di dati, meccanismi di archiviazione e linguaggi di query. Alcune categorie comuni di database NoSQL includono:
- Archivi chiave-valore
- Database documentali
- Database a famiglia di colonne
- Database a grafo.
Adesso, esaminiamo ciascuna delle categorie di database NoSQL, esplorando le loro caratteristiche, casi d’uso, esempi, vantaggi e limitazioni.
Archivi chiave-valore
Gli archivi chiave-valore memorizzano i dati come semplici coppie di chiavi e valori. Sono ottimizzati per operazioni di lettura e scrittura ad alta velocità. Sono adatti per applicazioni come la memorizzazione nella cache, la gestione delle sessioni e l’analisi in tempo reale.
Tuttavia, questi database hanno capacità di interrogazione limitate oltre il recupero basato sulla chiave. Quindi non sono adatti per relazioni complesse.
Amazon DynamoDB e Redis sono archivi chiave-valore popolari.
Database documentali
I database documentali memorizzano i dati in formati di documenti come JSON e BSON. Ogni documento può avere strutture variabili, consentendo dati nidificati e complessi. Il loro schema flessibile consente una gestione facile dei dati semi-strutturati, supportando modelli di dati in evoluzione e relazioni gerarchiche.
Questi sono particolarmente adatti per la gestione dei contenuti, le piattaforme di e-commerce, i cataloghi, i profili utente e le applicazioni con strutture dati in continua evoluzione. I database documentali potrebbero non essere efficienti per join complessi o query complesse che coinvolgono più documenti.
MongoDB e Couchbase sono database documentali popolari.
Archivi di famiglie di colonne (archivi di colonne larghe)
Gli archivi di famiglie di colonne, anche noti come database colonnari o database orientati alle colonne, sono un tipo di database NoSQL che organizza e memorizza i dati in modo orientato alle colonne anziché al tradizionale modo orientato alle righe dei database relazionali.
Gli archivi di famiglie di colonne sono adatti per carichi di lavoro analitici che coinvolgono l’esecuzione di query complesse su grandi set di dati. Aggregazioni, filtraggio e trasformazioni dei dati vengono spesso eseguiti in modo più efficiente nei database di famiglie di colonne. Sono utili per la gestione di grandi quantità di dati semi-strutturati o sparsi.
Apache Cassandra, ScyllaDB e HBase sono alcuni archivi di famiglie di colonne.
Database di grafi
I database di grafi modellano i dati e le relazioni nei nodi e negli archi, rispettivamente, per rappresentare relazioni complesse. Questi database supportano la gestione efficiente di relazioni complesse e potenti linguaggi di interrogazione dei grafi.
Come puoi immaginare, questi database sono adatti per le reti sociali, i motori di raccomandazione, i grafi di conoscenza e, in generale, i dati con relazioni intricate.
Esempi di database di grafi popolari sono Neo4j e Amazon Neptune.
Esistono molti tipi di database NoSQL. Quindi come decidiamo quale utilizzare? Beh, la risposta è: dipende.
Ogni categoria di database NoSQL offre funzionalità e vantaggi unici, che li rendono adatti a casi d’uso specifici. È importante scegliere il database NoSQL appropriato considerando i modelli di accesso, i requisiti di scalabilità e le considerazioni sulle prestazioni.
In sintesi: i database NoSQL offrono vantaggi in termini di flessibilità, scalabilità e prestazioni, che li rendono adatti a una vasta gamma di applicazioni, tra cui big data, analisi in tempo reale e applicazioni web dinamiche. Tuttavia, comportano dei compromessi in termini di coerenza dei dati.
Vantaggi e limitazioni dei database NoSQL
Ecco alcuni vantaggi dei database NoSQL:
- I database NoSQL sono progettati per la scalabilità orizzontale, consentendo loro di gestire enormi quantità di dati e traffico.
- Questi database consentono schemi flessibili e dinamici. Hanno modelli di dati flessibili per ospitare vari tipi e strutture di dati, rendendoli adatti per dati non strutturati o semi-strutturati.
- Molti database NoSQL sono progettati per funzionare in ambienti distribuiti e tolleranti ai guasti, garantendo un’alta disponibilità anche in presenza di guasti hardware o interruzioni di rete.
- Possono gestire dati non strutturati o semi-strutturati, rendendoli adatti per applicazioni che trattano diversi tipi di dati.
Alcune limitazioni includono:
- I database NoSQL danno priorità alla scalabilità e alle prestazioni rispetto alla conformità ACID rigorosa. Ciò può comportare una coerenza eventuale e potrebbe non essere adatto per applicazioni che richiedono una forte coerenza dei dati.
- Poiché i database NoSQL sono disponibili in varie varianti con diverse API e modelli di dati, la mancanza di standardizzazione può rendere difficile il passaggio tra database o l’integrazione senza problemi.
È importante notare che i database NoSQL non sono una soluzione universale. La scelta tra un database NoSQL e un database relazionale dipende dalle esigenze specifiche della tua applicazione, tra cui il volume dei dati, i modelli di query e i requisiti di scalabilità, tra gli altri.
Database relazionali vs. database NoSQL
Riassumiamo le differenze discusse finora:
| Caratteristica | Database relazionali | Database NoSQL |
| Modello di dati | Struttura tabellare (tabelle) | Modelli di dati diversi (documenti, coppie chiave-valore, grafi, colonne, ecc.) |
| Coerenza dei dati | Coerenza forte | Coerenza eventuale |
| Schema | Schema ben definito | Flessibile o senza schema |
| Relazioni dati | Supporta relazioni complesse | Varia a seconda del tipo (relazioni limitate o esplicite) |
| Linguaggio di interrogazione | Interrogazioni basate su SQL | Linguaggio di interrogazione specifico o API |
| Flessibilità | Non altrettanto flessibile per dati non strutturati | Adatto per diversi tipi di dati, inclusi |
| Casi d’uso | Dati ben strutturati, transazioni complesse | Applicazioni di larga scala, ad alto throughput, in tempo reale |
Una nota sui database di serie temporali
Come data scientist, lavorerai anche con dati di serie temporali. I database di serie temporali sono anche database non relazionali, ma hanno un caso d’uso più specifico.
Devono supportare la memorizzazione, la gestione e la query dei punti dati con timestamp, ovvero punti dati registrati nel tempo, come letture dei sensori e prezzi delle azioni. Offrono funzionalità specializzate per la memorizzazione, la query e l’analisi di modelli di dati basati sul tempo.
Alcuni esempi di database di serie temporali includono InfluxDB, QuestDB e TimescaleDB.
Conclusione
In questa guida, abbiamo esaminato i database relazionali e NoSQL. Vale anche la pena notare che è possibile esplorare alcuni database oltre ai popolari tipi relazionali e NoSQL. I database NewSQL come CockroachDB offrono i vantaggi tradizionali dei database SQL pur offrendo la scalabilità e le prestazioni dei database NoSQL.
È anche possibile utilizzare un database in memoria che memorizza e gestisce i dati principalmente nella memoria principale (RAM) di un computer, a differenza dei database tradizionali che archiviano i dati su disco. Questo approccio offre significativi vantaggi in termini di prestazioni grazie alle operazioni di lettura e scrittura molto più veloci che possono essere eseguite in memoria rispetto all’archiviazione su disco. Bala Priya C è una sviluppatrice e scrittrice tecnica proveniente dall’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse ed esperienza includono DevOps, data science e elaborazione del linguaggio naturale. Le piace leggere, scrivere, programmare e bere caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità di sviluppatori scrivendo tutorial, guide pratiche, articoli di opinione e altro ancora.






