Come utilizzare Hugging Face AutoTrain per ottimizzare i LLM
Come sfruttare Hugging Face AutoTrain per massimizzare l'efficienza dei LLM

Introduzione
Negli ultimi anni, il Large Language Model (LLM) ha cambiato il modo in cui le persone lavorano ed è stato utilizzato in molti settori, come l’educazione, il marketing, la ricerca, ecc. Date le potenzialità, il LLM può essere potenziato per risolvere meglio i nostri problemi aziendali. Ecco perché possiamo eseguire un fine-tuning del LLM.
- Rivelazione dell’incredibile IA di Google, Gemini, e del Cambiamento di Paradigma di Stubbs
- Questo articolo AI presenta Video Language Planning (VLP) un nuovo approccio di intelligenza artificiale che consiste in una procedura di ricerca ad albero con modelli di visione-linguaggio e dinamiche di testo-video
- Incontra LAMP un framework AI di few-shot per l’apprendimento dei modelli di movimento con modelli di diffusione testo-immagine
Vogliamo eseguire il fine-tuning del nostro LLM per diversi motivi, tra cui l’adozione di casi d’uso specifici del dominio, il miglioramento dell’accuratezza, la privacy e la sicurezza dei dati, il controllo del bias del modello e molti altri. Con tutti questi vantaggi, è essenziale imparare come eseguire il fine-tuning del nostro LLM per averne uno in produzione.
Un modo per eseguire il fine-tuning automatico del LLM è utilizzare Hugging Face’s AutoTrain. L’AutoTrain di HF è una piattaforma senza codice con API in Python per addestrare modelli all’avanguardia per varie attività come Visione Artificiale, Tabulari e attività di NLP. Possiamo utilizzare la capacità di AutoTrain anche se non comprendiamo molto del processo di fine-tuning del LLM.
Allora, come funziona? Esaminiamo ulteriormente.
Iniziare con AutoTrain
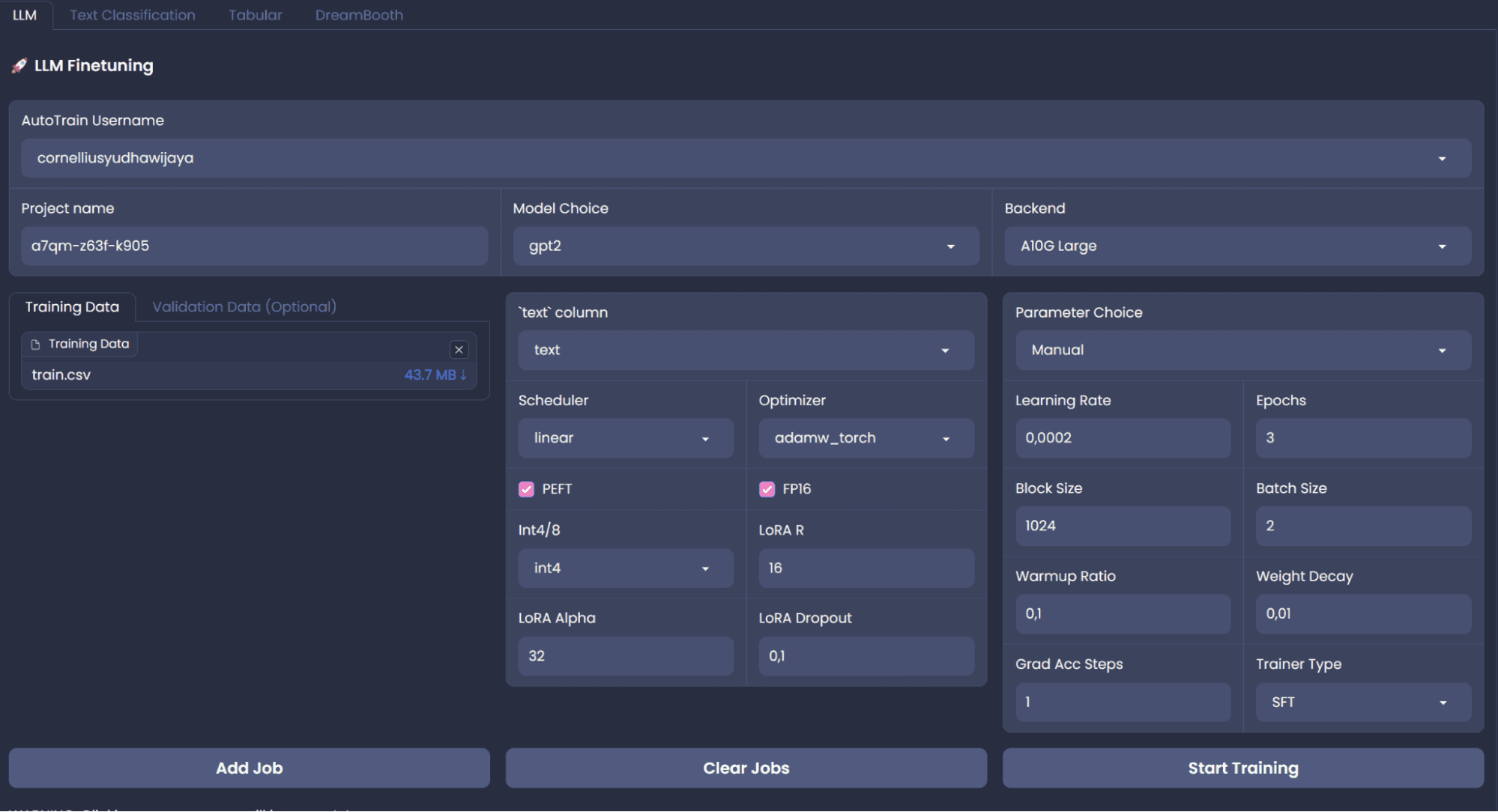
Anche se HF AutoTrain è una soluzione senza codice, possiamo svilupparla in cima all’AutoTrain utilizzando le API in Python. Esploreremo le strade di codice poiché la piattaforma senza codice non è stabile per l’addestramento. Tuttavia, se desideri utilizzare la piattaforma senza codice, possiamo creare lo spazio AutoTrain utilizzando la seguente pagina. La piattaforma complessiva verrà mostrata nell’immagine qui sotto.
Per eseguire il fine-tuning del LLM con le API in Python, è necessario installare il pacchetto Python, che puoi eseguire utilizzando il codice seguente.
pip install -U autotrain-advanced
Inoltre, useremo il dataset di esempio di Alpaca da HuggingFace, che richiede il pacchetto datasets per essere acquisito.
pip install datasets
Quindi, utilizza il codice seguente per acquisire i dati di cui abbiamo bisogno.
from datasets import load_dataset # Carica il datasetdataset = load_dataset("tatsu-lab/alpaca") train = dataset['train']
Inoltre, salveremo i dati nel formato CSV poiché ne avremo bisogno per il nostro fine-tuning.
train.to_csv('train.csv', index = False)
Con l’ambiente e il dataset pronti, proviamo a utilizzare HuggingFace AutoTrain per eseguire il fine-tuning del nostro LLM.
Procedura di fine-tuning e valutazione
Adatterò il processo di fine-tuning dall’esempio di AutoTrain, che puoi trovare qui. Per avviare il processo, mettiamo i dati che useremo per il fine-tuning nella cartella chiamata data.

Per questo tutorial, provo a campionare solo 100 righe di dati in modo che il nostro processo di addestramento possa essere molto più rapido. Dopo aver preparato i nostri dati, possiamo utilizzare il nostro Jupyter Notebook per eseguire il fine-tuning del nostro modello. Assicurati che i dati contengano una colonna “text” poiché AutoTrain leggerà solo da quella colonna.
Per prima cosa, eseguiamo la configurazione di AutoTrain utilizzando il seguente comando.
!autotrain setup
Successivamente, forniremo le informazioni richieste da AutoTrain per l’esecuzione. Per la seguente informazione, si tratta del nome del progetto e del modello pre-addestrato che desideri. Puoi scegliere solo il modello disponibile in HuggingFace.
project_name = 'my_autotrain_llm'
model_name = 'tiiuae/falcon-7b'
Successivamente, aggiungeremmo le informazioni relative a HF, se vuoi caricare il tuo modello nel repository o utilizzare un modello privato.
push_to_hub = False
hf_token = "IL TUO TOKEN DI HF"
repo_id = "nome_utente/nome_repo"
Infine, inizieremmo a inizializzare le informazioni sui parametri del modello nelle variabili di seguito. Puoi modificarle come preferisci per verificare se il risultato è buono o no.
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
trainer = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
Con tutte le informazioni pronte, configuriamo l’ambiente per accettare tutte le informazioni che abbiamo impostato in precedenza.
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
Per eseguire l’AutoTrain nel nostro notebook, utilizziamo il seguente comando.
!autotrain llm \--train \--model ${MODEL_NAME} \--project-name ${PROJECT_NAME} \--data-path data/ \--text-column text \--lr ${LEARNING_RATE} \--batch-size ${BATCH_SIZE} \--epochs ${NUM_EPOCHS} \--block-size ${BLOCK_SIZE} \--warmup-ratio ${WARMUP_RATIO} \--lora-r ${LORA_R} \--lora-alpha ${LORA_ALPHA} \--lora-dropout ${LORA_DROPOUT} \--weight-decay ${WEIGHT_DECAY} \--gradient-accumulation ${GRADIENT_ACCUMULATION} \$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" ) \$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" ) \$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
Se esegui l’AutoTrain con successo, dovresti trovare la seguente cartella nel tuo directory con tutti i modelli e i tokenizer prodotti da AutoTrain. 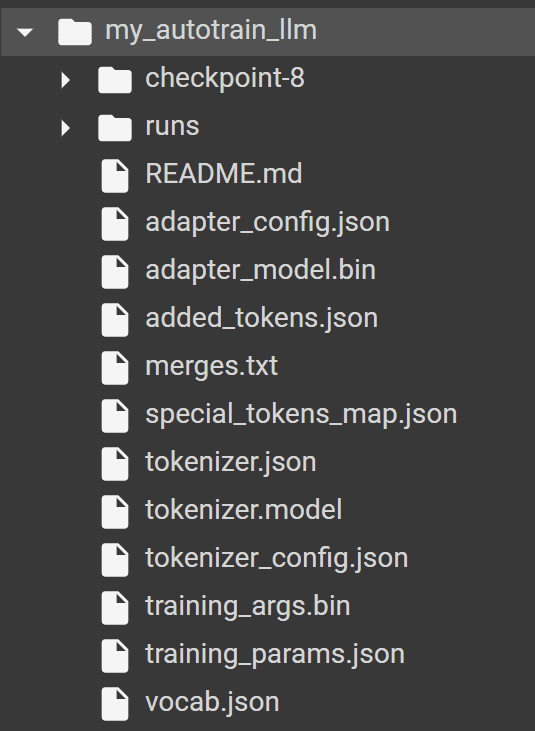
Per testare il modello, useremmo il pacchetto HuggingFace transformers con il seguente codice.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
Poi, possiamo provare a valutare il nostro modello in base all’input di addestramento che abbiamo dato. Ad esempio, utilizziamo “Benefici per la salute dell’esercizio regolare” come input.
input_text = "Benefici per la salute dell'esercizio regolare"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=False)
print(predicted_text)
Il risultato può certamente essere migliorato, ma almeno è più vicino ai dati di esempio che abbiamo fornito. Possiamo provare a giocare con il modello pre-addestrato e i parametri per migliorare l’adattamento fine.
Consigli per un Assetto Fine di Successo
Ci sono alcune best practice che potresti voler seguire per migliorare il processo di adattamento fine, tra cui:
- Preparare il nostro set di dati in modo che corrisponda alla qualità del compito rappresentativo,
- Studiare il modello pre-addestrato che abbiamo utilizzato,
- Utilizzare adeguate tecniche di regolarizzazione per evitare l’overfitting,
- Provare un tasso di apprendimento più basso che gradualmente diventa più alto,
- Utilizzare meno epoche di addestramento poiché i LLM apprendono di solito i nuovi dati molto velocemente,
- Non ignorare il costo computazionale, poiché aumenta con dati, parametri e modelli più grandi,
- Assicurarsi di seguire le considerazioni etiche riguardanti i dati utilizzati.
Conclusioni
L’adattamento fine del nostro Large Language Model è vantaggioso per il processo aziendale, specialmente se ci sono determinati requisiti che richiediamo. Con HuggingFace AutoTrain, possiamo accelerare il nostro processo di addestramento e utilizzare facilmente il modello pre-addestrato disponibile per l’adattamento fine del modello.
[Cornellius Yudha Wijaya](https://www.linkedin.com/in/cornellius-yudha-wijaya/) è un assistente manager del data science e scrittore di dati. Mentre lavora a tempo pieno presso Allianz Indonesia, ama condividere consigli su Python e dati tramite i social media e i media scritti.






