Creazione di video 3D da video RGB
Creazione video 3D da video RGB
Istruzioni per generare video di depthmap e point cloud coerenti da qualsiasi video RGB

Sono sempre stato insoddisfatto del fatto che archiviamo i nostri ricordi digitali in formato 2D: fotografie e video che, nonostante la loro chiarezza, mancano della profondità e dell’immersione delle esperienze che catturano. È una limitazione che sembra arbitraria in un’epoca in cui i modelli di apprendimento automatico possono essere sufficientemente potenti da comprendere la tridimensionalità delle foto e dei video.
I dati 3D dalle immagini o dai video non solo ci permettono di vivere i nostri ricordi in modo più vivido e interattivo, ma offrono anche nuove possibilità di editing e post-processing. Immagina di poter rimuovere senza sforzo oggetti da una scena, cambiare sfondi o persino spostare la prospettiva per vedere un momento da un nuovo punto di vista. Elaborare i dati di profondità offre anche agli algoritmi di apprendimento automatico un contesto più ricco per comprendere e manipolare i dati visivi.
Mentre cercavo metodi per generare una consistente profondità dei video, ho trovato un articolo di ricerca che suggeriva un approccio interessante. Questo approccio prevede di addestrare due reti neurali insieme utilizzando l’intero video di input: una rete neurale convoluzionale (CNN) per prevedere la profondità e un MLP per prevedere il movimento nella scena, o “flusso di scena”. Questa rete di previsione del flusso viene utilizzata in modo particolare, applicandola ripetutamente per diversi periodi di tempo. Ciò le consente di individuare sia i cambiamenti piccoli che quelli grandi nella scena. I cambiamenti piccoli aiutano a garantire che il movimento da un momento all’altro sia fluido in 3D, mentre i cambiamenti più grandi aiutano a garantire che l’intero video sia coerente quando viene visto da prospettive diverse. In questo modo, possiamo creare video 3D che siano accurati sia localmente che globalmente.
Il repository del codice dell’articolo è pubblicamente disponibile, tuttavia, il flusso di lavoro per l’elaborazione di video arbitrari non è spiegato completamente e, almeno per me, non era chiaro come elaborare qualsiasi video con il flusso di lavoro proposto. In questo articolo, cercherò di colmare questa lacuna e di fornire un tour passo-passo su come utilizzare il flusso di lavoro sui tuoi video.
- Crea un’alternativa a Langchain da zero utilizzando OceanBase
- Come imparare l’IA
- Le principali novità in Computer Vision della settimana dal 14/8 al 20/8
Puoi controllare la mia versione del codice sulla mia pagina GitHub, a cui farò riferimento.
Passo 1: Estrarre i fotogrammi dal video
La prima cosa che facciamo nel flusso di lavoro è estrarre i fotogrammi dal video scelto. Ho aggiunto uno script a tal scopo, che puoi trovare in scripts/preprocess/custom/extract_frames_from_video.py. Per eseguire il codice, utilizza semplicemente il seguente comando nel tuo terminale:
python extract_frames_from_video.py ^ -- video_path = 'INSERISCI IL PERCORSO DEL TUO VIDEO QUI' ^ -- output_dir = '../../../datafiles/custom/JPEGImages/640p/custom/' ^ -- resize_factor = 0.5Utilizzando l’argomento resize_factor, puoi ridurre o aumentare la dimensione dei tuoi fotogrammi.
Ho selezionato questo video per i miei test. Inizialmente aveva una risoluzione di 1280×720, ma per velocizzare l’elaborazione nei passaggi successivi, l’ho ridimensionato a 640×360 utilizzando un resize_factor di 0.5.
Passo 2: Segmenta un oggetto in primo piano nel video
Il passo successivo nel nostro processo richiede di segmentare o isolare uno degli oggetti principali in primo piano nel video, il che è cruciale per stimare la posizione e l’angolo della telecamera all’interno del video. Il motivo? Gli oggetti più vicini alla telecamera influenzano significativamente la stima della posa più di quelli lontani. Per illustrare, immagina un oggetto distante un metro che si muove di 10 centimetri: ciò si tradurrebbe in un cambiamento considerevole nell’immagine, forse decine di pixel. Ma se lo stesso oggetto fosse distante 10 metri e si muovesse della stessa distanza, il cambiamento nell’immagine sarebbe molto meno evidente. Di conseguenza, stiamo generando un video “maschera” per concentrarci sulle aree rilevanti per la stima della posa, semplificando i nostri calcoli.
Ho preferito utilizzare Mask-RCNN per la segmentazione dei fotogrammi. Puoi usare anche altri modelli di segmentazione a tua scelta. Per il mio video, ho deciso di segmentare la persona a destra poiché rimane nel frame per l’intero video ed è abbastanza vicina alla telecamera.
Per generare il video della maschera, sono necessari alcuni aggiustamenti manuali specifici al tuo video. Poiché il mio video contiene due persone, ho iniziato segmentando le maschere per entrambe le persone. Successivamente, ho estratto la maschera per la persona a destra tramite codifica rigida. Il tuo approccio potrebbe variare a seconda dell’oggetto in primo piano che hai selezionato e della sua posizione all’interno del video. Lo script responsabile della creazione della maschera si trova in ./render_mask_video.py. La sezione dello script in cui specifico il processo di selezione della maschera è la seguente:
file_names = next(os.walk(IMAGE_DIR))[2] for index in tqdm(range(0, len(file_names))): image = skimage.io.imread(os.path.join(IMAGE_DIR, file_names[index])) # Esegui la rilevazione results = model.detect([image], verbose=0) r = results[0] # Nel prossimo ciclo for, controllo se il frame estratto è più grande di 16000 pixel, # e se si trova almeno al 250esimo pixel nell'asse orizzontale. # In caso contrario, controllo la maschera successiva con la maschera "persona". current_mask_selection = 0 while(True): if current_mask_selection<10: if (np.where(r["masks"][:,:,current_mask_selection]*1 == 1)[1].min()<250 or np.sum(r["masks"][:,:,current_mask_selection]*1)<16000): current_mask_selection = current_mask_selection+1 continue elif (np.sum(r["masks"][:,:,current_mask_selection]*1)>16000 and np.where(r["masks"][:,:,current_mask_selection]*1 == 1)[1].min()>250): break else: break mask = 255*(r["masks"][:,:,current_mask_selection]*1) mask_img = Image.fromarray(mask) mask_img = mask_img.convert('RGB') mask_img.save(os.path.join(SAVE_DIR, f"frame{index:03}.png"))Il video originale e il video della maschera sono visualizzati affiancati nell’animazione seguente:

Passaggio 3: Stimare la posa della fotocamera e i parametri intrinseci
Dopo aver creato i frame della maschera, procediamo ora con il calcolo della posa della fotocamera e la stima intrinseca. Per fare ciò, utilizziamo uno strumento chiamato Colmap. È uno strumento di stereovisione multi-vista che crea mesh da immagini multiple e stima anche i movimenti della fotocamera e gli intrinseci. Ha sia una GUI che un’interfaccia a riga di comando. Puoi scaricare lo strumento da questo link.
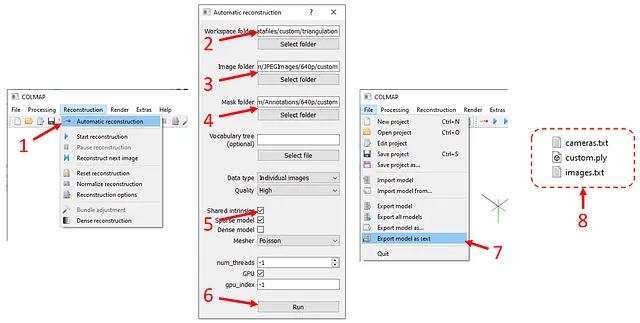
Una volta avviato lo strumento, premi “Reconstruction” nella barra superiore (vedi figura sotto), quindi “Automatic reconstruction”. Nella finestra di pop-up,
- inserisci
./datafiles/custom/triangulationper “Cartella di lavoro” - inserisci
./datafiles/custom/JPEGImages/640p/customper “Cartella immagini” - inserisci
./datafiles/custom/JPEGImages/640p/customper “Cartella immagini” - inserisci
./datafiles/custom/Annotations/640p/customper “Cartella maschere” - spunta l’opzione “Intrinseci condivisi”
- clicca su “Esegui”.
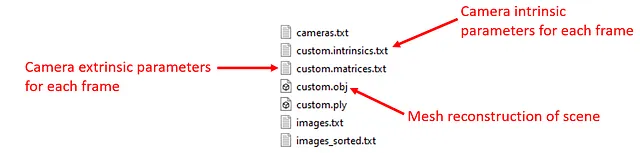
Il calcolo può richiedere del tempo a seconda del numero di immagini che hai e della risoluzione delle immagini. Una volta completato il calcolo, fai clic su “Esporta modello come testo” sotto “File” e salva i file di output in ./datafiles/custom/triangulation. Verranno creati due file di testo e un file mesh (.ply).
Questa fase non è ancora completa, dobbiamo elaborare gli output di Colmap. Ho scritto uno script per automatizzarlo. Semplicemente, esegui il seguente comando nel terminale:
python scripts/preprocess/custom/process_colmap_output.pyCreerà “custom.intrinsics.txt”, “custom.matrices.txt” e “custom.obj”.
Ora siamo pronti per procedere con la generazione del set di dati per l’addestramento.
Passo 4: Preparare il set di dati per l’addestramento
L’addestramento richiede un set di dati che consiste in stime di profondità di ciascun frame di MiDas, stime di flusso tra frame e sequenze di profondità. Gli script per crearli sono stati forniti nel repository originale, ho solo cambiato le directory di input e output. Eseguendo il comando qui sotto, tutti i file necessari verranno creati e posizionati nelle directory appropriate:
python scripts/preprocess/custom/generate_frame_midas.py &python scripts/preprocess/custom/generate_flows.py &python scripts/preprocess/custom/generate_sequence_midas.py Prima dell’addestramento, controlla se hai file .npz e .pt in datafiles/custom_processed/frames_midas/custom, datafiles/custom_processed/flow_pairs/custom e datafiles/custom_processed/sequences_select_pairs_midas/custom. Dopo la verifica, possiamo procedere con l’addestramento.
Passo 5: Addestramento
La parte di addestramento è semplice. Per addestrare la rete neurale con il tuo set di dati personalizzato, esegui semplicemente il seguente comando nel terminale:
python train.py --net scene_flow_motion_field ^ --dataset custom_sequence --track_id custom ^ --log_time --epoch_batches 2000 --epoch 10 ^ --lr 1e-6 --html_logger --vali_batches 150 ^ --batch_size 1 --optim adam --vis_batches_vali 1 ^ --vis_every_vali 1 --vis_every_train 1 ^ --vis_batches_train 1 --vis_at_start --gpu 0 ^ --save_net 1 --workers 1 --one_way ^ --loss_type l1 --l1_mul 0 --acc_mul 1 ^ --disp_mul 1 --warm_sf 5 --scene_lr_mul 1000 ^ --repeat 1 --flow_mul 1 --sf_mag_div 100 ^ --time_dependent --gaps 1,2,4,6,8 --midas ^ --use_disp --logdir 'logdir/' ^ --suffix 'track_{track_id}' ^ --force_overwriteDopo aver addestrato la rete neurale per 10 epoche, ho osservato che la perdita ha iniziato a saturarsi e, di conseguenza, ho deciso di non continuare l’addestramento per ulteriori epoche. Di seguito è mostrato il grafico della curva di perdita del mio addestramento:
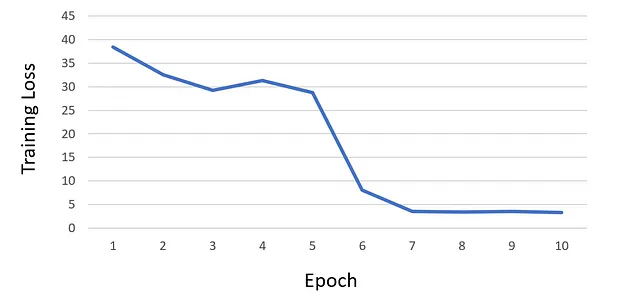
Durante l’addestramento, tutti i checkpoint vengono archiviati nella directory ./logdir/nets/. Inoltre, dopo ogni epoca, lo script di addestramento genera visualizzazioni di test nella directory ./logdir/visualize. Queste visualizzazioni possono essere particolarmente utili per identificare eventuali problemi che potrebbero essere occorsi durante l’addestramento, oltre al monitoraggio della perdita.
Passo 6: Creare le mappe di profondità di ciascun frame usando il modello addestrato
Utilizzando l’ultimo checkpoint, generiamo ora la mappa di profondità di ciascun frame con lo script test.py. Esegui semplicemente il seguente comando nel terminale:
python test.py --net scene_flow_motion_field ^ --dataset custom_sequence --workers 1 ^ --output_dir .\test_results\custom_sequence ^ --epoch 10 --html_logger --batch_size 1 ^ --gpu 0 --track_id custom --suffix custom ^ --checkpoint_path .\logdirQuesto genererà un file .npz per ogni frame (un file di dizionario composto da frame RGB, profondità, posizione della telecamera, flusso verso l’immagine successiva, e così via), e tre render di profondità (ground truth, MiDaS e stima della rete addestrata) per ogni frame.
Passaggio 7: Creazione di video di cloud di punti
Nell’ultimo passaggio, carichiamo i file .npz a lotti frame per frame e creiamo cloud di punti colorati utilizzando le informazioni di profondità e RGB. Utilizzo la libreria open3d per creare e renderizzare cloud di punti in Python. È uno strumento potente con cui è possibile creare telecamere virtuali nello spazio 3D e scattare foto delle cloud di punti con esse. È anche possibile modificare/manipolare le cloud di punti; ho applicato le funzioni di rimozione degli outlier integrate in open3d per rimuovere i punti sfocati e rumorosi.
Anche se non approfondirò i dettagli specifici del mio utilizzo di open3d per mantenere conciso questo post del blog, ho incluso lo script, render_pointcloud_video.py, che dovrebbe essere autoesplicativo. Se hai domande o hai bisogno di ulteriori chiarimenti, non esitare a chiedere.
Ecco come appaiono i video delle cloud di punti e delle mappe di profondità per il video che ho elaborato.

Una versione ad alta risoluzione di questa animazione è stata caricata su YouTube.
Beh, le mappe di profondità e le cloud di punti sono interessanti, ma potresti chiederti cosa puoi farci. Gli effetti basati sulla profondità possono essere notevolmente potenti rispetto ai metodi tradizionali di aggiunta di effetti. Ad esempio, il trattamento basato sulla profondità consente la creazione di vari effetti cinematografici altrimenti difficili da ottenere. Con la profondità stimata di un video, puoi incorporare in modo fluido fuoco e fuori fuoco della fotocamera sintetica, ottenendo un effetto bokeh realistico e coerente.
Inoltre, le tecniche basate sulla profondità offrono la possibilità di implementare effetti dinamici come il “dolly zoom”. Manipolando la posizione e gli intrinseci della telecamera virtuale, questo effetto può essere applicato per generare sequenze visive sbalorditive. Inoltre, l’inserimento di oggetti basato sulla profondità garantisce che gli oggetti virtuali siano fissati realisticamente nei video, mantenendo posizioni coerenti in tutte le scene.
La combinazione di mappe di profondità e cloud di punti libera un mondo di possibilità per una narrazione affascinante e effetti visivi immaginativi, spingendo il potenziale creativo di registi e artisti a nuove vette.
Subito dopo aver cliccato il pulsante “pubblica” di questo articolo, mi impegnerò a realizzare tali effetti.
Auguro una splendida giornata!





